Алгоритм написания изложения 9 класс
Подготовка к ОГЭ. Алгоритм написания изложения.
Сжатое изложение должно быть коротким по форме, но не бедным по содержанию. В изложение должно быть не менее 70 слов. В изложении нужно сохранить все микротемы исходного текста и не упустить основную мысль.
Последовательность работы при восприятии текста на слух
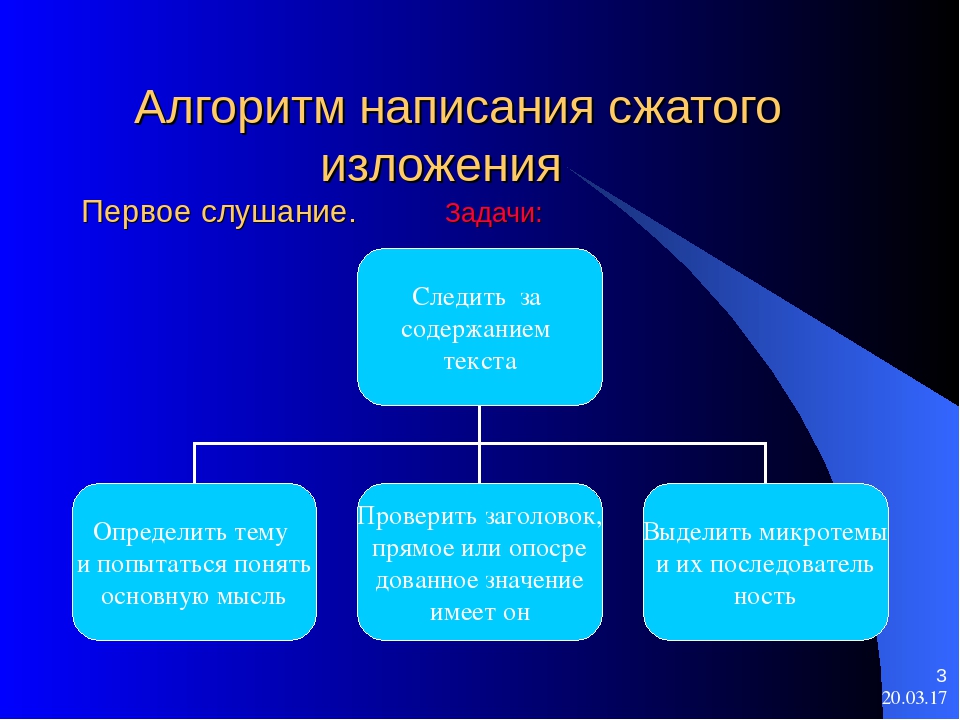
1. Прослушайте исходный текст.
2. Сформулируйте основную тему и идею текста ( о чем текст? что хотел сказать автор?
3. Зафиксируйте последовательность событий, рассуждений:
— в повествовании – начало событий, ход его, кульминация, развязка событий;
— в описании – предмет речи и его значимые, существенные признаки;
— в рассуждении – общие положения, аргументы, доказательства, вывод.
4. Составьте подробный план текста, выделяя микротемы каждой части текста.
5. Выберите способы сжатия текста. Используйте все известные Вам приемы сжатия.
6. Сократите текст, сохраняя главную информацию и все микротемы.
7. Проверьте смысловую и грамматическую связь между частями изложения.
8. Напишите сжатое изложение.
9. Перечитайте полученный текст и посчитайте количество слов.
10. Тщательно проверьте текст на наличие грамматических, речевых, орфографических и пунктуационных ошибок.
Основные приемы компрессии (сжатия) текста
1. Исключение:
— повторов;
— одного или нескольких синонимов;
— однородных членов;
— уточняющих и поясняющих конструкций;
— второстепенной, несущественной информации.
2. Обобщение:
— замена однородных членов обобщающим наименованием;
— замена предложения или его части определительным или отрицательным местоимением с обобщающим значением.
3. Упрощение (или сочетание исключения и обобщения):
— слияние нескольких предложений в одно;
— замена предложения или его части указательным местоимением;
— замена сложноподчиненного предложения простым;
— замена прямой речи косвенной.
4. Слияние:
— двух простых предложений или сложного и простого.
В результате сжатия должен получиться связный, логичный сокращенный текст, а не план или подробный пересказ.
Алгоритм написания сжатого изложения. ОГЭ. Задание 1
1. ОГЭ. Задание № 1. Сжатое изложение.
10 необходимых шагов. Алгоритмнаписания.
Изложение — вид работы, в основе которого
лежит устный или письменный пересказ
исходного текста.
Сжатое изложение — это краткая, обобщенная
передача содержания исходного текста.
В
сжатом изложении необходимо максимально
отразить содержание первоначального текста,
минимально используя речевые средства.
1. Прослушайте текст. Во время первого
прослушивания начинайте сразу делать
внимание на более длительные паузы –
это абзацы! Помните: в тексте – 3
микротемы, т.е. 3 абзаца.
2. Прослушивая текст второй раз,
записывайте ключевые слова и фразы.

3. Работая над восстановлением текста,
отметьте в нем существенное и
подробности в каждой части.
4. Определите способы сокращения текста
(исключение, обобщение, упрощение),
которые необходимо применить в каждом
абзаце (один любой способ, но в каждом
абзаце!)
5. Напишите сжатое изложение каждой части,
свяжите их между собой, чтобы получился
текст. Учитывайте смысловые связи между
эпизодами (логические, временные,
пространственные и т.п.).
6. Пересчитайте слова (пусть будет около 90
слов – не менее!)
7. Отредактируйте изложение (проверьте на
наличие ошибок).
10. Перепишите аккуратно в бланк (помните:
все буквы и знаки препинания должны
четкими, не вызывающими сомнений у
проверяющего эксперта)
8. Помните о главных условиях:
• 1. Вы должны передать содержаниеи(основную мысль) как каждой микротемы,
так и всего текста в целом.
• 2. Вы должны применить хотя бы один
способ сжатия в каждом абзаце.

• 3. Объём изложения – не менее 70 слов.
9. Критерии оценивания
КритерииКритерии оценивания сжатого изложения
ИК1
Содержание изложения
Баллы
Экзаменуемый точно передал основное содержание
прослушанного
текста, отразив все важные для его
восприятия микротемы
2
Экзаменуемый
передал
основное
содержание
прослушанного текста,
но
упустил или добавил одну микротему
1
Экзаменуемый
передал
основное
содержание
прослушанного текста,
но
упустил или
добавил более одной микротемы
0
Критерии
ИК2
Сжатие исходного текста
Баллы
Экзаменуемый применил один или несколько приёмов
сжатия текста, использовав их на протяжении всего текста
3
Экзаменуемый применил один или несколько приёмов
сжатия текста, использовав их
для сжатия двух микротем
текста
2
Экзаменуемый применил один или несколько приёмов
сжатия текста, использовав их для сжатия одной
микро
темы текста
1
Экзаменуемый не использовал приёмов сжатия текста
0
11.
 Критерии оценивания Критерии
Критерии оценивания КритерииКритерии оценивания сжатого изложения
ИК3
Смысловая цельность, речевая связность и
последовательность изложения
Баллы
Работа экзаменуемого характеризуется смысловой
цельностью, речевой связностью и последовательностью
изложения:
– логические ошибки отсутствуют, последовательность
изложения не нарушена;
– в работе нет нарушений абзацного членения текста
2
Работа экзаменуемого характеризуется смысловой
цельностью, связностью и последовательностью
изложения, но допущена одна логическая ошибка,
и/или в работе имеется одно нарушение абзацного
членения текста
1
В работе экзаменуемого просматривается
коммуникативный замысел, но
допущено более одной логической ошибки,
и/или имеется два случая нарушения абзацного членения
текста
0
12. Максимальное количество баллов за сжатое изложение по критериям ИК1–ИК3
713. Микротемы
Микротема — содержание несколькихпредложений, объединенных одной
мыслью.
 Микротема является частью общей темы
Микротема является частью общей темытекста и, как правило, представляет собой
отдельный абзац (или несколько). В тексте сжатого
изложения следует отметить все микротемы
исходного текста, иначе оценка будет снижена.
В процессе прослушивания текста необходимо
мысленно разделить его на составляющие части —
микротемы.
Сайт Тамары Ивановны Смирновой — Сжатое изложение
Сжатое изложение текста – это краткий пересказ его основного содержания, в котором необходимо сохранить самое важное: основную мысль, художественные детали и языковые особенности.
При написании сжатого изложения на ГИА необходимо передать главное содержание каждой микротемы и всего текста в целом, сохраняя смысловую последовательность.
Микротема – тема каждой смысловой
части текста, которая отражает часть общей темы, единой для всего текста.
Основные рекомендации:
Как слушать текст первый раз.
Во время первого чтения внимательно и сосредоточенно слушайте текст, выделяйте самое важное, мысленно делите его на смысловые части, чтобы понять, о чем говорится в каждой из них. Определите общую тему текста, его основную мысль
Обратите внимание на опорные слова, на особенности повествования автора: какие слова являются определяющими, как в них отражается индивидуальный стиль автора.
Писать во время первого прослушивания текста не рекомендуется.
После прочтения можно записать на черновике ключевые слова, оставляя между ними большие расстояния, чтобы позже дополнить свои записи.
Составьте подробный план текста,
выделите микротемы каждой части и озаглавьте их. Запишите названия пунктов
плана, оставляя место для записи опорных слов.
Запишите названия пунктов
плана, оставляя место для записи опорных слов.
Слушая
текст второй раз,
После второго чтения текста напишите черновой вариант сжатого изложения в соответствии с выделенными микротемами по отработанной схеме. Проверьте взаимосвязь микротем в частях текста.
Перечитайте текст, при необходимости подумайте над тем, что можно ещё сократить. Сделайте окончательные исправления и дополнения. Проверьте черновик два раза.
Перепишите сжатое изложение в чистовик. Проверьте не менее двух раз.
Краткий алгоритм написания сжатого изложения:
1) делим текст на части;
2) выделяем те предложения, без которых нельзя обойтись, отсутствие которых приведёт к искажению смысла или его непониманию;
3) опускаем несущественный материал, без которого можно обойтись, отсутствие которого не отразится на понимании смысла текста;4) при необходимости
перестраиваем некоторые предложения: из нескольких предложений составляем одно
(то есть сжать их).
Приемы сжатия текста:
1. Исключение второстепенной информации (подробностей, деталей, уточнений, пояснений и пр.).
2. Упрощение синтаксических конструкций.
3. Обобщение единичных явлений и фактов, перевод частного в общее.
К
основным языковым приемам исключения относятся:
1. Исключение повторов;
2. Исключение фрагмента предложения;
3. Исключение одного или нескольких синонимов.
4. Слияние нескольких предложений в
одно (синтаксис предложения).
Языковые приемы обобщения:
1. Замена однородных членов обобщающим наименованием;
2. Замена фрагмента предложения синонимичным выражением;
3. Замена предложения или его части указательным местоимением;
4. Замена предложения или его части определительным или отрицательным местоимением с обобщающим значением;
5. Замена СПП простым.
Сжатое изложение алгоритм написания приемы сжатия Алгоритм
Сжатое изложение алгоритм написания, приемы сжатия
Алгоритм написания сжатого изложения 1. Выделение микротем (составление плана). 2. Выделение ключевых слов и понятий. 3. Установление смысловых связей между ключевыми словами и понятиями. 4. Собственно сжатие текста (приёмы сжатия).
Смысловое сжатие текста предполагает: 1. сохранение последовательности в развитии событий; 2. наличие предложений, выражающих мысль для каждой смысловой части; 3. использование грамматических форм, отличных от авторских; 4. установление смысловой связи между предложениями; 5. использование уместных языковых средств.
Основные приемы сжатия текста 1. Исключение 2. Обобщение 3. Упрощение
Исключение • сокращение отдельных членов предложения, некоторых однородных членов предложения У каждого, заходившего в комнату к малышам, на лице появлялась радостная, светлая, приветливая улыбка. (У каждого, заходившего в комнату к малышам, на лице появлялась приветливая улыбка. )
• сокращение сложного предложения за счет менее существенной части У природы как целого, как единого творца есть свои любимцы, в которые она при строительстве вкладывает с особенным тщанием и наделяет особенной властью. (У природы есть свои любимцы, которых она наделяет особой властью. )
(У природы есть свои любимцы, которых она наделяет особой властью. )
• пропуск предложений с описаниями и рассуждениями Не будем сейчас говорить о его богатствах, это отдельный разговор. Байкал славен и свят другим – своей чудесной животворной силой, духом не былого, не прошедшего, как многое ныне, а настоящего, не подвластного времени и преобразованиям, исконного величия и заповедного могущества, духом самородной воли и притягательных испытаний. (Байкал славен не только своими природными богатствами. Он велик своей чудесной животворящей силой. )
Обобщение • сокращение несущественных деталей Жители посёлка проводят свой досуг по-разному. Кто-то предпочитает перечитывать любимые с детства жюль-верновский романы; кто-то проводит много времени на реке или в лесу. Основное занятие подростков – спортивные игры и соревнования. Самым запоминающимся событием был прошлогодний велокросс. (Жители посёлка проводят свой досуг поразному, в зависимости от вкусов и привычек.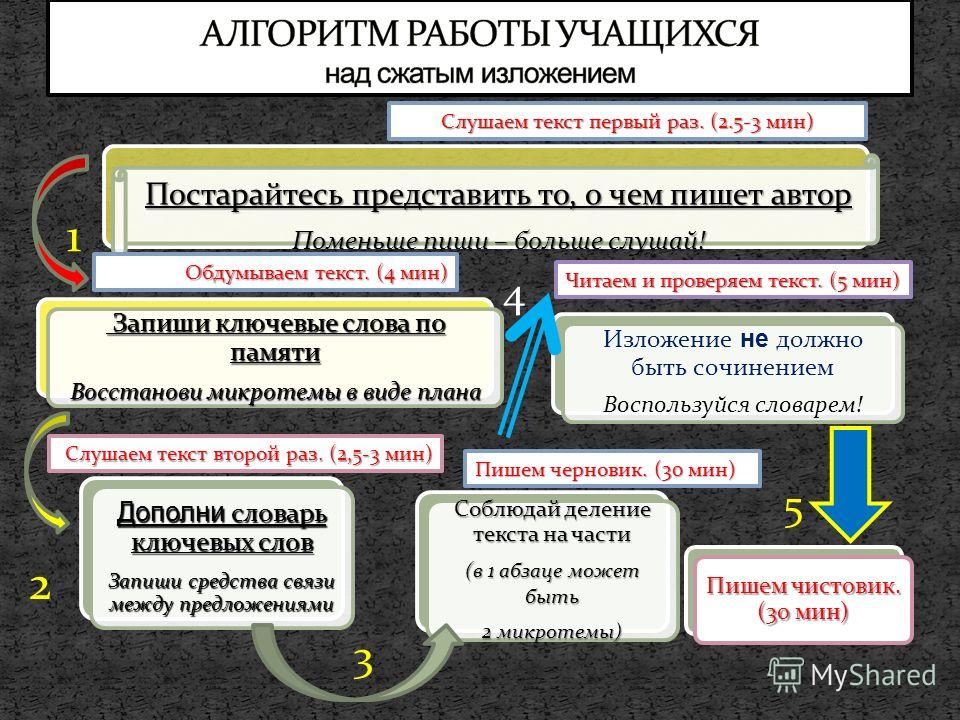 )
)
Он знал разные языки: немецкий, французский, итальянский и молдавский, и никто не мог распознать в нём русского. (Он знал разные языки, и никто не мог распознать в нём русского. )
• образование сложного предложения путем слияния двух смежных предложений, повествующих об одном и том же предмете речи Таков, вне всякого сомнения, Байкал. Не зря его называют жемчужиной Сибири. (Таков Байкал – жемчужина Сибири. )
Упрощение • замена придаточного определительного синонимичным определением Небольшое помещение на втором этаже занимает фирма, которая предлагает своим клиентам туры по всем континентам и странам. (Небольшое помещение на втором этаже занимает туристическая фирма. )
• замена придаточного обстоятельственного деепричастным оборотом Когда читаешь дневник Никитина, то чувствуешь его беспредельную любовь к родине. (Читая дневник Никитина, чувствуешь его беспредельную любовь к родине. )
)
• сокращение количества структурных частей сложного предложения Приятно смотреть на зимородка, который, плавно опустившись на ветку ольхи, склонившуюся к самому зеркалу реки, принялся подкарауливать добычу. (Приятно смотреть на зимородка, который плавно опустился на ветку ольхи и принялся подкарауливать добычу. )
• замена предложения или его части указательным местоимением, слияние двух или трёх предложений в одно Например, мы мечтаем съездить в далёкую страну и огорчаемся, что не можем сделать этого прямо сейчас. Время идёт, и мы постепенно всё больше узнаём о том, что так притягивает нас. Может быть, мы даже решаем связать свою профессию с путешествиями или занимаемся изучением нужного нам языка. И когда мечта осуществляется, мы понимаем, что она действительно наполнила нашу жизнь содержанием и смыслом на много лет. Она сделала нас любознательнее, серьёзнее, интереснее. Благодаря мечте мы сами стали добрее и лучше. (Идя к своей мечте, человек на много лет наполняет свою жизнь содержанием и становится намного лучше и добрее. )
(Идя к своей мечте, человек на много лет наполняет свою жизнь содержанием и становится намного лучше и добрее. )
• перевод прямой речи в косвенную Я даю это ничего не значащее само по себе воспоминание для того лишь, чтобы иметь возможность процитировать несколько слов из большого и восторженного письма моего товарища, которое он послал мне вскоре после возвращения домой с Байкала. «Силы прибавились – это ладно, это бывало, — писал он. – Но я теперь духом поднялся, который оттуда, с Байкала. Я теперь чувствую, что могу немало сделать, и, кажется, различаю, что нужно делать и чего не нужно. Как хорошо, что у нас есть Байкал! Я поднимаюсь утром и, поклоняясь в вашу сторону, где батюшка-Байкал, начинаю горы ворочать…» (Вскоре друг прислал мне восторженное письмо, в котором писал о том, что после поездки на Байкал у него силы прибавились, он духом поднялся, может немало сделать в жизни. )
Как правильно писать изложение в 9 классе.
 ОГЭ 2020.
ОГЭ 2020. Какие задачи стоят перед учеником
В процессе написания подобных работ человек формирует множество важных навыков не только с точки зрения уроков по русскому языку или литературе, но и в целом для своего успешного развития как личности.
В частности, ребенок учится:
- воспринимать информацию и концентрироваться на ней;
- писать логически стройные и последовательные тексты;
- анализировать информацию;
- выделять основные мысли рассказов;
- воспринимать и соблюдать те или иные особенности стиля речи;
- запоминать большие объемы информации.
Поэтому во время работы над изложением важно, чтобы ребенок был сконцентрирован на внимательном прослушивании произведения и мог беспрепятственно воспринимать ключевые мысли.
Фокус на главном!
Изложения в школе пишут в каждом классе, поэтому часто школьники считают, что здесь проблем возникнуть просто не может. С одной стороны, тренировка всегда помогает, с другой – есть несколько моментов, на которые имеет смысл обратить пристальное внимание.
На экзамене в первом задании требуется написать сжатое изложение.
При сжатом изложении не нужен подробный пересказ текста. От школьника требуется другой важный навык – понять основное содержание и ключевые моменты, поддерживающие главную мысль. Все остальное не только можно, но и нужно опустить.
Чем меньше вы растекаетесь мыслью по древу, чем четче формулируете, тем лучше. Главное в формате сжатого изложения – ясно передать ядро текста с авторскими аргументами и примерами (их называют микротемами). Вот именно в этом направлении и нужна тренировка. Тексты для прослушивания есть в открытом доступе на сайте ФИПИ. Как же с ними работать?
Виды изложения
Изложения бывают нескольких видов. Но прежде, чем перейти к этому вопросу, важно обозначить, какие существуют типы текстов вообще.
Повествование
Этот вид текста представляет собой последовательный пересказ каких-либо событий. Грубо говоря, повествование является рассказом, в котором присутствует сюжет и события логически следуют одно за другим.
С точки зрения построения, этот тип текста является самым простым, и именно их учителя берут в качестве первого опыта написания как изложений, так и сочинений.
Описание
В этих текстах упор автора идет на то, чтобы дать словесный портрет какого-либо человека, описать пейзаж, явление и тому подобное. В развитии детей изложения-описания являются следующим после повествования шагом.
Если в случае с повествованием не составляет особого труда по памяти воспроизвести ход событий, то у описаний структура несколько свободнее. Кроме того, тексты-описания насыщены различными эпитетами, что затрудняет запоминание.
Рассуждение
Самый непростой вид текстов, в том числе для изложений. Здесь важно обратить внимание, как автор выдвигает суждение и, подкрепляя свое мнение примерами, доказывает его и делает вывод. Этим рассуждение сильно отличается от других типов текста.
Сложность составляет определение учащимся главной мысли автора. Кроме того, в текстах-рассуждениях очень много риторических размышлений, различных умозаключений, сравнений. Такие тексты пишут ученики старших классов.
Такие тексты пишут ученики старших классов.
Итак, по форме текста изложения можно поделить на изложения-повествования, изложения-описания и изложения-рассуждения. При этом редко текст представляет собой чистую форму того или иного типа. Обычно это синтез двух, а то и сразу трех форм, например, повествование с элементами описания и рассуждения.
По размеру конечного результата изложения также делят на следующие виды:
- подробное
– то есть максимально приближенное к исходному тексту с сохранением характерного стиля автора;
- краткое
– здесь задачей учащегося является передача только главного смысла рассказа;
- выборочное
– изложение только заданного учителем фрагмента.
Пример сжатия текста
Рассмотрим в качестве текста для сжатого изложения фрагмент статьи Д. С. Лихачёва «Цель и самооценка».
Исходный текст:
Когда человек сознательно или интуитивно выбирает себе в жизни какую-то цель, жизненную задачу, он вместе с тем невольно дает себе оценку.
По тому, ради чего человек живет, можно судить и о его самооценке – низкой или высокой. Если человек ставит перед собой задачу приобрести все элементарные жизненные блага, он и оценивает себя на уровне этих материальных благ: как владельца машины последней марки, как хозяина роскошной дачи, как часть своего мебельного гарнитура… Если человек живет, чтобы приносить людям добро, облегчать их страдания при болезнях, давать людям радость, то он оценивает себя на уровне своей человечности. Он ставит перед собой цель, достойную человека.
Только сверхличная цель позволяет человеку прожить свою жизнь с достоинством и получить настоящую радость. Да, радость! Подумайте: если человек ставит себе задачей увеличивать в жизни добро, приносить людям счастье, – какие неудачи могут его постигнуть! Не тому помог, кому следовало бы? Но много ли людей не нуждаются в помощи. Если ты врач, то, может быть, поставил больному неправильный диагноз? Такое бывает и у самых лучших врачей. Но в сумме ты помог все-таки больше, чем не помог.
Ставя себе задачей карьеру или приобретательство, человек испытывает гораздо больше огорчений, чем радостей, и рискует потерять все. А что может потерять человек, который радовался каждому своему доброму делу? Важно только, чтобы добро, которое человек делает, было бы его внутренней потребностью, шло от сердца, а не только от головы, не было бы «принципом», лишенным чувства доброты. Поэтому главной жизненной задачей должна быть обязательно задача сверхличностная, а не эгоистичная. Она должна диктоваться добротой к людям, любовью к семье, к своему городу, к своему народу, к своей стране, к ее великому прошлому, ко всему человечеству.
 По тому, ради чего человек живет, можно судить и о его самооценке – низкой или высокой. Если человек ставит перед собой задачу приобрести все элементарные жизненные блага, он и оценивает себя на уровне этих материальных благ: как владельца машины последней марки, как хозяина роскошной дачи, как часть своего мебельного гарнитура… Если человек живет, чтобы приносить людям добро, облегчать их страдания при болезнях, давать людям радость, то он оценивает себя на уровне своей человечности. Он ставит перед собой цель, достойную человека.
По тому, ради чего человек живет, можно судить и о его самооценке – низкой или высокой. Если человек ставит перед собой задачу приобрести все элементарные жизненные блага, он и оценивает себя на уровне этих материальных благ: как владельца машины последней марки, как хозяина роскошной дачи, как часть своего мебельного гарнитура… Если человек живет, чтобы приносить людям добро, облегчать их страдания при болезнях, давать людям радость, то он оценивает себя на уровне своей человечности. Он ставит перед собой цель, достойную человека. От ошибок никто не застрахован. Но самая главная ошибка, ошибка роковая – неправильно выбранная главная задача в жизни. Не повысили в должности – огорченье. У кого-то лучшая мебель или лучшая машина – тоже огорченье, и еще какое!
От ошибок никто не застрахован. Но самая главная ошибка, ошибка роковая – неправильно выбранная главная задача в жизни. Не повысили в должности – огорченье. У кого-то лучшая мебель или лучшая машина – тоже огорченье, и еще какое!Использование приемов компрессии
Фрагмент состоит из трёх абзацев-микротем, которые можно озаглавить следующим образом:
- Жизненная цель – самооценка человека.
- Сверхличная цель позволяет человеку прожить жизнь достойно.
- Главной жизненной задачей должна быть сверхличностная, диктуемая добротой и любовью.

1-ый абзац: Используя исключение и замену, получаем:
Когда человек выбирает себе в жизни цель, он вместе с тем дает себе оценку. Если человек ставит перед собой задачу приобрести все элементарные жизненные блага, он и оценивает себя на их уровне. Если человек живет, чтобы приносить людям добро, то он оценивает себя на уровне своей человечности. Это цель, достойная человека.
2-ой абзац: В результате компрессии методом исключения получаем:
Только сверхличная цель позволяет человеку прожить свою жизнь с достоинством. Если человек ставит себе задачей увеличивать в жизни добро, какие неудачи могут его постигнуть? От ошибок никто не застрахован. Но самая главная ошибка – неправильно выбранная главная задача в жизни.
3-ий абзац: В этом абзаце самая важная информация, поэтому большую часть оставляем, в начале абзаца используем слияние, последнее предложение сокращаем путём замены и исключения:
Ставя себе задачей карьеру или приобретательство, человек испытывает больше огорчений, чем радостей, в отличие от человека, который радовался каждому своему доброму делу. Важно только, чтобы добро, которое человек делает, шло от сердца. Поэтому главной жизненной задачей должна быть задача сверхличностная, а не эгоистичная. Она должна диктоваться добротой и любовью.
Важно только, чтобы добро, которое человек делает, шло от сердца. Поэтому главной жизненной задачей должна быть задача сверхличностная, а не эгоистичная. Она должна диктоваться добротой и любовью.
Сжатое изложение:
Когда человек выбирает себе в жизни цель, он вместе с тем дает себе оценку. Если человек ставит перед собой задачу приобрести все элементарные жизненные блага, он и оценивает себя на их уровне. Если человек живет, чтобы приносить людям добро, то он оценивает себя на уровне своей человечности. Это цель, достойная человека.
Только сверхличная цель позволяет человеку прожить свою жизнь с достоинством. Если человек ставит себе задачей увеличивать в жизни добро, какие неудачи могут его постигнуть? От ошибок никто не застрахован. Но самая главная ошибка – неправильно выбранная главная задача в жизни.
Ставя себе задачей карьеру или приобретательство, человек испытывает больше огорчений, чем радостей, в отличие от человека, который радовался каждому своему доброму делу. Важно только, чтобы добро, которое человек делает, шло от сердца. Поэтому главной жизненной задачей должна быть задача сверхличностная, а не эгоистичная. Она должна диктоваться добротой и любовью.
Важно только, чтобы добро, которое человек делает, шло от сердца. Поэтому главной жизненной задачей должна быть задача сверхличностная, а не эгоистичная. Она должна диктоваться добротой и любовью.
Основные правила написания изложений
При написании изложений следует опираться на следующий алгоритм действий:
- Определить тип текста – повествование, описание, рассуждение.
- Определить стиль текста – деловой, научный, публицистический, художественный.
- Выявить особенности авторского стиля, будь то сложные предложения, инверсивный порядок слов в предложениях или обилие риторических конструкций.
- Выявить главную мысль текста.
- Определить второстепенные мысли и фрагменты текста.
- Грамотно составить план изложения.
Как составить план изложения
Для того, чтобы написать план изложения, при первом прослушивании текста необходимо мысленно разбить текст на три составляющие: вступление, основную часть и заключение.
Основную часть, как правило, можно разбить еще на два и более пунктов.
Пример плана изложения
Каждый получившийся смысловой пункт плана следует озаглавить. Делать это лучше при помощи тезисов, а не кратких заголовков – так учащийся значительно повысит вероятность в подробностях вспомнить, о чем был тот или иной фрагмент текста.
Как только план составлен, текст воспроизводится во второй раз. Здесь ученику важно выделить главные мысли каждого из пунктов и законспектировать смысловые куски: слова и фразы, которые имеют наибольшее значение для раскрытия данного фрагмента.
Как писать сжатое изложение
При написании сжатого изложения ученику предстоит передать смысл текста и сжать его объем примерно на одну треть. В данной работе ценится умение ребенка вычленить из рассказа главную мысль и донести ее, не меняя местами фрагменты и сохраняя авторский стиль.
Следующая памятка поможет ребенку овладеть техникой написания кратких изложений:
- Определить главную мысль в тексте, отбросить второстепенное.
- Вычленить микротемы (абзацы или смысловые фрагменты) и составить план.
- Избавиться от малозначительных деталей: лирических отступлений, риторических конструкций.
- Обобщить материал: некоторые эпизоды текста можно передать одним предложением.
- Упростить языковые конструкции: заменить сложные предложения простыми, убрать однородные члены и синонимичные конструкции, повторы, прямую речь.

Ни в коем случае нельзя менять местами микротемы, делать второстепенные фрагменты центральными и менять авторский стиль.
Это может существенно отразиться на итоговой оценке за изложение.
Как научиться быстро писать изложение по аудиозаписи
Этот вопрос особенно актуален для учащихся девятых и одиннадцатых классов, которым предстоит сдача государственных экзаменов. Основная сложность написания изложений по аудио заключается в том, что запись невозможно «попросить» повторить фрагмент или читать медленнее, и ученику приходится подстраиваться под обычно неторопливый, но все-таки достаточно бодрый темп диктора.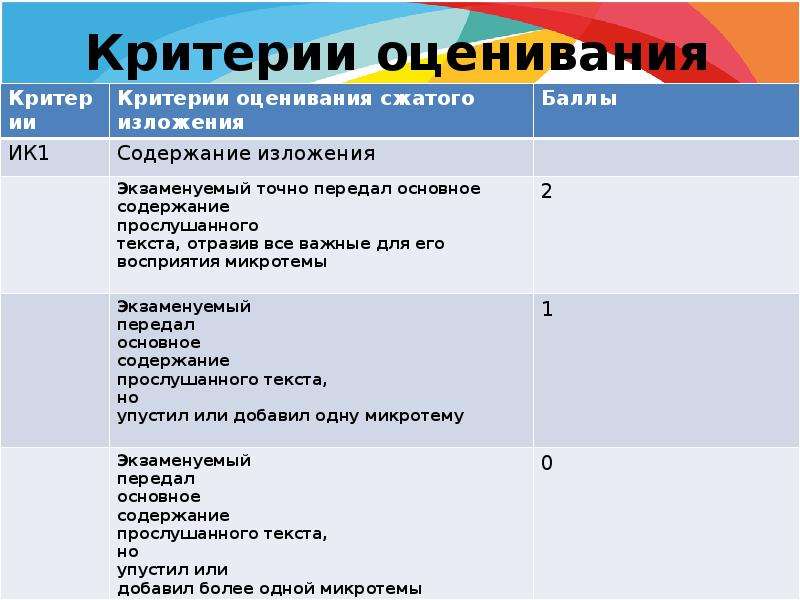
Для того, чтобы научить ребенка писать изложение по аудиозаписи, необходимо предоставить ему очень много практики. Здесь придется проявить настойчивость – из-за большого количества требований дети не любят этот вид работы.
Писать изложения можно не только с помощью специально озвученных квалифицированными педагогами текстов для тренировки перед экзаменами, но и прослушивая, например, подкасты, новости или аудиокниги.
Во время прослушивания аудиозаписи очень важно писать конспект.
При этом ученику нужно не бояться делать большие отступы между тезисами: при втором прослушивании в них будет удобно вписывать дополнительную, пропущенную при первом прослушивании, информацию.
Проверяем себя
Уровень грамотности во время экзамена также оценивается, а баллы за ошибки снижают. Но вы пишете не диктант, а изложение, этот формат работает на вас. При любых сомнениях в написании слова вспоминайте синонимы. Меняйте слова, словосочетания, даже предложения, если не уверены в правильности орфографии и пунктуации. В изложении важно не использование точных авторских слов, а передача смысла.
В изложении важно не использование точных авторских слов, а передача смысла.
Но помните, что писать телеграфным стилем позволено или Хэмингуэю, или ученику начальной школы. От девятиклассника все же ждут развернутых предложений, поэтому не нужно хитрить в надежде избежать ошибок, это может обернуться против вас.
| Критерии оценивания сжатого изложения | ||
| Содержание изложения | ||
| Экзаменуемый точно передал основное содержание прослушанного текста, отразив все важные для его восприятия микротемы. | ||
Экзаменуемый
передал основное содержание прослушанного текста, но упустил
или добавил 1 микротему. | ||
| Экзаменуемый передал основное содержание прослушанного текста, но упустил или добавил более 1 микротемы. | ||
| Сжатие исходного текста | ||
| Экзаменуемый применил 1 или несколько приёмов сжатия текста, использовав их на протяжении всего текста. | ||
| Экзаменуемый применил 1 или несколько приёмов сжатия текста, использовав их для сжатия 2 микротем текста. | ||
| Экзаменуемый применил 1 или несколько приёмов сжатия текста, использовав их для сжатия 1 микротемы текста. | ||
| Экзаменуемый не использовал приёмов сжатия текста. | ||
| Смысловая цельность, речевая связность и последовательность изложения | ||
| Работа
экзаменуемого характеризуется смысловой цельностью, речевой связностью и
последовательностью изложения: • логические ошибки отсутствуют, последовательность изложения не нарушена; • в работе нет нарушений абзацного членения текста.  | ||
| Работа экзаменуемого характеризуется смысловой цельностью, связностью и последовательностью изложения, но допущена 1 логическая ошибка, и/или в работе имеется 1 нарушение абзацного членения текста. | ||
| В работе экзаменуемого просматривается коммуникативный замысел, но допущено более 1 логической ошибки, и/или имеются 2 случая нарушения абзацного членения текста. | ||
| Максимальное количество баллов за сжатое изложение по критериям ИК1-ИКЗ | ||
Информация о тексте для сжатого изложения — Энциклопедия современных знаний
| № абзаца | Микротемы |
Одной из вечных ценностей, которые имеют большое значение для людей всех поколений и культур, является дружба. | |
| Дружба – это взаимоотношения, основанные на открытости, доверии и готовности прийти друг другу на помощь. | |
| У друзей одинаковые жизненные ценности, духовные ориентиры. Постоянство – отличительная черта настоящей дружбы. |
Текст № 5
Неуверенность в себе — проблема древняя, однако она привлекла внимание медиков, педагогов и психологов сравнительно недавно — в середине XX века. Именно тогда стало понятно: всё усиливающаяся неуверенность в себе может стать причиной массы неприятностей — вплоть до серьёзных заболеваний, не говоря уже о житейских проблемах.
А проблемы психологические? Ведь неуверенность в себе может послужить почвой постоянной зависимости от чужого мнения. Представим себе, как неудобно чувствует себя зависимый: чужие оценки кажутся ему гораздо более важными и значимыми, чем собственные; каждый свой поступок он видит прежде всего глазами окружающих. А главное, ему хочется одобрения ото всех, начиная с близких и заканчивая пассажирами в трамвае. Такой человек становится нерешительным и не может правильно оценить жизненную ситуацию,
Такой человек становится нерешительным и не может правильно оценить жизненную ситуацию,
Как же преодолеть неуверенность в себе? Одни учёные ищут ответ на этот вопрос, основываясь на физиологических процессах, другие опираются на психологию. Ясно одно: преодолеть неуверенность в себе можно лишь в случае, если человек способен правильно ставить цели, соотносить их с внешними обстоятельствами и позитивно оценивать свои результаты.
| Информация о тексте для сжатого изложения | |
| № абзаца | Микротемы |
| Неуверенность в себе может стать причиной многих неприятностей. | |
| Человек, не уверенный в себе, постоянно зависит от чужого мнения, и поэтому он становится нерешительным и не может использовать жизненные ситуации в своих интересах. | |
Существует несколько мнений на вопрос: как преодолеть неуверенность в себе. Но все сходятся в одном: только человек, способный позитивно оценивать свои результаты, способен преодолеть неуверенность в себе. |
Текст № 6
Времена меняются, приходят новые поколения, у которых, казалось бы, всё не такое, как у прежних: вкусы, интересы, жизненные цели. Но трудноразрешимые личные вопросы между тем почему-то остаются неизменными. Нынешних подростков, как и их родителей в свое время, волнует все то же: как обратить на себя внимание того, кто тебе нравится? Как отличить увлечение от настоящей любви?
Юношеская мечта о любви – это, что бы ни говорили, прежде всего, мечта о взаимопонимании. Ведь подростку обязательно нужно реализовать себя в общении со сверстниками: проявить свою способность к сочувствию, сопереживанию. Да и просто показать свои качества и способности перед тем, кто настроен к нему доброжелательно, кто готов его понять.
Любовь — это безусловное и безграничное доверие двоих друг к другу. Доверие, которое раскрывает в каждом все то лучшее, на что только способна личность. Настоящая любовь непременно включает в себя дружеские отношения, но не ограничивается ими. Она всегда больше дружбы, поскольку только в любви мы признаем за другим человеком полное право на все то, что составляет наш мир.
Она всегда больше дружбы, поскольку только в любви мы признаем за другим человеком полное право на все то, что составляет наш мир.
Информация о тексте для сжатого изложения
| № абзаца | Микротема |
| Жизненные представления у разных поколений различны, но, поскольку психология человека меняется медленно, трудноразрешимые вопросы о любви остаются прежними. | |
| Для подростка мечта о любви связана прежде всего с потребностью быть понятым сверстниками, проявить перед ними свои качества и способности. | |
| Любовь больше дружбы, она предполагает полное взаимное доверие, раскрывающее все лучшие свойства личности. |
Текст № 7
У каждого из нас когда-то были любимые игрушки. Пожалуй, у каждого человека есть связанное с ними светлое и нежное воспоминание, которое он бережно хранит в своем сердце. Любимая игрушка – это самое яркое воспоминание из детства каждого человека.
В век компьютерных технологий реальные игрушки уже не привлекают к себе такого внимания, как виртуальные. Но несмотря на все появляющиеся новинки, такие как телефоны и компьютерная техника, игрушка все-таки остается неповторимой и незаменимой в своем роде, ведь ничто так не учит и не развивает ребенка, как игрушка, с которой он может общаться, играть и даже приобретать жизненный опыт.
Игрушка – это ключ к сознанию маленького человека. Чтобы развить и укрепить в нем положительные качества, сделать его психически здоровым, привить любовь к окружающим, сформировать правильное понимание добра и зла, необходимо тщательно выбирать игрушку, помня, что она принесет в его мир не только свой образ, но и поведение, атрибуты, а также систему ценностей и мировоззрение. Невозможно воспитать полноценного человека с помощью игрушек негативной направленности.
Сжатое изложение.
У каждого из нас когда-то были любимые игрушки. Любимая игрушка — это самое яркое воспоминание из детства каждого человека.
В век компьютерных технологий игрушка все-таки остается неповторимой и незаменимой, общаясь с ней, ребенок учится общаться, играть и даже приобретать жизненный опыт.
Игрушка — это ключ к сознанию маленького человека. Но чтобы развить и укрепить в ребенке положительные качества, нужно правильно выбирать игрушку, так как она принесет в его мир не только свой образ, но систему ценностей и мировоззрение. Невозможно воспитать полноценного человека с помощью игрушек негативной направленности. (86 слов)
Текст № 8
Какой бы интересной ни была домашняя и школьная жизнь ребенка, не прочти он драгоценных книг – он обделён. Такие утраты невосполнимы. Это взрослые могут прочесть книжку сегодня или через год – разница невелика. В детстве счет времени ведется иначе, тут каждый день – открытия. И острота восприятия в дни детства тако-ва, что ранние впечатления могут влиять потом на всю жизнь. Впечатления детства – самые яркие и прочные впечатления. Это фундамент будущей духовной жизни, золотой фонд.
В детстве посеяны семена. Не все прорастут, не все расцветут. Но биография человеческой души – это постепенное прорастание семян, посеянных в детстве.
Последующая жизнь сложна и многообразна. Она состоит из миллионов поступ-ков, определяющихся многими чертами характера и, в свою очередь формирующих этот характер. Но если проследить и найти связь явлений, то станет очевидным, что всякая черта характера взрослого человека, всякое качество его души и, может быть, даже всякий его поступок были посеяны в детстве, имели с тех пор свой зародыш, свое семечко.
Сжатое изложение
Какой бы интересной ни была домашняя и школьная жизнь ребенка, без чтения драгоценных книг он обделён. Такие утраты невосполнимы. Взрослые могут прочесть книжку сегодня или через год. В детстве каждый день – открытия. Острота восприятия в детстве такова, что ранние впечатления могут повлиять на всю жизнь. Яркие и прочные впечатления детства – фундамент будущей духовной жизни, золотой фонд.
В детстве посеяны семена. Не все прорастут, расцветут. Но биография человеческой души – прорастание семян, посеянных в детстве.
Не все прорастут, расцветут. Но биография человеческой души – прорастание семян, посеянных в детстве.
Последующая жизнь сложна. Она состоит из миллионов поступков, определяющихся характером и формирующих его. Всякая черта характера взрослого человека, качества и поступки были посеяны в детстве, имели свой зародыш, свое семечко.
Текст № 9
Мы часто говорим о сложностях, связанных с воспитанием начинающего жизнь человека. И самая большая проблема – это ослабление семейных уз, уменьшение значения семьи в воспитании ребёнка. А если в ранние годы в человека семьёй не было заложено ничего прочного в нравственном смысле, то потом у общества будет немало хлопот с этим гражданином.
Другая крайность – чрезмерная опека ребёнка родителями. Это тоже следствие ослабления семейного начала. Родители недодали своему ребёнку душевного тепла и, ощущая эту вину, стремятся в будущем оплатить свой внутренний духовный долг запоздалой мелочной опекой и материальными благами.
Мир изменяется, становится другим. Но если родители не смогли установить внутренний контакт с ребёнком, перекладывая основные заботы на бабушек и дедушек или общественные организации, то не стоит удивляться тому, что иной ребёнок так рано приобретает цинизм и неверие в бескорыстие, что жизнь его обедняется, становится плоской и сухой.
Но если родители не смогли установить внутренний контакт с ребёнком, перекладывая основные заботы на бабушек и дедушек или общественные организации, то не стоит удивляться тому, что иной ребёнок так рано приобретает цинизм и неверие в бескорыстие, что жизнь его обедняется, становится плоской и сухой.
Микротемы:
Сложности в воспитании молодого поколения связаны с уменьшением значения семьи. Если семья ничего прочного в нравственном смысле не заложила, то у общества будет немало хлопот с этим гражданином.
Другая крайность – чрезмерная опека ребёнка родителями. Это тоже следствие ослабления семейного начала. Родители стремятся в будущем оплатить свой внутренний духовный долг запоздалой мелочной опекой и материальными благами
Мир изменяется, но если родители не смогли установить контакт с ребенком, переложили на других свои обязанности, то не стоит удивляться тому, что такой ребёнок становится циничным, а жизнь его – плоской и сухой.
Текст № 10
Одному человеку сказали, что его знакомый отозвался о нём в нелестных выражениях. «Да не может быть! – воскликнул человек. – Я ничего хорошего для него не сделал…». Вот он, алгоритм чёрной неблагодарности, когда на добро отвечают злом. В жизни, надо полагать, этот человек не раз встречался с людьми, перепутавшими ориентиры на компасе нравственности.
«Да не может быть! – воскликнул человек. – Я ничего хорошего для него не сделал…». Вот он, алгоритм чёрной неблагодарности, когда на добро отвечают злом. В жизни, надо полагать, этот человек не раз встречался с людьми, перепутавшими ориентиры на компасе нравственности.
Нравственность – это путеводитель по жизни. И если ты будешь отклоняться от дороги, то вполне можешь забрести в бурелом, колючий кустарник, а то и вовсе утонуть. То есть если ты неблагодарно ведёшь себя по отношению к другим, то и люди вправе вести себя по отношению к тебе так же.
Как же относиться к этому явлению? Относитесь философски. Совершайте добро и знайте, что оно наверняка окупится. Уверяю Вас, что Вы сами будете получать наслаждение от того, что делаете добро. То есть Вы будете счастливы. А это и есть цель в жизни – прожить её счастливо. И помните: творят добро возвышенные натуры.
Сжатое изложение
Одному человеку сказали, что его знакомый отозвался о нём плохо. Человек изумился, ведь ничего хорошего он для него не сделал. Это алгоритм чёрной неблагодарности, когда на добро отвечают злом. В жизни этот человек наверняка не раз встречался с людьми, перепутавшими ориентиры на компасе нравственности.
Это алгоритм чёрной неблагодарности, когда на добро отвечают злом. В жизни этот человек наверняка не раз встречался с людьми, перепутавшими ориентиры на компасе нравственности.
Нравственность – это путеводитель по жизни. Если ты неблагодарно ведёшь себя по отношению к другим, то и люди вправе вести себя по отношению к тебе так же.
Как же относиться к этому явлению? Совершайте добро и знайте, что оно наверняка окупится. Вы получите от этого наслаждение, вы будете счастливы. А это и есть цель в жизни!
Текст № 11
Война была для детей жестокой и грубой школой. Они сидели не за партами, а в мёрзлых окопах, и перед ними были не тетради, а бронебойные снаряды и пулемётные ленты. Они ещё не обладали жизненным опытом и поэтому не понимали истинной ценности простых вещей, которым не придаёшь значения в повседневной мирной жизни.
Война наполнила их душевный опыт до предела. Они могли плакать не от горя, а от ненависти, могли по-детски радоваться весеннему журавлиному клину, как никогда не радовались ни до войны, ни после войны, с нежностью хранить в душе тепло ушедшей юности. Те, кто остался в живых, вернулись с войны, сумев сохранить в себе чистый, лучезарный мир, веру и надежду, став непримиримее к несправедливости, добрее к добру.
Те, кто остался в живых, вернулись с войны, сумев сохранить в себе чистый, лучезарный мир, веру и надежду, став непримиримее к несправедливости, добрее к добру.
Хотя война и стала уже историей, но память о ней должна жить, ведь главные участники истории – это Люди и Время. Не забывать Время – это значит не забывать Людей, не забывать Людей – это значит не забывать Время.
Микротемы:
Война стала для детей жестокой и грубой школой.
Пройдя войну, молодые люди приобрели огромный душевный опыт и смогли сохранить в себе человечность.
Главные участники истории – это Люди и Время, память о которых не должна угаснуть.
Текст № 12
Универсального рецепта того, как выбрать правильный, единственно верный, только тебе предназначенный путь в жизни, просто нет и быть не может. И окончательный выбор всегда остаётся за человеком.
Этот выбор мы делаем уже в детстве, когда выбираем друзей, учимся строить отношения с ровесниками, играть. Но большинство важнейших решений, определяющих жизненный путь, мы всё-таки принимаем в юности. Как считают учёные, вторая половина второго десятилетия жизни – самый ответственный период. Именно в это время человек, как правило, выбирает самое главное и на всю жизнь: ближайшего друга, круг основных интересов, профессию.
Как считают учёные, вторая половина второго десятилетия жизни – самый ответственный период. Именно в это время человек, как правило, выбирает самое главное и на всю жизнь: ближайшего друга, круг основных интересов, профессию.
Понятно, что такой выбор – дело ответственное. От него невозможно отмахнуться, его нельзя отложить на потом. Не стоит надеяться, что ошибку после можно будет исправить: успеется, вся жизнь впереди! Что-то, конечно, удастся подправить, изменить, но далеко не всё. И неверные решения без последствий не останутся. Ведь успех приходит к тем, кто знает, чего он хочет, решительно делает выбор, верит в себя и упорно достигает намеченных целей.
| № п\п | Главная информация по микротемам для сжатого изложения |
| 1. | Универсального рецепта, как выбрать правильный, единственно верный, только тебе предназначенный путь в жизни, нет и быть не может. Выбор всегда остаётся за человеком. |
| 2. | Большинство важнейших решений, определяющих жизненный путь, мы принимаем в юности. Вторая половина второго десятилетия жизни – самый ответственный период. В это время человек выбирает самое главное и на всю жизнь: друга, круг интересов, профессию. Вторая половина второго десятилетия жизни – самый ответственный период. В это время человек выбирает самое главное и на всю жизнь: друга, круг интересов, профессию. |
| 3. | Такой выбор – дело ответственное. Его нельзя отложить на потом, потому что неверные решения без последствий не останутся. Успех приходит к тем, кто знает, чего он хочет, решительно делает выбор, верит в себя и упорно достигает намеченных целей. |
Текст № 13
Слово «мама» – особое слово. Оно рождается вместе с нами, сопровождает нас в годы взросления и зрелости. Его лепечет дитя в колыбели. С любовью произносит юноша и глубокий старец. В языке любого народа есть это слово. И на всех языках оно звучит нежно и ласково.
Место матери в нашей жизни особое, исключительное. Мы всегда несем ей свою радость и боль и находим понимание. Материнская любовь окрыляет, придает силы, вдохновляет на подвиг. В сложных жизненных обстоятельствах мы всегда вспоминаем маму. И нужна нам в этот миг только она. Человек зовёт мать и верит, что она, где бы не была, слышит его, сострадает и спешит на помощь. Слово «мама» становится равнозначным слову «жизнь».
Человек зовёт мать и верит, что она, где бы не была, слышит его, сострадает и спешит на помощь. Слово «мама» становится равнозначным слову «жизнь».
Сколько художников, композиторов, поэтов создали замечательные произведения о маме! «Берегите матерей!» – провозгласил в своей поэме известный поэт Расул Гамзатов. К сожалению, мы слишком поздно понимаем, что забыли сказать много хороших и добрых слов своей маме. Чтобы этого не произошло, нужно дарить им радость каждый день и час. Ведь благодарные дети – лучший подарок для них.
Сжатое изложение
Слово «мама» – особое слово. Оно с нами всегда: в детстве, юности, зрелости, старости. В языке любого народа есть это слово. И на всех языках оно звучит нежно и ласково.
Место матери в нашей жизни особое. Мы всегда несем ей свою радость и боль и находим понимание. Материнская любовь придает силы, вдохновляет на подвиг. В сложных жизненных обстоятельствах мы всегда вспоминаем маму. Нужна нам в этот миг только она. Человек зовёт мать и верит, что она слышит, сострадает, спешит на помощь. Слова «мама» и «жизнь» становятся равнозначными.
Слова «мама» и «жизнь» становятся равнозначными.
Сколько замечательных произведений создано о маме! Очень поздно мы понимаем, что забыли сказать много хороших, добрых слов своей маме. Чтобы этого не про-изошло, нужно дарить им радость каждый день и час. Благодарные дети – лучший подарок для них.
Текст № 14
Прожить жизнь с достоинством и получить радость человеку позволяет настоящая цель. Если человек живёт, чтобы приносить людям добро, облегчать их страдания при болезнях, давать людям радость, то он ставит себе цель, достойную человека. Если человек ставит перед собой задачу приобрести все элементарные материальные блага: машину, дачу, мебельный гарнитур, – он допускает роковую ошибку.
Ставя себе целью карьеру или приобретательство, человек испытывает в сумме гораздо больше огорчений, чем радостей, и рискует потерять всё. Не повысили в должности – огорчение. Не успел купить марку для своей коллекции – огорчение. У кого-то лучшая, чем у тебя, мебель или лучшая машина – опять огорчение, и ещё какое! А что может потерять человек, который радовался каждому своему доброму делу? Важно только, чтобы добро, которое человек делает, было бы его внутренней потребностью, шло от умного сердца, а не только от головы.
Поэтому главной жизненной задачей должна быть обязательно задача шире, чем просто личностная, она не должна быть замкнута только на собственных удачах и неудачах. Она должна диктоваться добротой к людям, любовью к семье, к своему городу, к своему народу, стране, ко всей вселенной.
(По Д.С.Лихачеву)
Микротемы
Прожить жизнь с достоинством и получить радость человеку позволяет настоящая цель, которая заключается в служении людям.
Личная выгода не может принести человеку столько радости, сколько добрые дела для других людей, совершенные от всего сердца.
Поэтому главная жизненная задача должна быть шире, чем личные интересы человека, она должна диктоваться добротой к людям.
Текст № 15
Мы часто говорим друг другу: «Желаю тебе всего доброго». Это не просто выражение вежливости. В этих словах мы выражаем свою человеческую сущность. Надо иметь большую силу духа, чтобы уметь желать добра другим. Умение чувствовать, умение видеть по-доброму окружающих тебя людей – это не только показатель культуры, но и результат огромной внутренней работы духа.
Обращаясь друг к другу с просьбой, мы говорим «пожалуйста». Просьба – это порыв души. Отказать человеку в помощи – значит потерять собственное человеческое достоинство. Равнодушие к нуждающимся в помощи – это душевное уродство. Чтобы уберечь себя от равнодушия, надо развивать в своей душе соучастие, сочувствие, сострадание. И в то же время – умение отличать безобидные человеческие слабости от пороков, калечащих душу.
Увеличивать добро в окружающем нас мире – в этом заключается самая большая цель в жизни. Добро слагается из малого. И каждый раз жизнь ставит перед человеком задачу, которую надо уметь решать. Любовь и дружба, разрастаясь и распространяясь на многое, обретают новые силы, становятся все выше, а человек, их центр, мудрее. (По Д. Лихачеву.)
Микротемы
Пожелание добра людям – выражение сущности человека. Умение видеть по-доброму окружающий мир, людей – показатель культуры, результат большой внутренней работы.
Доброта – это человеческое достоинство, а равнодушие – душевное уродство; чтобы уберечься от него, надо развивать в своей душе сочувствие и соучастие.
Увеличивать добро в окружающем нас мире – в этом заключается самая большая цель жизни; умение любить и дружить делает человека мудрее и сильнее.
Текст 16
Человек совершил проступок или даже преступление. Или просто не оправдал надежд, которые на него возлагали. Ищут объяснений. Ищет их и он сам. Чаще не столько объяснения, сколько оправдания. Окружающие и он сам винят семью, школу, коллектив, обстоятельства.
Не следует забывать, какую роль в своей собственной судьбе играет сам человек. Забывать о важной, а может быть, важнейшей части воспитания – самовоспитании. Ведь из всех обстоятельств, формирующих человека, важнейшее – сознательное отношение к собственной жизни, к собственным мыслям и планам и прежде всего – к собственным действиям.
Самовоспитание начинается с самооценки. Если человек начинает находить в каждом деле непреодолимые препятствия, теряет уверенность в себе, значит, у него формируется заниженная самооценка. Не менее опасна и завышенная самооценка, когда человек считает себя всегда и во всём правым и не прислушивается к мнению других. Только умение адекватно оценивать свои возможности позволяет правильно сформулировать жизненные цели и добиваться их. (По С. Львову.)
Только умение адекватно оценивать свои возможности позволяет правильно сформулировать жизненные цели и добиваться их. (По С. Львову.)
Микротемы
Свои неудачи и проступки люди подчас склонны объяснять и оправдывать ошибками в своём воспитании и различными обстоятельствами.
Из всех обстоятельств, формирующих человека, важнейшим является самовоспитание.
Только правильная самооценка позволяет человеку ставить в жизни конкретные цели и добиваться их.
Текст № 17
Время меняет людей. Но кроме времени, есть еще одна категория, воздействующая на тебя, может быть, даже посильнее, чем время. Это образ жизни, отношение к ней, сострадание к другим. Существует соображение, что сострадание воспитывается собственной бедой. Мне не нравится это соображение. Я верю, что сострадание — это особенный талант, и без него трудно оставаться человеком.
Человек безмятежной судьбы знает, конечно, о бедах, о том, что есть несчастные, а среди них – и дети. Да, несчастья и беды — это неизбежность. Но жизнь устроена так, что несчастье счастливому кажется чаще всего далёким, порой даже нереальным. Если у тебя всё хорошо, беда представляется рассыпанной по миру маленькими песчинками. Несчастье кажется нетипичным, а типичным — счастье. Счастье не будет счастьем, если оно каждый миг станет думать о беде и горе.
Но жизнь устроена так, что несчастье счастливому кажется чаще всего далёким, порой даже нереальным. Если у тебя всё хорошо, беда представляется рассыпанной по миру маленькими песчинками. Несчастье кажется нетипичным, а типичным — счастье. Счастье не будет счастьем, если оно каждый миг станет думать о беде и горе.
Собственные беды оставляют в душе рубцы и учат человека важным истинам. Но если человек запоминает только такие уроки, у него заниженная чувствительность. Плакать от собственной боли не трудно. Труднее плакать от боли чужой. Знаменитый мыслитель прошлого сказал: «Процветание раскрывает наши пороки, а бедствие — наши добродетели». (По А. Лиханову.)
Микротемы к тексту
Сострадание – это особый талант, и без него трудно оставаться человеком.
Несчастья и беды – это неизбежность, но о них нельэя думать постоянно,чтобы не омрачать счастья.
Умение переживать чужую боль раскрывает истинные добродетели человека.
Текст № 18
Были ли у человеческого искусства два пути с самого начала или оно раздвоилось гораздо позже? Что же было вначале: потребность души поделиться своей красотой с другим человеком или потребность человека украсить свой боевой топор? А если потребность души, если просто накопившееся в душе потребовало выхода и изумления, то не всё ли равно, на что ему было излиться: на полезное орудие труда или просто на подходящую для этого поверхность прибрежной гладкой скалы?
Красота окружающего мира: цветка и полёта ласточки, туманного озера и звезды, восходящего солнца и пчелиного сота, дремучего дерева и женского лица – вся красота окружающего мира постепенно аккумулировалась в душе человека. Потом неизбежно началась отдача. Изображение цветка или оленя появилось на рукоятке боевого топора. Изображение солнца или птицы украсило берестяное ведерко либо первобытную глиняную тарелку. Ведь до сих пор народное искусство носит ярко выраженный прикладной характер. Всякое украшенное изделие – это прежде всего изделие. Будь то солонка, дуга, ложка, трепало, салазки, полотенце, детская колыбелька…
Потом неизбежно началась отдача. Изображение цветка или оленя появилось на рукоятке боевого топора. Изображение солнца или птицы украсило берестяное ведерко либо первобытную глиняную тарелку. Ведь до сих пор народное искусство носит ярко выраженный прикладной характер. Всякое украшенное изделие – это прежде всего изделие. Будь то солонка, дуга, ложка, трепало, салазки, полотенце, детская колыбелька…
Потом уж искусство отвлеклось. Рисунок на скале не имеет никакого прикладного характера. Это просто радостный или горестный крик души. От никчёмного рисунка на скале до рисунка Рембрандта, оперы Вагнера, скульптуры Родена, романа Достоевского, стихотворения Блока, пируэта Галины Улановой. (По В. Солоухину.)
Как писать изложение на ОГЭ по русскому языку
Похожие статьи.
Автоматическое суммирование текста с использованием алгоритма TextRank
Введение
Text Summarization — одно из тех приложений обработки естественного языка (NLP), которое обязательно окажет огромное влияние на нашу жизнь. С растущими цифровыми медиа и постоянно растущим числом публикаций – у кого есть время просматривать целые статьи/документы/книги, чтобы решить, полезны они или нет? К счастью, эта технология уже существует.
С растущими цифровыми медиа и постоянно растущим числом публикаций – у кого есть время просматривать целые статьи/документы/книги, чтобы решить, полезны они или нет? К счастью, эта технология уже существует.
Сталкивались ли вы с мобильным приложением в шортах ? Это инновационное новостное приложение, которое преобразует новостные статьи в резюме из 60 слов.И это именно то, что мы собираемся узнать в этой статье — Автоматическое суммирование текста .
Автоматическое суммирование текста — одна из самых сложных и интересных задач в области обработки естественного языка (NLP). Это процесс создания краткого и значимого резюме текста из нескольких текстовых ресурсов, таких как книги, новостные статьи, сообщения в блогах, исследовательские работы, электронные письма и твиты.
Спрос на системы автоматического реферирования текста в наши дни резко возрастает благодаря доступности больших объемов текстовых данных.
В этой статье мы изучим возможности суммирования текста. Разберемся, как работает алгоритм TextRank, а также реализуем его на Python. Пристегнитесь, это будет веселая поездка!
Разберемся, как работает алгоритм TextRank, а также реализуем его на Python. Пристегнитесь, это будет веселая поездка!
Содержание
- Подходы к суммированию текста
- Понимание алгоритма TextRank
- Понимание постановки задачи
- Реализация алгоритма TextRank
- Что дальше?
Подходы к суммированию текста
Автоматическое суммирование текста привлекло внимание еще в 1950-х годах.В исследовательской статье, опубликованной Гансом Петером Луном в конце 1950-х годов, под названием «Автоматическое создание литературных рефератов» использовались такие функции, как частота слов и фраз, для извлечения важных предложений из текста для целей обобщения.
Еще одно важное исследование, проведенное Гарольдом П. Эдмундсоном в конце 1960-х годов, использовало такие методы, как наличие ключевых слов, слов, используемых в заголовке, появляющихся в тексте, и расположение предложений, для извлечения значимых предложений для обобщения текста. С тех пор было опубликовано много важных и интересных исследований, посвященных решению проблемы автоматического суммирования текста.
С тех пор было опубликовано много важных и интересных исследований, посвященных решению проблемы автоматического суммирования текста.
Обобщение текста можно условно разделить на две категории — Извлекательное обобщение и Абстрактное обобщение .
- Извлекающее обобщение: Эти методы основаны на извлечении нескольких частей, таких как фразы и предложения, из фрагмента текста и объединении их вместе для создания резюме. Поэтому определение правильных предложений для обобщения имеет первостепенное значение в экстрактивном методе.
- Абстрактное обобщение: Эти методы используют передовые техники НЛП для создания совершенно нового резюме. Некоторые части этого резюме могут даже не появляться в исходном тексте.
В этой статье мы сосредоточимся на методе экстрактивного суммирования .
Понимание алгоритма TextRank
Прежде чем приступить к работе с алгоритмом TextRank, следует ознакомиться с другим алгоритмом — алгоритмом PageRank. На самом деле, это действительно вдохновило TextRank! PageRank используется в первую очередь для ранжирования веб-страниц в результатах онлайн-поиска. Давайте быстро разберемся в основах этого алгоритма на примере.
На самом деле, это действительно вдохновило TextRank! PageRank используется в первую очередь для ранжирования веб-страниц в результатах онлайн-поиска. Давайте быстро разберемся в основах этого алгоритма на примере.
Алгоритм PageRank
Источник: http://www.scottbot.net/HIAL/
Предположим, у нас есть 4 веб-страницы — w1, w2, w3 и w4. Эти страницы содержат ссылки, указывающие друг на друга. На некоторых страницах может не быть ссылки — они называются оборванными страницами.
- Веб-страница w1 содержит ссылки, ведущие на w2 и w4
- w2 имеет ссылки для w3 и w1
- w4 имеет ссылки только для веб-страницы w1
- w3 не имеет ссылок и поэтому будет называться оборванной страницей
Чтобы ранжировать эти страницы, мы должны были бы вычислить оценку, называемую оценкой PageRank . Эта оценка представляет собой вероятность того, что пользователь посетит эту страницу.
Чтобы зафиксировать вероятности перехода пользователей с одной страницы на другую, мы создадим квадратную матрицу M , имеющую n строк и n столбцов, где n — количество веб-страниц.
Каждый элемент этой матрицы обозначает вероятность перехода пользователя с одной веб-страницы на другую. Например, выделенная ячейка ниже содержит вероятность перехода от w1 к w2.
Инициализация вероятностей описана в следующих шагах:
- Вероятность перехода со страницы i на страницу j, т. е. M[ i ][ j ], инициализируется с помощью 1/(количество уникальных ссылок на веб-странице wi)
- Если нет связи между страницей i и j, то вероятность будет инициализирована с 0
- Если пользователь попал на зависшую страницу, то предполагается, что он с равной вероятностью перейдет на любую страницу.Следовательно, M[i][j] будет инициализирован с 1/(количество веб-страниц)
Следовательно, в нашем случае матрица M будет инициализирована следующим образом:
Наконец, значения в этой матрице будут итеративно обновляться, чтобы получить ранжирование веб-страницы.
Алгоритм TextRank
Теперь, когда мы разобрались с PageRank, давайте разберемся с алгоритмом TextRank. Я перечислил сходства между этими двумя алгоритмами ниже:
- Вместо веб-страниц мы используем предложения
- Сходство между любыми двумя предложениями используется как эквивалент вероятности перехода на веб-страницу
- Показатели сходства хранятся в квадратной матрице, аналогичной матрице M, используемой для PageRank
TextRank — это извлекающий и неконтролируемый метод суммирования текста. Давайте посмотрим на алгоритм TextRank, которому мы будем следовать:
- Первым шагом будет объединение всего текста, содержащегося в статьях
- Затем разбейте текст на отдельные предложения
- На следующем шаге мы найдем векторное представление (вложение слов) для каждого предложения
- Затем вычисляются сходства между векторами предложений и сохраняются в матрице
- Затем матрица сходства преобразуется в граф с предложениями в качестве вершин и показателями сходства в качестве ребер для расчета ранга предложений
- Наконец, определенное количество предложений с наивысшим рейтингом составляет окончательное резюме
Итак, без лишних слов, давайте запустим наши ноутбуки Jupyter и начнем программировать!
Примечание. Если вы хотите узнать больше о теории графов, я рекомендую прочитать эту статью .
Если вы хотите узнать больше о теории графов, я рекомендую прочитать эту статью .
Понимание постановки задачи
Будучи большим любителем тенниса, я всегда стараюсь быть в курсе того, что происходит в спорте, неукоснительно просматривая как можно больше новостей о теннисе в Интернете. Однако, как оказалось, это довольно сложная работа! Ресурсов слишком много, а время ограничено.
Поэтому я решил разработать систему, которая могла бы подготовить для меня краткое изложение, просматривая несколько статей.Как это сделать? Это то, что я покажу вам в этом уроке. Мы применим алгоритм TextRank к набору данных извлеченных статей с целью создания красивого и краткого резюме.
Обратите внимание, что это, по сути, задача обобщения нескольких документов в одном домене, то есть мы возьмем несколько статей в качестве входных данных и сгенерируем одно резюме. Обобщение многодоменного текста не рассматривается в этой статье, но не стесняйтесь попробовать его в конце.
Вы можете скачать набор данных, который мы будем использовать, отсюда.
Реализация алгоритма TextRank
Итак, без дальнейших церемоний, запустите свои Jupyter Notebooks и давайте реализуем то, что мы уже узнали.
Импорт необходимых библиотек
Сначала импортируйте библиотеки, которые мы будем использовать для этой задачи.
импортировать numpy как np
импортировать панд как pd
импортировать нлтк
nltk.download('punkt') # однократное выполнение
импорт ре
Чтение данных
Теперь давайте прочитаем наш набор данных.Я предоставил ссылку для загрузки данных в предыдущем разделе (на случай, если вы ее пропустили).
df = pd.read_csv("tennis_articles_v4.csv")
Проверить данные
Давайте быстро взглянем на данные.
дф.голова()
В нашем наборе данных есть 3 столбца — «article_id», «article_text» и «source». Нас больше всего интересует столбец article_text, так как он содержит текст статей. Давайте напечатаем некоторые значения переменной, чтобы посмотреть, как они выглядят.
Давайте напечатаем некоторые значения переменной, чтобы посмотреть, как они выглядят.
df['article_text'][0]
Вывод:
«У Марии Шараповой практически нет друзей-теннисисток в WTA Tour. Российская теннисистка не имеет никаких проблем с тем, чтобы открыто говорить об этом, и в недавнем интервью она сказала: «Я действительно не слишком сильно скрывать любые чувства. Я думаю, все знают, что это моя работа здесь. Когда я на кортах или когда я играю на корте, я соревнуюсь и хочу победить каждого, будь то они в раздевалке или в сети...
дф['текст_статьи'][1]
БАЗЕЛЬ, Швейцария (AP), Роджер Федерер вышел в 14-й швейцарский финал в своей карьере, победив седьмой сеяный Даниил Медведев 6-1, 6-4 в субботу. В поисках девятого титула на турнире в своем родном городе и 99-го В целом, в воскресенье Федерер сыграет с Мариусом Копилом, занявшим 93-е место. Федерер доминировал над Медведевым, занявшим 20-е место. его первый шанс на матч-пойнт снова сделать брейк при счете 5:1.
 ..
.. df['article_text'][2]
Роджер Федерер сообщил, что организаторы возобновленного и сокращенного Кубка Дэвиса дали ему три дня на решить, согласится ли он участвовать в спорном соревновании.Выступая на турнире Swiss Indoors, где он сыграем в воскресном финале против румынского квалификационного игрока Мариуса Копила, третья ракетка мира сказала, что, учитывая невероятно короткие сроки для принятия решения, он отказался от каких-либо обязательств...
Теперь у нас есть 2 варианта: мы можем либо обобщить каждую статью отдельно, либо создать единую сводку для всех статей. Для нашей цели мы продолжим с последним.
Разделить текст на предложения
Теперь следующий шаг — разбить текст на отдельные предложения.Для этого мы будем использовать функцию sent_tokenize() библиотеки nltk .
из импорта nltk.tokenize send_tokenize предложения = [] для s в df['article_text']: предложения.append(sent_tokenize(s)) предложения = [y для x в предложениях для y в x] # сгладить список
Выведем несколько элементов списка предложений .
предложений[:5]
Вывод:
['У Марии Шараповой практически нет друзей-теннисисток в WTA Tour.', «У российского игрока нет проблем с тем, чтобы открыто говорить об этом и в недавнем интервью она сказала: «На самом деле я не особо скрываю свои чувства». 'Я думаю, все знают, что это моя работа здесь.', «Когда я на корте или когда я играю на корте, Я спортсмен, и я хочу победить каждого, независимо от того, находится ли он в в раздевалке или в сети. Так что я не тот, кто завязывает разговор о погоду и знаю, что в ближайшие несколько минут я должен пойти и попытаться выиграть теннисный матч.", "Я довольно конкурентоспособная девушка."]
Скачать GloVe Word Embeddings
Вложения слов GloVe представляют собой векторное представление слов. Эти вложения слов будут использоваться для создания векторов для наших предложений. Мы могли бы также использовать подходы Bag-of-Words или TF-IDF для создания функций для наших предложений, но эти методы игнорируют порядок слов (а количество функций обычно довольно велико).
Мы будем использовать предварительно обученные векторы Wikipedia 2014 + Gigaword 5 GloVe, доступные здесь. Обратите внимание — размер этих вложений слов составляет 822 МБ.
!wget http://nlp.stanford.edu/data/glove.6B.zip !распаковать перчатку*.zip
Давайте извлечем вложения слов или векторы слов.
# Извлечение векторов слов
word_embeddings = {}
f = открыть('glove.6B.100d.txt', кодирование='utf-8')
для строки в f:
значения = строка.split()
слово = значения[0]
coefs = np.asarray (значения [1:], dtype = 'float32')
word_embeddings[слово] = коэффициенты
ф.а-зА-Я]", "")
# сделать буквы строчными
clean_sentences = [s.lower() для s в clean_sentences] Избавьтесь от стоп-слов (обычно используемых слов языка – is, am, the, of, in и т. д.), присутствующих в предложениях. Если вы не скачали nltk-stopwords , выполните следующую строку кода:
nltk.download('стоп-слова') Теперь мы можем импортировать стоп-слова.
из nltk.corpus импортировать стоп-слова
стоп_слова = стоп-слова.слова('английский') Давайте определим функцию для удаления этих стоп-слов из нашего набора данных.
# функция для удаления стоп-слов def remove_stopwords (сен): sen_new = " ".join([i для i в sen, если я не в стоп_словах]) вернуть sen_new
# удалить стоп-слова из предложений clean_sentences = [remove_stopwords(r.split()) для r в clean_sentences]
Мы будем использовать clean_sentences для создания векторов предложений в наших данных с помощью векторов слов GloVe.
Векторное представление предложений
# Извлечение векторов слов
word_embeddings = {}
f = открыть('glove.6B.100d.txt', кодирование='utf-8')
для строки в f:
значения = строка.split()
слово = значения[0]
coefs = np.asarray (значения [1:], dtype = 'float32')
word_embeddings[слово] = коэффициенты
е. закрыть () Теперь давайте создадим векторы для наших предложений. Сначала мы выберем векторы (каждый размером 100 элементов) для составляющих слов в предложении, а затем возьмем среднее значение этих векторов, чтобы получить объединенный вектор для предложения.
Сначала мы выберем векторы (каждый размером 100 элементов) для составляющих слов в предложении, а затем возьмем среднее значение этих векторов, чтобы получить объединенный вектор для предложения.
предложений_векторов = []
для я в clean_sentences:
если len(i) != 0:
v = sum([word_embeddings.get(w, np.zeros((100,))) для w в i.split()])/(len(i.split())+0,001)
еще:
v = np.zeros ((100,))
предложение_векторов.append(v) Примечание: Дополнительные рекомендации по предварительной обработке текста можно найти в нашем видеокурсе «Обработка естественного языка (NLP) с использованием Python».
Подготовка матрицы подобия
Следующим шагом будет поиск сходства между предложениями, и мы будем использовать подход косинусного подобия для этой задачи.Давайте создадим пустую матрицу подобия для этой задачи и заполним ее косинусным сходством предложений.
Давайте сначала определим нулевую матрицу размеров (n * n). Мы инициализируем эту матрицу оценками косинусного сходства предложений. Здесь n — это количество предложений.
Здесь n — это количество предложений.
# матрица подобия sim_mat = np.zeros([len(предложения), len(предложения)])
Мы будем использовать косинусное сходство для вычисления сходства между парой предложений.
из sklearn.metrics.pairwise import cosine_similarity
И инициализируйте матрицу показателями косинусного сходства.
для i в диапазоне (len (предложения)):
для j в диапазоне (len (предложения)):
если я != j:
sim_mat[i][j] = cosine_similarity(sentence_vectors[i].reshape(1,100), offer_vectors[j].reshape(1,100))[0,0]
Применение алгоритма PageRank
Прежде чем двигаться дальше, давайте преобразуем матрицу подобия sim_mat в граф.Узлы этого графика будут представлять предложения, а ребра будут представлять оценки сходства между предложениями. На этом графике мы применим алгоритм PageRank, чтобы получить ранжирование предложений.
импортировать networkx как nx nx_graph = nx.
 from_numpy_array(sim_mat)
баллы = nx.pagerank(nx_graph)
from_numpy_array(sim_mat)
баллы = nx.pagerank(nx_graph)
Краткое извлечение
Наконец, пришло время извлечь N лучших предложений на основе их рейтинга для создания сводки.
ranked_sentences = sorted(((scores[i],s) for i,s в enumerate(sentences)), reverse=True)
# Извлечение первых 10 предложений в качестве сводки для я в диапазоне (10): print(ranked_sentences[i][1])
Когда я нахожусь на корте или когда я играю на корте, я участвую в соревнованиях и хочу победить каждого. находятся ли они в раздевалке или в сети.Так что я не тот, кто завязывает разговор о погоду и знаю, что в ближайшие несколько минут я должен пойти и попытаться выиграть теннисный матч. Крупные игроки считают, что большое событие в конце ноября в сочетании с событием в январе перед Открытым чемпионатом Австралии по теннису означает слишком много тенниса и слишком мало отдыха. Выступление на турнире Swiss Indoors, где он сыграет в воскресном финале против прошедшего квалификацию румына Мариуса.
 Копил, третья ракетка мира, сказал, что, учитывая невероятно короткие сроки для принятия решения, он отказался от
любое обязательство.«Мне казалось, что лучшими неделями, когда мне приходилось знакомиться с игроками, когда я играл, были недели Кубка Федерации или недели Кубка Федерации.
Олимпийские недели, не обязательно во время турниров.
В настоящее время Нисикори, занимающий девятое место, с победой может переместиться на 125 очков от отсечки в турнире из восьми человек.
в Лондоне в следующем месяце.
Он использовал свой первый брейк-пойнт, чтобы закрыть первый сет, а затем увеличил счет 3:0 во втором и завершил сет.
выиграть по своему первому матч-пойнту.
Испанец дважды сломал Андерсона во втором, но не получил еще один шанс на подаче южноафриканца в
финальный набор.«У нас также сложилось впечатление, что на данном этапе лучше играть матчи, чем тренироваться.
В следующем году в финале конкурса, который пройдет 18-24 ноября в Мадриде, примут участие 18 стран.
классические домашние и выездные матчи игрались четыре раза в год на протяжении десятилетий.
Копил, третья ракетка мира, сказал, что, учитывая невероятно короткие сроки для принятия решения, он отказался от
любое обязательство.«Мне казалось, что лучшими неделями, когда мне приходилось знакомиться с игроками, когда я играл, были недели Кубка Федерации или недели Кубка Федерации.
Олимпийские недели, не обязательно во время турниров.
В настоящее время Нисикори, занимающий девятое место, с победой может переместиться на 125 очков от отсечки в турнире из восьми человек.
в Лондоне в следующем месяце.
Он использовал свой первый брейк-пойнт, чтобы закрыть первый сет, а затем увеличил счет 3:0 во втором и завершил сет.
выиграть по своему первому матч-пойнту.
Испанец дважды сломал Андерсона во втором, но не получил еще один шанс на подаче южноафриканца в
финальный набор.«У нас также сложилось впечатление, что на данном этапе лучше играть матчи, чем тренироваться.
В следующем году в финале конкурса, который пройдет 18-24 ноября в Мадриде, примут участие 18 стран.
классические домашние и выездные матчи игрались четыре раза в год на протяжении десятилетий. Ранее в этом месяце в Шанхае Федерер заявил, что его шансы сыграть в Кубке Дэвиса практически нулевые.
Ранее в этом месяце в Шанхае Федерер заявил, что его шансы сыграть в Кубке Дэвиса практически нулевые. Вот и все! Удивительное, аккуратное, краткое и полезное резюме для наших статей.
Что дальше?
Автоматическое суммирование текста — горячая тема исследований, и в этой статье мы рассмотрели лишь верхушку айсберга. В дальнейшем мы рассмотрим технику абстрактного обобщения текста, в которой большую роль играет глубокое обучение. Кроме того, мы также можем рассмотреть следующие задачи суммирования:
Специфичная для проблемы
- Обобщение текста по нескольким доменам
- Обобщение отдельных документов
- Обобщение текста на разных языках (источник на одном языке и резюме на другом языке)
Зависит от алгоритма
- Обобщение текста с использованием RNN и LSTM
- Обобщение текста с использованием обучения с подкреплением
- Суммирование текста с использованием генеративно-состязательных сетей (GAN)
Конец Примечания
Я надеюсь, что этот пост помог вам понять концепцию автоматического суммирования текста. Он имеет множество вариантов использования и породил чрезвычайно успешные приложения. Будь то для использования в вашем бизнесе или просто для ваших собственных знаний, суммирование текста — это подход, с которым должны быть знакомы все энтузиасты НЛП.
Он имеет множество вариантов использования и породил чрезвычайно успешные приложения. Будь то для использования в вашем бизнесе или просто для ваших собственных знаний, суммирование текста — это подход, с которым должны быть знакомы все энтузиасты НЛП.
В следующей статье я постараюсь рассказать о методе реферирования абстрактного текста с использованием передовых технологий. Между тем, не стесняйтесь использовать раздел комментариев ниже, чтобы сообщить мне свои мысли или задать любые вопросы, которые могут у вас возникнуть по этой статье.
Найдите код в этом репозитории GitHub.
РодственныеСуммировать длинные текстовые документы с помощью машинного обучения | by Satyam Kumar
Устали читать длинные текстовые документы, обобщите их, используя библиотеки Python с открытым исходным кодом
Изображение SCY с Pixabay Обобщение текста — это процесс создания краткого, точного и беглого изложения длинного текстового документа. Это процесс выделения наиболее важной информации для текстового документа.Цель суммирования текста состоит в том, чтобы создать сводку большого корпуса с важными моментами, описывающими весь корпус.
Это процесс выделения наиболее важной информации для текстового документа.Цель суммирования текста состоит в том, чтобы создать сводку большого корпуса с важными моментами, описывающими весь корпус.
В Интернете генерируется огромное количество текстовых данных, будь то статьи в социальных сетях, новостные статьи и т. д. Создание резюме вручную требует много времени, поэтому возникла потребность в автоматических текстовых резюме. Инструменты автоматического суммирования не только намного быстрее, но и менее предвзяты, чем люди.
Обобщение текста полезно во многих отношениях для обобщения текстовых данных.Вот некоторые из применений суммирования текста:
- Чтобы сократить время чтения длинных документов
- При исследовании документов сводки облегчают процесс выбора.
- Резюме текста полезно для систем вопрос-ответ.
Использование системы реферирования текста позволяет коммерческим реферативным службам увеличить количество обрабатываемых текстовых документов. Несколько новостных порталов, таких как Google News, Inshorts и т. д., предоставляют своим читателям краткие сводки длинных новостных статей.
Несколько новостных порталов, таких как Google News, Inshorts и т. д., предоставляют своим читателям краткие сводки длинных новостных статей.
Sumy — это библиотека Python с открытым исходным кодом для извлечения сводок из HTML-страниц и текстовых файлов. Пакет также содержит структуру оценки для текстовых резюме. Сумы предлагают несколько алгоритмов и методов для реферирования текста, некоторые из них:
- Лун: эвристический метод
- Латентный семантический анализ (LSA)
- Эвристический метод Эдмундсона
- LexRank
- TextRank и многие другие. Посетите страницу документации Sumy, чтобы узнать больше об алгоритме реферирования текста, который предлагает Sumy.
В этой статье мы обсудим и реализуем некоторые популярные алгоритмы реферирования текста Luhn, LexRank, LSA.
Установка:
Sumy — это библиотека Python с открытым исходным кодом, которую можно установить с помощью PyPl:
pip install sumy
Сумской пакет.
Чтобы прочитать текстовый документ из переменной текстовой строки «document»:
parser = PlaintextParser.from_string(document, Tokenizer("english")) Чтобы прочитать текстовый документ из текстового файла с местоположением как «file»:
parser = PlaintextParser.from_file(file, Tokenizer("english")) После прочтения текстового документа в Sumy Text Parser мы можем использовать несколько алгоритмов или методов для суммирования данного текстового документа.
Алгоритм LexRank — это неконтролируемый подход к суммированию, основанный на алгоритме PageRank. LexRank использует коэффициент косинусного сходства , модифицированный IDF, , чтобы улучшить показатель PageRank для суммирования документов.Он обобщает текст на основе оценки центральности предложений на основе графа.
Если одно предложение очень похоже на другие предложения в текстовом корпусе, то это предложение считается очень важным. Такие предложения можно рекомендовать пользователям.
Такие предложения можно рекомендовать пользователям.
Реализация LexRank с помощью Sumy:
Сумматор LexRank может быть реализован с помощью объекта, вызываемого из пакета Sumy. После создания объекта LexRankSummarizer передайте текстовый документ и количество строк для возврата в сводке.
Латентный семантический анализ (LSA) основан на методах частоты терминов с декомпозицией по сингулярным значениям для суммирования текстов. LSA — это неконтролируемый метод NLP, и цель LSA — создать представление текстовых данных с точки зрения тем или скрытых функций.
LSA состоит из двух шагов:
- Создание матрицы терминов документа (или числового вектора).
- Для выполнения декомпозиции по единственному значению матрицы терминов документа. SVD уменьшает размерность исходного набора данных, кодируя его со скрытыми функциями.
С LSA эти скрытые функции представляют темы в исходных данных.
Текстовые суммировщики используются для создания кратких сводок длинных текстовых документов. Входные длинные текстовые документы взяты со страницы машинного обучения в Википедии.
(Изображение автора), Входной текст для суммирования(Изображение автора), сводка сгенерирована с использованием алгоритма LexRankРезультат суммирования текста с использованием алгоритма LexRank:
(Изображение автора), Сводка сгенерирована с использованием алгоритма LSAРезультат суммирования текста с использованием алгоритма LSA:
В этой статье мы обсудили, как обобщать длинные текстовые документы с помощью пакета Python с открытым исходным кодом Sumy.Sumy предлагает различные алгоритмы, такие как LexRank, Luhn, LSA, TextRank, SumBasic и т. д., для суммирования текстовых документов. Сумы могут обобщать тексты из строковых переменных и файлов на диске.
Вы также можете прочитать о Text-Summarize, еще одной библиотеке Python с открытым исходным кодом для суммирования текстового документа.
[1] Сумская документация (19 мая 2019 г.): https://pypi.org/project/sumy/
Спасибо за прочтение
Алгоритм автоматизированной оценки суммирования для определения стратегий суммирования
.6 января 2016 г .; 11 (1): e0145809. doi: 10.1371/journal.pone.0145809. Электронная коллекция 2016.Принадлежности Расширять
Принадлежности
- 1 Кафедра искусственного интеллекта Факультет компьютерных наук и информационных технологий Малайского университета, 50603, Куала-Лумпур, Малайзия.
- 2 Институт информационных технологий Национальной академии наук Азербайджана, ул. Б. Вахабзаде, 9, AZ1141 Баку, Азербайджан.

Элемент в буфере обмена
Асад Абди и др. ПЛОС Один. .
Бесплатная статья ЧВК Показать детали Показать вариантыПоказать варианты
Формат АннотацияPubMedPMID
. 6 января 2016 г . ; 11 (1): e0145809.doi: 10.1371/journal.pone.0145809.
Электронная коллекция 2016.
; 11 (1): e0145809.doi: 10.1371/journal.pone.0145809.
Электронная коллекция 2016.Принадлежности
- 1 Кафедра искусственного интеллекта Факультет компьютерных наук и информационных технологий Малайского университета, 50603, Куала-Лумпур, Малайзия.
- 2 Институт информационных технологий Национальной академии наук Азербайджана, ул. Б. Вахабзаде, 9, AZ1141 Баку, Азербайджан.
Элемент в буфере обмена
Полнотекстовые ссылки Параметры отображения цитированияПоказать варианты
Формат АннотацияPubMedPMID
Абстрактный
Задний план: Реферирование — это процесс выделения важной информации из исходного текста. Стратегии обобщения являются основными когнитивными процессами в деятельности по обобщению. Поскольку обобщение может быть важным инструментом для улучшения понимания, оно привлекло внимание учителей к обучению написанию резюме посредством прямого обучения. Для этого им необходимо просмотреть и оценить резюме учащихся, и эти задачи требуют очень много времени. Таким образом, компьютерная оценка может помочь учителям более эффективно выполнять эту задачу.
Стратегии обобщения являются основными когнитивными процессами в деятельности по обобщению. Поскольку обобщение может быть важным инструментом для улучшения понимания, оно привлекло внимание учителей к обучению написанию резюме посредством прямого обучения. Для этого им необходимо просмотреть и оценить резюме учащихся, и эти задачи требуют очень много времени. Таким образом, компьютерная оценка может помочь учителям более эффективно выполнять эту задачу.
Дизайн/результаты: В этой статье предлагается алгоритм, основанный на сочетании семантических отношений между словами и их синтаксической композиции, для выявления стратегий обобщения, используемых учащимися при написании резюме.Инновационный аспект нашего алгоритма заключается в его способности идентифицировать стратегии суммирования на синтаксическом и семантическом уровнях. Эффективность алгоритма измеряется с точки зрения точности, отзыва и F-меры. Затем мы внедрили алгоритм для автоматизированной системы оценки подведения итогов, которую можно использовать для определения стратегий подведения итогов, используемых учащимися при написании резюме.
Затем мы внедрили алгоритм для автоматизированной системы оценки подведения итогов, которую можно использовать для определения стратегий подведения итогов, используемых учащимися при написании резюме.
Заявление о конфликте интересов
Конкурирующие интересы: Авторы заявили об отсутствии конкурирующих интересов.
Цифры
Рис. 1. Мера сходства предложений в разделе Удаление…
Рис. 1. Мера сходства предложений в стратегии удаления.
1. Мера сходства предложений в стратегии удаления.
Рис. 2. Использование метода определения местоположения среди…
Рис. 2. Использование метода определения местоположения среди 560 предложений.
Рис. 2. Использование метода определения местоположения среди 560 предложений.Рис. 3. Частота ключевых слов.
Рис. 3. Частота ключевых слов.
3. Частота ключевых слов.
Рис. 4. Использование ключевых слов в резюме.
Рис. 4. Использование ключевых слов в резюме.
Рис 4.Использование ключевых слов в резюме.Рис. 5. Использование слов заголовка среди…
Рис. 5. Использование слов заголовка среди резюме.
5. Использование слов заголовка среди резюме.
Рис. 6. Частота ключевых слов в…
Рис. 6. Частота ключевых слов в резюме.
Рис 6.Частота ключевых слов в резюме.Рис. 7. Количество объединенных исходных предложений…
Рис. 7. Количество исходных предложений, объединенных в каждое итоговое предложение.
7. Количество исходных предложений, объединенных в каждое итоговое предложение.
Рис. 8. Мера сходства предложений в предложении…
Рис. 8. Мера сходства предложений в стратегии комбинирования предложений.
Рис. 8.Мера сходства предложений в стратегии комбинирования предложений. Рис. 9. Процессы идентификации суммирования…
9. Процессы идентификации суммирования…
Рис. 9. Процессы выявления обобщающих стратегий.
Рис 9.Процессы выявления обобщающих стратегий.Рис. 10. Обзор разработки…
Рис. 10. Обзор разработки ISSLK.
Рис. 10.Обзор разработки ISSLK. Рис. 11. Модель вычисления схожести предложений.
11. Модель вычисления схожести предложений.
Рис. 11. Модель вычисления схожести предложений.
Рис 11.Модель вычисления сходства предложений.Все фигурки (11)
Похожие статьи
- Стратегии обобщения слабослышащих и нормально слышащих студентов.
Петерсон Л.Н., Френч Л. Петерсон Л.Н. и соавт.J Речь Слушать Res. 1988 Сентябрь; 31 (3): 327-37. doi: 10.1044/jshr.3103.327. J Речь Слушать Res. 1988 год. PMID: 3172750
- Нужны ли шестиклассникам стратегии процесса?
Торранс М.
, Фидальго Р., Робледо П.
Торранс М. и др.
Br J Educ Psychol. 2015 март;85(1):91-112. doi: 10.1111/bjep.12065. Epub 2015 13 января.
Br J Educ Psychol. 2015.
PMID: 25583519 - Сравнение моделей чтения-письма и успеваемости учащихся с трудностями чтения и без них.
Фидальго Р., Торранс М., Ариас-Гундин О., Мартинес-Коко Б. Фидальго Р. и др. Псикотема. 2014;26(4):442-8. doi: 10.7334/psicothema2014.23. Псикотема. 2014. PMID: 25340889
- Обобщение текста как помощь в принятии решений.
Уоркман Т.Е., Фисман М., Хёрдл Дж.Ф. Уоркман Т.Е. и др. БМС Мед Информ Децис Мак. 2012 23 мая; 12:41.дои: 10.1186/1472-6947-12-41. БМС Мед Информ Децис Мак. 2012. PMID: 22621674 Бесплатная статья ЧВК.
- Улучшение понимания пояснительного текста у студентов с LD: синтез исследования.
Гаджрия М., Джитендра А.К., Суд С., Сакс Г. Гаджрия М. и соавт. J Узнай об инвалидности. 2007 г., май-июнь; 40(3):210-25. дои: 10.1177/00222194070400030301. J Узнай об инвалидности. 2007.PMID: 17518214 Обзор.
 , Фидальго Р., Робледо П.
Торранс М. и др.
Br J Educ Psychol. 2015 март;85(1):91-112. doi: 10.1111/bjep.12065. Epub 2015 13 января.
Br J Educ Psychol. 2015.
PMID: 25583519
, Фидальго Р., Робледо П.
Торранс М. и др.
Br J Educ Psychol. 2015 март;85(1):91-112. doi: 10.1111/bjep.12065. Epub 2015 13 января.
Br J Educ Psychol. 2015.
PMID: 25583519
использованная литература
- Алигулиев РМ. Новая мера сходства предложений и метод извлечения на основе предложений для автоматического суммирования текста. Экспертные системы с приложениями. 2009; 36: 7764–72.
- Галгани Ф., Комптон П., Хоффманн А.ХАУСС: Постепенное создание суммирующего устройства, объединяющего несколько методов. Международный журнал человеко-компьютерных исследований. 2014; 72: 584–605.
- Ян Г. , Чен Н.С., Сутинен Э., Андерсон Т., Вен Д. Эффективность автоматического суммирования текста в контексте мобильного обучения. Компьютеры и образование. 2013;68:233–43.
- Ян Г.
- Абди А., Идрис Н., Алгулиев Р.М., Алигулиев Р.М.Обобщение нескольких документов на основе запросов с использованием лингвистических знаний и раскрытия слов в содержании. Мягкие вычисления. 2015: 1–17.
- Вестби К., Кулатта Б., Лоуренс Б., Холл-Кеньон К. Обобщение пояснительных текстов. Темы языковых расстройств. 2010;30:275–87.
 , Чен Н.С., Сутинен Э., Андерсон Т., Вен Д. Эффективность автоматического суммирования текста в контексте мобильного обучения. Компьютеры и образование. 2013;68:233–43.
, Чен Н.С., Сутинен Э., Андерсон Т., Вен Д. Эффективность автоматического суммирования текста в контексте мобильного обучения. Компьютеры и образование. 2013;68:233–43.Показать все 52 ссылки
Типы публикаций
- Поддержка исследований, не-U. С. Правительство
 С. Правительство
С. ПравительствоГрантовая поддержка
Это исследование поддерживается исследовательским грантом для аспирантов (PPP), грант №: PG184-2014B, Малайский университет (UM).
LinkOut — больше ресурсов
Полнотекстовые источники
Прочие литературные источники
Алфавит и Алгоритм
Резюме
Взлет и падение идентичных копий: цифровые технологии и формообразование от массовой кастомизации к массовому сотрудничеству.
Цифровые технологии изменили архитектуру — способы ее преподавания, практики, управления и регулирования. Но если цифровые технологии вызвали «сдвиг парадигмы» в архитектуре, то какая парадигма меняется? В Алфавит и Алгоритм Марио Карпо указывает на одну ключевую практику современности: изготовление идентичных копий. Карпо выделяет два примера идентичности, имеющих решающее значение для формирования архитектурной современности: в пятнадцатом веке Леон Баттиста Альберти изобрел архитектурный дизайн, согласно которому здание является точной копией проекта архитектора; а в девятнадцатом и двадцатом веках — массовое производство идентичных копий с механических мастер-моделей, матриц, отпечатков или форм.Карпо утверждает, что современной власти идентичности пришел конец с появлением цифровых технологий. Все цифровое изменчиво. В архитектуре это означает конец нотационных ограничений, механической стандартизации и альбертианского, авторского способа строительства по дизайну. Описывая взлет и падение парадигмы идентичности, Карпо сравнивает новые формы постиндустриального цифрового мастерства с ручным производством, культурами и технологиями вариаций, существовавшими до появления машинных идентичных копий.Карпо рассматривает развитие цифрового проектирования и строительства с начала 1990-х годов по настоящее время и предлагает новую повестку дня для архитектуры в эпоху изменчивых объектов и общего и совместного авторства.
Карпо выделяет два примера идентичности, имеющих решающее значение для формирования архитектурной современности: в пятнадцатом веке Леон Баттиста Альберти изобрел архитектурный дизайн, согласно которому здание является точной копией проекта архитектора; а в девятнадцатом и двадцатом веках — массовое производство идентичных копий с механических мастер-моделей, матриц, отпечатков или форм.Карпо утверждает, что современной власти идентичности пришел конец с появлением цифровых технологий. Все цифровое изменчиво. В архитектуре это означает конец нотационных ограничений, механической стандартизации и альбертианского, авторского способа строительства по дизайну. Описывая взлет и падение парадигмы идентичности, Карпо сравнивает новые формы постиндустриального цифрового мастерства с ручным производством, культурами и технологиями вариаций, существовавшими до появления машинных идентичных копий.Карпо рассматривает развитие цифрового проектирования и строительства с начала 1990-х годов по настоящее время и предлагает новую повестку дня для архитектуры в эпоху изменчивых объектов и общего и совместного авторства.
Мягкая обложка
26,95 долларов США Т ISBN: 9780262515801 184 стр. | 5,375 дюйма х 8 дюймов 13 ч/б илл.Авторов
Марио Карпо
Марио Карпо — профессор истории и теории архитектуры Рейнера Бэнэма в Бартлетте Университетского колледжа Лондона.Он является автором книг «Архитектура в эпоху книгопечатания: устная речь, письмо, типографика и печатные изображения в истории архитектурной теории» и «Алфавит и алгоритм» (оба опубликованы издательством MIT Press) и других книг.Обобщение текста при обработке естественного языка: алгоритмы, методы и задачи
Создание сводки из заданного фрагмента контента — очень абстрактный процесс, в котором участвуют все. Автоматизация такого процесса может помочь проанализировать большой объем данных и помочь людям лучше использовать свое время для принятия важных решений.При огромном объеме медиа можно быть очень эффективным, сократив ненужную информацию вокруг наиболее важной информации. Мы уже начали видеть текстовые сводки в Интернете, которые генерируются автоматически.
Автоматизация такого процесса может помочь проанализировать большой объем данных и помочь людям лучше использовать свое время для принятия важных решений.При огромном объеме медиа можно быть очень эффективным, сократив ненужную информацию вокруг наиболее важной информации. Мы уже начали видеть текстовые сводки в Интернете, которые генерируются автоматически.
Если вы часто посещаете Reddit, вы могли видеть, что «бот Autotldr» регулярно помогает Redditors, резюмируя связанные статьи в данном сообщении. Он был создан всего в 2011 году и уже сэкономил тысячи человеко-часов. Существует рынок надежных текстовых сводок, о чем свидетельствует тенденция приложений, которые делают именно это, таких как Inshorts (обобщение новостей до 60 слов или меньше) и Blinkist (обобщение книг).
Автоматическое суммирование текста Таким образом, это захватывающая, но сложная граница в Обработка естественного языка (NLP) и Машинное обучение (ML). Текущие разработки в области автоматического реферирования текста обязаны исследованиям в этой области с 1950-х годов, когда была опубликована статья Ханса Петера Луна под названием «Автоматическое создание литературных рефератов».
Текущие разработки в области автоматического реферирования текста обязаны исследованиям в этой области с 1950-х годов, когда была опубликована статья Ханса Петера Луна под названием «Автоматическое создание литературных рефератов».
В этом документе описано использование таких функций, как частота слов и фраз, для извлечения основных предложений из документа.За этим последовало еще одно критическое исследование, проведенное Гарольдом П. Эдмундсоном в конце 1960-х годов, в котором подчеркивалось наличие ключевых слов, слов, используемых в заголовке, появляющихся в тексте, и расположение предложений для извлечения значимых предложений из документа.
Теперь, когда мир добился успехов в области машинного обучения и опубликовал новые исследования в этой области, автоматическое суммирование текста вот-вот станет распространенным инструментом для взаимодействия с информацией в эпоху цифровых технологий.
Рекомендуем прочитать: Зарплата инженера НЛП в Индии
Существует два основных подхода к обобщению текста в НЛП
Обобщение текста в НЛП 1. Обобщение на основе извлечения
Обобщение на основе извлечения Как следует из названия, этот метод основан на простом извлечении ключевых фраз из документа. Затем следует объединение этих ключевых фраз для формирования последовательного резюме.
2.Резюме на основе рефератовЭтот метод, в отличие от извлечения, основан на возможности перефразировать и сокращать части документа. Когда такая абстракция выполняется правильно в задачах глубокого обучения, можно быть уверенным, что грамматика непротиворечива. Но этот дополнительный уровень сложности достигается за счет того, что его сложнее разрабатывать, чем извлечение.
Есть еще один способ получить более качественные сводки. Этот подход называется вспомогательным суммированием, которое предполагает совместную работу человека и программного обеспечения.Это тоже доступно в 2 разных вкусах
- Автоматизированное резюмирование человеком : методы извлечения выделяют отрывки-кандидаты для включения, которые человек может добавлять или удалять текст.
- Обобщение машин с помощью человека : человек просто редактирует вывод программы.

Помимо основных подходов к резюмированию текста, существуют и другие основания, по которым классифицируются рефераторы текста. Вот эти заголовки категорий:
3.Обобщение одного и нескольких документовОтдельные документы полагаются на связность и нечастое повторение фактов для создания резюме. С другой стороны, обобщение нескольких документов увеличивает вероятность повторения избыточной информации.
4. Ориентировочные и информативныеТаксономия сводок зависит от конечной цели пользователя. Например, в обзорах ориентировочного типа можно было бы ожидать высокого уровня статьи. Принимая во внимание, что в информативном обзоре можно ожидать большей фильтрации тем, чтобы позволить читателю детализировать сводку.
5. Длина и тип документа Длина вводимого текста сильно влияет на способ суммирования.
Крупнейшие сводные наборы данных, такие как отдел новостей Cornell, сосредоточены на новостных статьях, которые в среднем содержат около 300–1000 слов. Извлекающие сумматоры относительно хорошо справляются с такими длинами. Многостраничный документ или глава книги могут быть адекватно резюмированы только с помощью более продвинутых подходов, таких как иерархическая кластеризация или анализ дискурса.
Кроме того, жанр текста также влияет на резюмирующего. Методы, которые будут подытоживать техническую документацию, будут радикально отличаться от методов, которые могут быть лучше приспособлены для подведения итогов финансового отчета.
В этой статье мы сосредоточимся на дальнейших деталях метода суммирования извлечения.
Алгоритм PageRank Этот алгоритм помогает поисковым системам, таким как Google, ранжировать веб-страницы. Разберем алгоритм на примере.Предположим, у вас есть четыре веб-страницы с разными уровнями связи между ними. Один может не иметь связей с тремя другими; один может быть связан с двумя другими, один может быть связан только с одним и так далее.
Один может не иметь связей с тремя другими; один может быть связан с двумя другими, один может быть связан только с одним и так далее.
Затем мы можем смоделировать вероятность перехода с одной страницы на другую, используя матрицу с n строками и столбцами, где n — количество веб-страниц. Каждый элемент в матрице будет представлять вероятность перехода с одной веб-страницы на другую. Назначая правильные вероятности, можно многократно обновлять такую матрицу, чтобы получить рейтинг веб-страницы.
Читайте также: Проект НЛП и темы
Алгоритм TextRankМы исследовали алгоритм PageRank, чтобы показать, как тот же алгоритм можно использовать для ранжирования текста вместо веб-страниц. Это можно сделать, изменив перспективу, заменив ссылки между страницами на сходство между предложениями и используя матрицу стиля PageRank в качестве показателя сходства.
Реализация алгоритма TextRank
Необходимые библиотеки
Ниже приводится объяснение кода метода суммирования извлечения:
Этап 1
Объединить весь текст исходного документа в один цельный блок текста. Это делается для того, чтобы обеспечить условия, облегчающие выполнение шага 2.
Это делается для того, чтобы обеспечить условия, облегчающие выполнение шага 2.
Этап 2
Мы предоставляем условия, определяющие предложение, такие как поиск знаков препинания, таких как точка (.), вопросительный знак (?) и восклицательный знак (!). Получив это определение, мы просто разбиваем текстовый документ на предложения.
Этап 3
Теперь, когда у нас есть доступ к отдельным предложениям, мы находим векторные представления (вложения слов) каждого из этих предложений.Именно сейчас мы должны понять, что такое векторные представления. Вложения слов — это тип представления слов, который обеспечивает математическое описание слов со схожими значениями. На самом деле это целый класс методов, которые представляют слова как векторы с действительными значениями в предопределенном векторном пространстве.
Каждое слово представлено действительным вектором, который имеет много измерений (иногда более 100). Представление распределения основано на использовании слов и, таким образом, позволяет словам, используемым сходным образом, иметь схожие описания. Это позволяет нам естественным образом улавливать значения слов по их близости к другим словам, представленным в виде самих векторов.
Это позволяет нам естественным образом улавливать значения слов по их близости к другим словам, представленным в виде самих векторов.
В этом руководстве мы будем использовать глобальные векторы представления слов (GloVe). gloVe — это алгоритм распределенного представления слов с открытым исходным кодом, разработанный Пеннингтоном в Стэнфорде. Он сочетает в себе черты двух семейств моделей, а именно глобальной матричной факторизации и методов локального контекстного окна.
Этап 4
Когда у нас есть векторное представление для наших слов, мы должны расширить процесс, чтобы представить целые предложения в виде векторов.Для этого мы можем получить векторные представления терминов, составляющих слова в предложении, а затем среднее значение этих векторов, чтобы получить объединенный вектор для предложения.
Этап 5
На данный момент у нас есть векторное представление для каждого отдельного предложения. Теперь полезно количественно определить сходство между предложениями, используя подход косинусного сходства. Затем мы можем заполнить пустую матрицу косинусным сходством предложений.
Затем мы можем заполнить пустую матрицу косинусным сходством предложений.
Этап 6
Теперь, когда у нас есть матрица, заполненная косинусными сходствами между предложениями. Мы можем преобразовать эту матрицу в граф, в котором узлы представляют предложения, а ребра представляют сходство между предложениями. Именно на этом графике мы будем использовать удобный алгоритм PageRank для ранжирования предложений.
Шаг 7
Теперь мы расположили все предложения в статье в порядке важности.Теперь мы можем извлечь первые N (скажем, 10) предложений, чтобы создать сводку.
Чтобы найти код такого метода, таких проектов много на Github; эта статья, с другой стороны, помогает развить понимание того же самого.
Отъезд: Эволюция языкового моделирования в современной жизни
Методы оценки Важным фактором точной настройки таких моделей является наличие надежного метода оценки качества получаемых сводок. Это требует хороших методов оценки, которые можно в целом разделить на следующие:
Это требует хороших методов оценки, которые можно в целом разделить на следующие:
- Внутренняя и внешняя оценка :
Внутренняя: такая оценка проверяет саму систему суммирования. Они в основном оценивают связность и информативность резюме.
Внешний: такая оценка проверяет суммирование на основе того, как оно влияет на какую-либо другую задачу. Это может проверить влияние обобщения на такие задачи, как оценка релевантности, понимание прочитанного и т. д.
- Интертекстуальные и внутритекстовые :
Интертекстуальный: Такие оценки сосредоточены на сравнительном анализе нескольких систем обобщения.
Внутритекстовый: такие оценки оценивают результат работы конкретной системы обобщения.
- Зависящие от домена и независимые от домена :
Независимый от домена: Эти методы обычно применяют наборы общих функций, которые можно сфокусировать на идентификации сегментов текста с богатым содержанием информации.
Специфичный для домена: Эти методы используют доступные знания, специфичные для домена в тексте. Например, текстовое обобщение медицинской литературы требует использования источников медицинских знаний и онтологий.
- Качественная оценка резюме :
Основным недостатком других методов оценки является то, что они требуют справочных сводок, чтобы можно было сравнить выходные данные автоматических сводок с моделью. Это делает задачу оценки сложной и дорогостоящей.Ведется работа по созданию корпуса статей/документов и соответствующих им резюме для решения этой проблемы.
Проблемы суммирования текстаНесмотря на хорошо разработанные инструменты для создания и оценки резюме, остаются проблемы с поиском надежного способа для составителей текстов понять, что важно и актуально.
Как уже говорилось, векторное представление и матрицы подобия пытаются найти ассоциации слов, но у них все еще нет надежного метода для определения наиболее важных предложений.
Еще одной проблемой при обобщении текста является сложность человеческого языка и того, как люди выражают себя, особенно в письменном тексте. Язык состоит не только из длинных предложений с прилагательными и наречиями для описания чего-либо, но и из относительных предложений, приложений и т. д. Такие идеи могут добавить ценную информацию, но не помогают в установлении основной сути информации, которая должна быть включена в резюме.
«Проблема анафоры» — еще один барьер в реферировании текста.В языке мы часто заменяем подлежащее в разговоре его синонимами или местоимениями. Понимание того, какое местоимение заменяет какой термин, является «проблемой анафоры».
«Проблема катафоры» — проблема, противоположная проблеме анафоры. В этих двусмысленных словах и объяснениях конкретный термин используется в тексте до введения самого термина.
Заключение Область реферирования текста переживает быстрый рост, и разрабатываются специализированные инструменты для решения более целенаправленных задач реферирования. Поскольку программное обеспечение с открытым исходным кодом и пакеты для встраивания слов становятся широко доступными, пользователи расширяют возможности использования этой технологии.
Поскольку программное обеспечение с открытым исходным кодом и пакеты для встраивания слов становятся широко доступными, пользователи расширяют возможности использования этой технологии.
Автоматическое суммирование текста — это инструмент, который обеспечивает качественный скачок в производительности труда людей за счет упрощения огромного объема информации, с которой люди ежедневно взаимодействуют. Это не только позволяет людям сократить количество необходимого чтения, но и высвобождает время для чтения и понимания письменных работ, которые иначе упускаются из виду. Это только вопрос времени, когда такие обобщатели настолько хорошо интегрируются, что создают сводки, неотличимые от написанных людьми.
Если вы хотите улучшить свои навыки НЛП, вам нужно получить доступ к этим проектам НЛП. Если вам интересно узнать больше о машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий, IIIT- Статус B Alumni, 5+ практических проектов и помощь в трудоустройстве в ведущих фирмах.
Каковы виды использования НЛП?
НЛП или обработка естественного языка, одна из самых сложных и интересных современных технологий, используется по-разному.Его лучшие приложения включают в себя: автоматическую коррекцию слов, автоматическое предсказание, чат-боты и голосовые помощники, распознавание речи в виртуальных помощниках, анализ тональности человеческой речи, фильтрацию электронной почты и спама, перевод, аналитику социальных сетей, целевую рекламу, суммирование текста и сканирование резюме для поиска. рекрутинг, в том числе. Дальнейшие достижения в НЛП, приводящие к появлению таких концепций, как понимание естественного языка (NLU), помогают достичь более высокой точности и гораздо лучших результатов при выполнении сложных задач.
Должен ли я изучать математику, чтобы изучать НЛП?
Благодаря обилию ресурсов, доступных как в автономном режиме, так и в Интернете, теперь легче получить доступ к учебным материалам, предназначенным для изучения НЛП. Эти учебные ресурсы посвящены конкретным концепциям этой обширной области, называемой НЛП, а не более широкой картине. Но если вам интересно, является ли математика частью какой-либо концепции НЛП, то вы должны знать, что математика является неотъемлемой частью НЛП.Математика, особенно теория вероятностей, статистика, линейная алгебра и исчисление, являются фундаментальными столпами алгоритмов, лежащих в основе НЛП. Полезно иметь общее представление о статистике, чтобы вы могли опираться на нее по мере необходимости. Тем не менее, невозможно изучить обработку естественного языка, не углубляясь в математику.
Эти учебные ресурсы посвящены конкретным концепциям этой обширной области, называемой НЛП, а не более широкой картине. Но если вам интересно, является ли математика частью какой-либо концепции НЛП, то вы должны знать, что математика является неотъемлемой частью НЛП.Математика, особенно теория вероятностей, статистика, линейная алгебра и исчисление, являются фундаментальными столпами алгоритмов, лежащих в основе НЛП. Полезно иметь общее представление о статистике, чтобы вы могли опираться на нее по мере необходимости. Тем не менее, невозможно изучить обработку естественного языка, не углубляясь в математику.
Какие методы НЛП используются для извлечения информации?
В наш цифровой век произошел массовый всплеск генерации неструктурированных данных, в основном в виде аудио, изображений, видео и текстов из различных каналов, таких как платформы социальных сетей, жалобы клиентов и опросы.НЛП помогает извлекать полезную информацию из объемов неструктурированных данных, что может помочь бизнесу. Существует пять распространенных методов НЛП, которые используются для извлечения полезных данных, а именно: распознавание именованных сущностей, суммирование текста, анализ настроений, анализ аспектов и моделирование темы. В NLP есть много других методов извлечения данных, но эти используются чаще всего.
Существует пять распространенных методов НЛП, которые используются для извлечения полезных данных, а именно: распознавание именованных сущностей, суммирование текста, анализ настроений, анализ аспектов и моделирование темы. В NLP есть много других методов извлечения данных, но эти используются чаще всего.
Возглавьте технологическую революцию, управляемую искусственным интеллектом
ДИПЛОМ PG ПО МАШИННОМУ ОБУЧЕНИЮ И ИСКУССТВЕННОМУ ИНТЕЛЛЕКТУ
Чтобы устранить корпоративную предвзятость, пусть алгоритмы суммируют прибыль | Техас МакКомбс | Большие идеи
Новое исследование показало, что сводки корпоративных доходов, созданные с помощью алгоритмов, имеют преимущества по сравнению с отчетами, написанными руководством.
На основе исследования Брайана Уайта
Отчеты о доходах компаний имеют решающее значение для принятия инвесторами решений о покупке и продаже акций. Но реагируют ли инвесторы по-другому, когда эти релизы пишет компьютер?
Но реагируют ли инвесторы по-другому, когда эти релизы пишет компьютер?
Отчеты о доходах, созданные с помощью алгоритмов, используют статистические методы для определения наиболее важных предложений в раскрытии информации, которые затем используются для формирования сводки. По словам Брайана Уайта, адъюнкт-профессора бухгалтерского учета в Texas McCombs, такие сводки ограничивают человеческую предвзятость и в то же время фиксируют всю важную информацию.Они также делают инвесторов более уверенными в своих решениях.
В новой статье Уайт и его соавторы — Эдди Кардиналс из Тилбургского университета и Стефан Холландер из KU Leuven — сравнили поведение инвесторов при представлении основанного на алгоритме обобщения корпоративной информации, в частности отчетов о прибылях и убытках, с резюме, написанным управленческими командами. . Уайт рассказал об исследовании и его потенциальном воздействии.
Что вызвало ваш исследовательский интерес к корпоративным отчетам? Компании раскрывают больше информации, чем когда-либо прежде. Что-то обязательное, что-то добровольное. Компании все чаще публикуют краткие отчеты о своих раскрытиях — ярким примером являются отчеты о прибылях и убытках. Неудивительно, что когда у вас много разглашаемой информации, вы склонны публиковать резюме, потому что внимание людей ограничено. Резюме делает информацию более удобоваримой для людей.
Что-то обязательное, что-то добровольное. Компании все чаще публикуют краткие отчеты о своих раскрытиях — ярким примером являются отчеты о прибылях и убытках. Неудивительно, что когда у вас много разглашаемой информации, вы склонны публиковать резюме, потому что внимание людей ограничено. Резюме делает информацию более удобоваримой для людей.
Фирмы имеют стимулы и возможность по своему усмотрению вносить искажения в эти сводки. Таким образом, по сравнению с основным текстом, который они резюмируют, менеджеры фирм могут выбирать хорошие новости и информацию, которые показывают их фирму в лучшем свете.
Это заставило нас задуматься, может ли быть роль того, что мы называем автоматическим суммированием или автоматическим суммированием на основе алгоритма. Он может предоставить полезную сводную информацию — играя ту роль, которую хотят фирмы, — но с меньшей предвзятостью, потому что они относительно нейтральны.
Как вы анализировали корпоративные сводки? Что ты узнал?Мы рассмотрели отчеты о прибылях и убытках, потому что они, как правило, являются одним из наиболее заметных, частых и влиятельных раскрытий информации.
Мы попросили независимого эксперта составить сводку по нескольким отчетам о прибылях и убытках.Затем мы сравнили наши автоматические сводки и фактическую сводку руководства фирмы с экспертной сводкой. К своему удивлению, мы обнаружили, что автоматическое резюме больше похоже на экспертное заключение, чем резюме руководства фирмы на экспертное заключение. Это говорит нам о нескольких вещах. Во-первых, эти алгоритмы хорошо справляются с подведением итогов так же, как и эксперт. Это также говорит нам о том, что руководство фирмы делает что-то другое: они дают заключение, которое гораздо более позитивно, чем независимый эксперт или алгоритм.
Затем мы провели контролируемый лабораторный эксперимент, чтобы проверить влияние этих различных типов сводок на суждения отдельных инвесторов: участники предоставили оценки стоимости акционерного капитала, потенциального роста доходов в будущем, благоприятности публикации данных о доходах и рисках. Результаты по каждому из этих показателей указывали в одном направлении. Другими словами, они более благосклонно отреагировали на положительно предвзятое резюме руководства. Мы обнаружили, что резюме действительно имеет значение.
Участники исследования не знали, были ли резюме написаны алгоритмом или руководством.Как они реагировали на каждый тип?Инвесторы, кажется, верят в позитивную оценку руководства в резюме. Когда они увидели резюме руководства, они более позитивно отреагировали на информацию. Когда они увидели автоматическое резюме, они отреагировали менее позитивно. В среднем это ничем не отличается от того, как отреагируют инвесторы, если увидят отчет о доходах без сводки. Но, что очень важно, мы по-прежнему видим преимущество автоматической сводки: мы также измерили их уверенность в своих суждениях о принятии каких-либо действий, и они были более уверены, когда получали отчет о доходах с автоматической сводкой, чем без сводки.
Почему?У нас нет прямых доказательств того, почему автоматические сводки сделали их более уверенными, но я предполагаю, что это потому, что сводки лучше соответствовали основному раскрытию информации. Наблюдение за этим совпадением, вероятно, придает им больше уверенности в своих выводах.
Основываясь на вашем исследовании, что дальше с автоматическими сводками?В целом, мы остались довольны тем, что эти основанные на алгоритмах сводки могут предоставлять информацию, столь же полезную — без привносимой положительной предвзятости — как и сводки руководства.
Комиссия по ценным бумагам и биржам, в частности, проявила интерес к методам обобщения. SEC осознает, что эти сводки представляют собой палку о двух концах, когда они подготовлены руководством. Они полезны, но могут быть и предвзятыми. Мы хотим предоставить некоторые первоначальные доказательства того, что автоматические сводки могут быть потенциально полезными в качестве альтернативы. Мы достаточно осторожны в статье, чтобы не сказать: «Сейчас мы должны ввести автоматические сводки для всех фирм», но они выглядят многообещающе.
« Автоматическое суммирование отчетов о прибылях и убытках: атрибуты и влияние на суждения инвесторов », опубликованный в Интернете в Review of Accounting Studies.
Рассказ Слоана Уятта
Главный алгоритм в кратком изложении Педро Домингоса
Тот научно-фантастический момент, которого вы так долго ждали, настал: некоторые машины уже учатся самостоятельно и даже учатся программировать себя. Этот живой и нужный отчет профессора компьютерных наук Педро Домингоса показывает, что эта трансформация делает для науки и что она сделает для человеческого общества.Машинное обучение сложное, а тема концептуально насыщенная, но Домингос объясняет это с явной любовью к своей теме. Он подробно описывает, как компьютеры стали учиться самостоятельно; как работают алгоритмы обучения; и как работают конкурирующие теории мышления и обучения. Его яркое письмо, анекдоты и примеры помогают сделать тему более доступной, чем вы могли бы ожидать (хотя читателю, возможно, придется проделать тяжелую работу). Домингос многое объясняет, но иногда слишком полагается на свои иллюстрации. getAbstract рекомендует его трактат всем, кто интересуется тем, как компьютеры революционизируют общество, «машинным обучением» или развитием науки.
Лауреат премии SIGKDD Innovation Award, Педро Домингос — профессор компьютерных наук в Вашингтонском университете и член Ассоциации по развитию искусственного интеллекта. Читатели могут загрузить учебный курс MLN «Алхимия» на сайте alchemy.cs.washington.edu.
«Революция машинного обучения»
Вы взаимодействуете с «машинным обучением» каждый день. Когда Netflix предлагает фильм или поисковая система выполняет ваш запрос, это машинное обучение в действии.Это революционно. На протяжении всей истории, если вы хотели, чтобы машина что-то делала, вы должны были построить ее именно для этого. Для компьютеров вы написали подробный алгоритм, объясняющий, как он должен делать то, что вы хотите.
«Алгоритмы машинного обучения» или «обучающиеся» работают по-другому. Компьютеризированные учащиеся догадываются сами. Компьютеры, которые являются «обучающимися», могут «программировать себя». Дайте им данные, и они узнают. Чем больше у них данных, тем эффективнее они думают.