Какими бывают виды подчинительной связи слов в словосочетаниях
Словосочетание и предложение – синтаксические конструкции, составляющие стройную систему любого языка. Структурные и функциональные особенности словосочетаний и предложений изучает синтаксис – один из разделов грамматики.
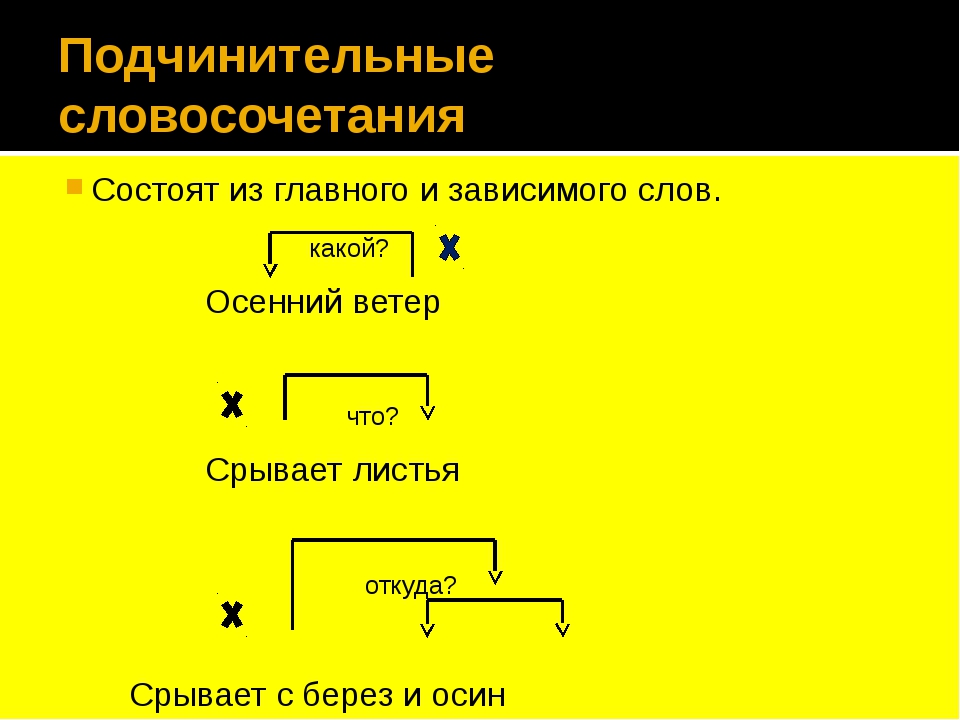
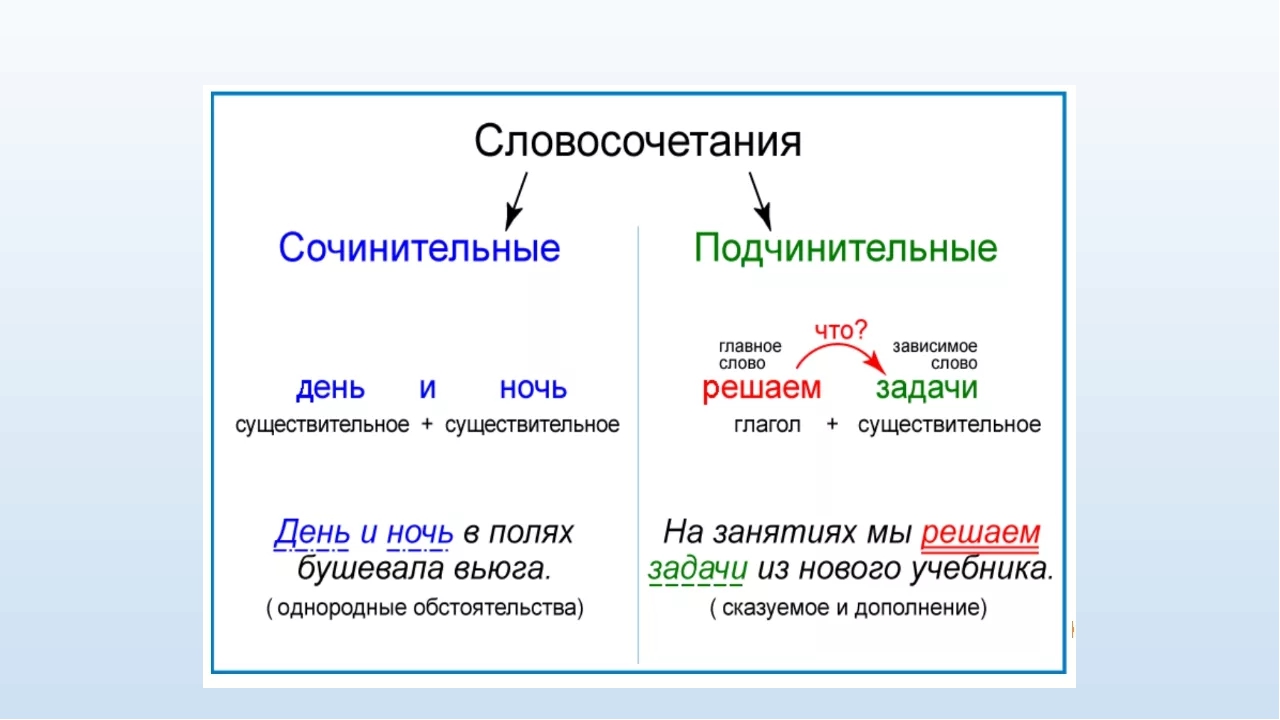
Что же такое словосочетание и предложение? Словосочетание – это два и более значимых слова, скрепленных подчинительной связью. Предложение же – сложная единица языка, основная функция которой коммуникативная, следовательно, она оформлена интонационно и имеет определенные формы наклонения и времени. Отдельные слова в предложении имеют определенную смысловую связь между собой, за счет которой, собственно, и складывается их коммуникативная и смысловая функция. Такие связи называются синтаксическими. Они, в свою очередь, подразделяются на сочинительную и подчинительную. В предложениях встречаются оба вида связи, в словосочетании — только одна — подчинительная (как указывалось выше).
Подчинительная связь в словосочетаниях
В самом названии «подчинительная» ярко прослеживается суть этой грамматической связи, где два слова всегда занимают разные позиции: одно выступает в роли главного, а другое – зависимого, подчиненного ему, и его грамматические признаки (число, падеж и род) полностью или частично соответствуют и определяются главным словом. В зависимости от степени подчиненности второстепенного слова главному существуют разные виды подчинительной связи.
В зависимости от степени подчиненности второстепенного слова главному существуют разные виды подчинительной связи.
Согласование
Грамматические признаки зависимого слова при данном виде синтаксической связи полностью соответствуют и определяются значимым, главным словом. Например: каменный цветок, большой город (именит. пад., м. р., ед. ч.), перистые облака, золотые города (мн. ч., именит. пад.), множество красивых людей (родит. пад., мн. ч.). Причем, если главное слово меняет свою грамматическую форму, она меняется, соответственно, и у подчиненного. Например, осенний лист (именит. п.), осеннего листа (родит. п.), осенним листом (творит. п.) и т.д.
В качестве зависимого компонента при согласовании в словосочетаниях способны выступать различные части речи – прилагательные (красивое платье), причастия (прыгающий мяч), порядковые числительные (второй класс), количественные числительные (с двумя комнатами). При этом очень важно заметить, что такие виды подчинительной связи, как согласование, невозможны с глаголами, наречиями, деепричастиями, т. е. частями речи, не имеющими ни рода, ни числа, ни падежа. Существительное также при согласовании всегда выступает только в качестве определяющего, главного слова и ни в коем случае не может быть зависимым, ведь оно не изменяется по родам.
е. частями речи, не имеющими ни рода, ни числа, ни падежа. Существительное также при согласовании всегда выступает только в качестве определяющего, главного слова и ни в коем случае не может быть зависимым, ведь оно не изменяется по родам.
В словосочетании согласование между его компонентами может быть полным, совпадающим по всем грамматическим признакам, либо частичным, когда совпадение происходит по одному или двум признакам. Например: летучий голландец, красная жара (полное согласование), наша почтальон (частичное).
Следующие виды подчинительной связи в словосочетании строятся по иным грамматическим принципам.
Управление
В управлении подчиненное слово ставится в косвенном падеже с предлогом или без, что определяется смысловым значением главного компонента словосочетания. Например: бегать по комнате (зависимое слово «по комнате» стоит в предложном падеже), смотреть фильм (зависимое слово «фильм» стоит в винительном падеже), встретились с интересными людьми (творительный падеж с предлогом).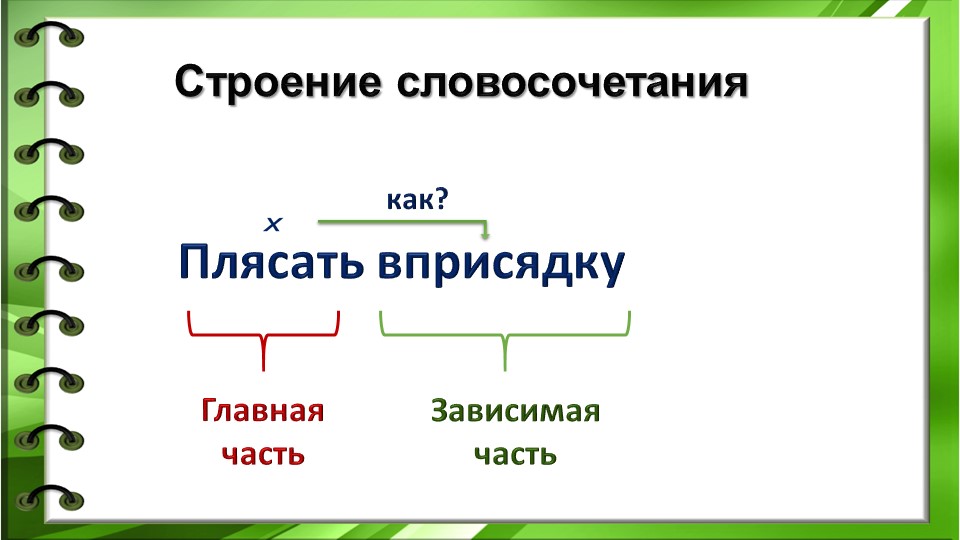 Нужно отметить, что в отличие от согласования в управлении при изменении формы основного слова зависимое не меняется. Например: петь песню — поющий песню — пел песню – спою песню.
Нужно отметить, что в отличие от согласования в управлении при изменении формы основного слова зависимое не меняется. Например: петь песню — поющий песню — пел песню – спою песню.
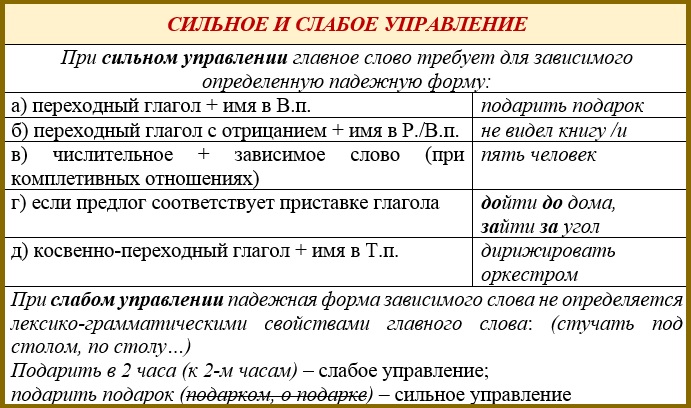
В управлении в качестве главных слов могут выступать глаголы, существительные или наречия. Такие виды подчинительной связи называются приглагольным, приименным или принаречным управлением. Например: читать стихи, тарелка супа, наедине со всеми. Управление может быть предложным (с участием предлога) или беспредложным, а также сильным, когда лексико-грамматическая форма главного слова обязательно предполагает рядом с собой зависимый компонент (например: преданность друзьям, отправленное письмо), или слабым, когда такая зависимость не прослеживается (например: письмо в конверте, ваза на столе).
Примыкание
Виды подчинительной связи в словах, при которых зависимое слово определяется основным только по смысловому значению, называется примыканием. Здесь подчиненное слово может быть наречием (быстро читает), деепричастием (делать спустя рукава), сравнительным прилагательным или наречием (мех пушистее, закинуть дальше), притяжательными местоимениями (ее комната).
Как определить виды подчинительной связи
Чтобы верно установить вид связи, для начала нужно определить главное и подчиненное слова и часть речи этого зависимого компонента. Неизменяемые части речи участвуют в примыкании. Если при изменении основного слова меняет свои грамматические признаки и подчиненное, то это согласование. Наконец, нужно задать вопрос от главного к зависимому слову и, если этот вопрос относится к какому-либо косвенному падежу, то это управление.
Как определить вид подчинительной связи в словосочетании. Смотреть что такое «подчинительная связь» в других словарях
B3 — типы подчинительной связи
Комментарии преподавателя
Возможные трудности | Добрые советы |
Бывает трудно определить тип связи слов в словосочетаниях существительное + существительное , где зависимое слово отвечает на вопрос какой? Например: умница дочка, город Москва, лист берёзы, дом у дороги. | Попробуйте изменить главное слово, употребив его в форме множественного числа или косвенного падежа, например, родительного. Если зависимое существительное при этом изменяется, то есть согласуется с главным словом в числе и падеже (умницы дочки, города Москвы ), то тип связи слов в этом словосочетании — согласование. |
Иногда род, число и падеж существительных, связанных с помощью управления, совпадают, поэтому в таких случаях можно спутать управление с согласованием, например: у директора колледжа. | Чтобы определить тип связи слов в данном словосочетании, нужно изменить форму главного слова. Если зависимое слово изменяется вслед за главным, то это словосочетание с согласованием: у красавицы артистки — красавице артистке . |
Некоторые наречия, образованные от существительных и других частей речи, можно спутать с соответствующими частями речи и допустить ошибку в определении типа связи, например: поехать летом — восхищаться летом, сварить вкрутую — в крутую передрягу. | Для определения типа связи в такой ситуации необходимо правильно определить часть речи, которой является сомнительное слово. Если сомнительное слово написано слитно с бывшим предлогом или через дефис, то это наречие: вкрутую, вдаль, навстречу, по-старому. |
Иногда трудно установить, какое слово в словосочетании является главным, а какое – зависимым, например: | В словосочетаниях прилагательное + наречие главным словом всегда является прилагательное, а зависимым – наречие, которое обозначает признак признака . |

 Если зависимое слово не изменяется, то это словосочетание с управлением: у директора колледжа — директору колледжа.
Если зависимое слово не изменяется, то это словосочетание с управлением: у директора колледжа — директору колледжа. 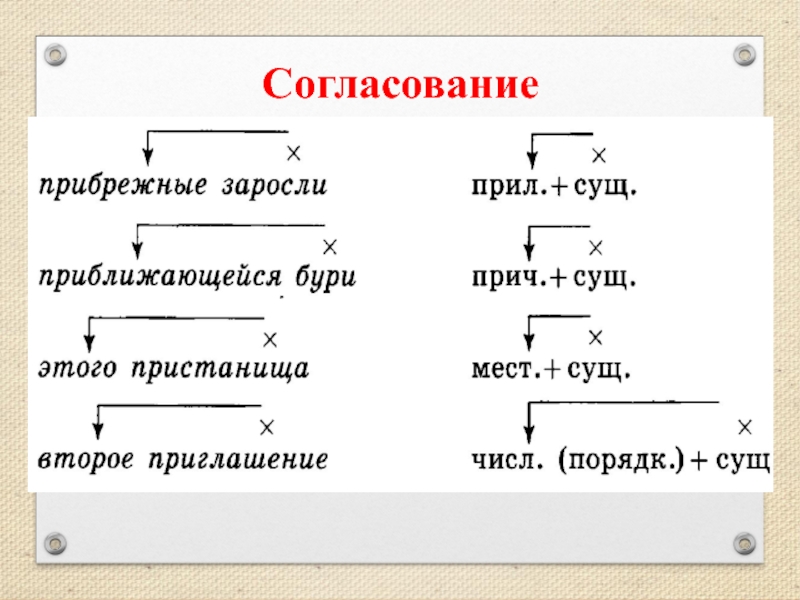
Синтаксис. Понятие о предложении и словосочетании
Синтаксис — это раздел грамматики, в котором изучается строение и значение словосочетаний и предложений .
Предложение
—
это основная единица синтаксиса, выражающая мысль,
содержащая сообщение, вопрос либо побуждение. Предложение обладает
интонационной и смысловой законченностью, т. е. оформляется как отдельное
высказывание.
Предложение обладает
интонационной и смысловой законченностью, т. е. оформляется как отдельное
высказывание.
На улице холодно (сообщение).
Когда отходит поезд? (вопрос).
Закройте, пожалуйста, окно! (побуждение).
Предложение имеет грамматическую основу (подлежащее и сказуемое). По количеству грамматических основ предложения делятся на простые (одна грамматическая основа) и сложные (более одной грамматической основы).
Утренний туман над городом еще не рассеялся, хотя и поредел (простое предложение).
Тот, который был с золотым зубом, оказался официантом, а не жуликом (сложное предложение).
По характеру грамматической основы простые предложения бывают двусоставные и односоставные .
По полноте своей реализации предложения делятся на полные и неполные .
По цели высказывания предложения бывают повествовательные , побудительные и вопросительные .
По интонации предложения бывают восклицательные и невосклицательные
.
Словосочетанием называются два или несколько слов, объединенных по смыслу и грамматически (с помощью подчинительной связи ).
Словосочетание состоит из главного и зависимого слов. От главного слова можно задать вопрос к зависимому.
Зайти (куда?) в глушь.
Зарядка (чего?) аккумулятора.
Словосочетание, как и слово, называет предметы, действия и их признаки, но более конкретно, точно, потому что зависимое слово конкретизирует смысл главного. Сравним:
Утро — летнее утро;
Спать — долго спать.
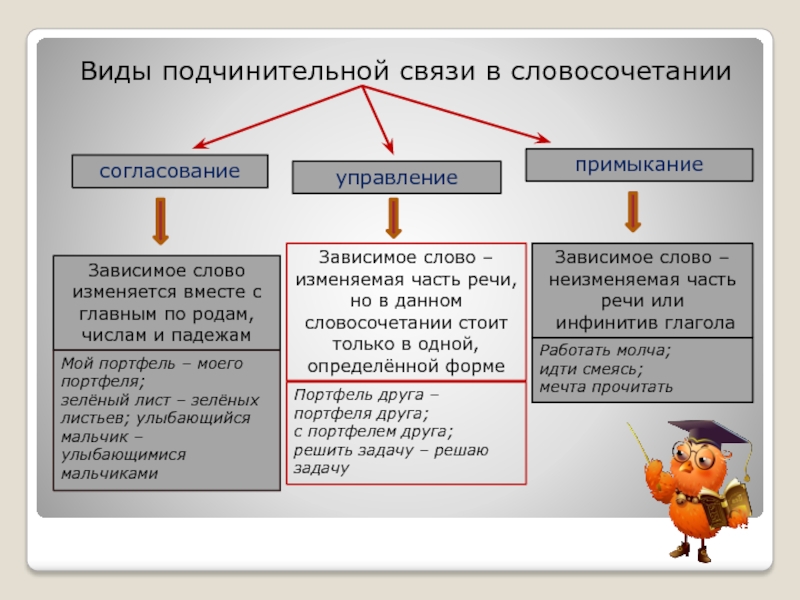
Между главным и зависимым словом в словосочетании возможны три вида подчинительной связи: согласование , управление и примыкание .
Имеющуюся между двумя или более неравноправными синтаксически словами в предложении или словосочетании, в случае, когда одно из них считается главным, а, соответственно, другое — зависимым. Подчинительная связь в предложении существует между главным и придаточными предложениями. В данной статье речь пойдет о словосочетании и основных способах подчинительной связи.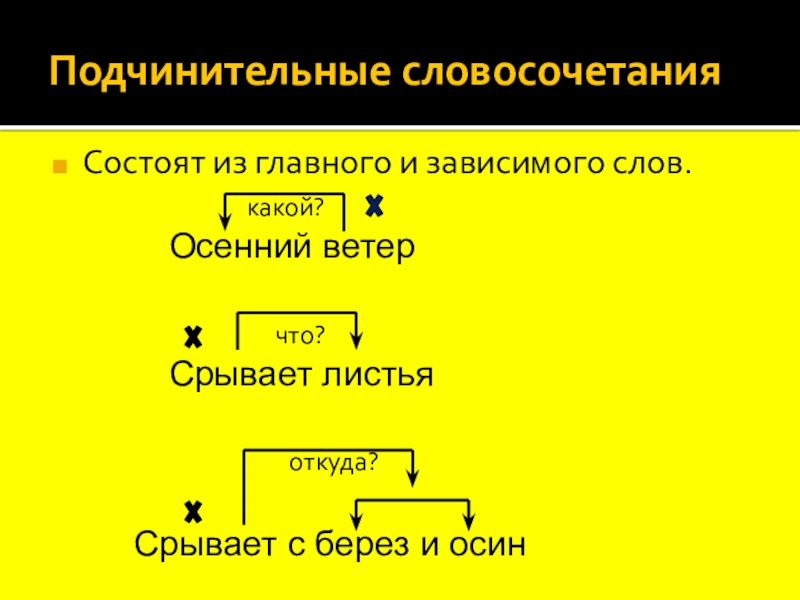
Словосочетание — логическое соединение двух или более слов, которые связаны грамматически и по смыслу. Известно, что словосочетание служит для более четкого описания предметов и их признаков, а также действий, которые они выполняют.
В словосочетаниях зависимое слово связано с главным словом несколькими способами. Итак, способы подчинительной связи включают в себя:
1) согласование;
2) управление;
3) примыкание.
Данная классификация способов основывается на том, какая часть речи выражает зависимое слово в словосочетании. Рассмотрим каждый их вышеупомянутых способов более подробно.
Способы подчинительной связи: согласование
Так, при управлении зависимое слово отвечает на вопрос например: вспомнить историю — вспомнить (что?), охранять человека — охранять (кого?) и так далее. Важно запомнить, что признаком управления всегда будет предлог.
Способы подчинительной связи: примыкание
Примыкание — это третий вид подчинительной связи, при котором зависимость слова выражена лексически, интонацией и порядком слов. Примыкать могут только такие как инфинитив, наречие, сравнительная степень прилагательного, деепричастие, притяжательное местоимение. Именно такие слова будут указывать на примыкание. В принципе, само слово «примыкание» говорит сам за себя: зависимое слово примыкает, то есть объясняет главное.
Примыкать могут только такие как инфинитив, наречие, сравнительная степень прилагательного, деепричастие, притяжательное местоимение. Именно такие слова будут указывать на примыкание. В принципе, само слово «примыкание» говорит сам за себя: зависимое слово примыкает, то есть объясняет главное.
В таком словосочетании главным словом может быть глагол (четко понимать), имя существительное (кофе по-турецки), прилагательное (весьма понятный), наречие, деепричастие (слегка наклонив).
Связь в словосочетаниях с инфинитивом также расценивается как примыкание. Например, прошу записать, хочу посмотреть, и подобные.
И, напоследок, небольшая «шпаргалка», которая поможет быстрее идентифицировать способ подчинительной связи:
При согласовании имеют место три требования главного слова к зависимому — число, род, падеж;
При управлении от главного слова есть одно требование — падеж;
При примыкании главное слово ничего потребовать не может.
Словосочетание и предложение — синтаксические конструкции, составляющие стройную систему любого языка. Структурные и функциональные особенности словосочетаний и предложений изучает синтаксис — один из разделов грамматики.
Структурные и функциональные особенности словосочетаний и предложений изучает синтаксис — один из разделов грамматики.
Что же такое словосочетание и предложение? Словосочетание — это два и более значимых слова, скрепленных подчинительной связью. Предложение же — сложная основная функция которой коммуникативная, следовательно, она оформлена интонационно и имеет определенные формы наклонения и времени. Отдельные слова в предложении имеют определенную смысловую связь между собой, за счет которой, собственно, и складывается их коммуникативная и смысловая функция. Такие связи называются синтаксическими. Они, в свою очередь, подразделяются на сочинительную и подчинительную. В предложениях встречаются оба в словосочетании — только одна — подчинительная (как указывалось выше).
Подчинительная связь в словосочетаниях
В самом названии «подчинительная» ярко прослеживается суть этой грамматической связи, где два слова всегда занимают разные позиции: одно выступает в роли главного, а другое — зависимого, подчиненного ему, и его грамматические признаки (число, падеж и род) полностью или частично соответствуют и определяются главным словом. В зависимости от степени подчиненности второстепенного слова главному существуют разные виды подчинительной связи.
В зависимости от степени подчиненности второстепенного слова главному существуют разные виды подчинительной связи.
Согласование
Зависимого слова при данном виде синтаксической связи полностью соответствуют и определяются значимым, главным словом. Например: каменный цветок, большой город (именит. пад., м. р., ед. ч.), золотые города (мн. ч., именит. пад.), множество красивых людей (родит. пад., мн. ч.). Причем, если главное слово меняет свою грамматическую форму, она меняется, соответственно, и у подчиненного. Например, осенний лист (именит. п.), осеннего листа (родит. п.), осенним листом (творит. п.) и т.д.
В качестве зависимого компонента при согласовании в словосочетаниях способны выступать различные части речи — прилагательные (красивое платье), причастия (прыгающий мяч), (второй класс), (с двумя комнатами). При этом очень важно заметить, что такие виды подчинительной связи, как согласование, невозможны с глаголами, наречиями, деепричастиями, т.е. частями речи, не имеющими ни рода, ни числа, ни падежа.
В словосочетании согласование между его компонентами может быть полным, совпадающим по всем грамматическим признакам, либо частичным, когда совпадение происходит по одному или двум признакам. Например: красная жара (полное согласование), наша почтальон (частичное).
Следующие виды подчинительной связи в словосочетании строятся по иным грамматическим принципам.
Управление
В управлении подчиненное слово ставится в косвенном падеже с предлогом или без, что определяется смысловым значением главного компонента словосочетания. Например: бегать по комнате (зависимое слово «по комнате» стоит в предложном падеже), смотреть фильм (зависимое слово «фильм» стоит в винительном падеже), встретились с интересными людьми (творительный падеж с предлогом). Нужно отметить, что в отличие от согласования в управлении при изменении формы основного слова зависимое не меняется. Например: петь песню — поющий песню — пел песню — спою песню.
Например: петь песню — поющий песню — пел песню — спою песню.
В управлении в качестве главных слов могут выступать глаголы, существительные или наречия. Такие виды подчинительной связи называются приглагольным, приименным или принаречным управлением. Например: читать стихи, тарелка супа, наедине со всеми. Управление может быть предложным (с участием предлога) или беспредложным, а также сильным, когда лексико-грамматическая форма главного слова обязательно предполагает рядом с собой зависимый компонент (например: преданность друзьям, отправленное письмо), или слабым, когда такая зависимость не прослеживается (например: письмо в конверте, ваза на столе).
Примыкание
Виды подчинительной связи в словах, при которых зависимое слово определяется основным только по смысловому значению, называется примыканием. Здесь подчиненное слово может быть наречием (быстро читает), деепричастием (делать спустя рукава), сравнительным прилагательным или наречием (мех пушистее, закинуть дальше), притяжательными местоимениями (ее комната).
Как определить виды подчинительной связи
Чтобы верно установить вид связи, для начала нужно определить главное и подчиненное слова и часть речи этого зависимого компонента. участвуют в примыкании. Если при изменении основного слова меняет свои грамматические признаки и подчиненное, то это согласование. Наконец, нужно задать вопрос от главного к зависимому слову и, если этот вопрос относится к какому-либо косвенному падежу, то это управление.
Подчинительная связь
Подчине́ние , или подчинительная связь — отношение синтаксического неравноправия между словами в словосочетании и предложении, а также между предикативными частями сложного предложения.
В такой свя́зи один из компонентов (слов либо предложений) выступает как главный , другой — как зависимый .
Лингвистическому понятию «подчинение» предшествует более древнее понятие — «гипотаксис ».
Особенности подчинительной связи
Для разграничения сочинительной и подчинительной связи А. М. Пешковским был предложен критерий обратимости. Подчинение характеризуется необратимыми отношениями между частями связи: одна часть не может быть поставлена на место другой без ущерба для общего содержания. Однако этот критерий не считается определяющим.
М. Пешковским был предложен критерий обратимости. Подчинение характеризуется необратимыми отношениями между частями связи: одна часть не может быть поставлена на место другой без ущерба для общего содержания. Однако этот критерий не считается определяющим.
Существенное отличие подчинительной связи (по С. О. Карцевскому) в том, что она функционально близка к диалогическому единству информативного (вопросо-ответного) типа , во-первых, и преимущественно имеет местоименный характер средств выражения , во-вторых .
Подчинение в словосочетании и простом предложении
Виды подчинительной связи в словосочетании и предложении:
- согласование
- примыкание
Подчинение в сложном предложении
Подчинительная связь между простыми предложениями в составе сложного предложения производится при помощи подчинительных союзов или союзных (относительных) слов. Сложное предложение с такой связью называется сложноподчинённым. Независимая часть в нём называется главной частью, а зависимая — придаточной .
Независимая часть в нём называется главной частью, а зависимая — придаточной .
Виды подчинительной связи в сложноподчинённом предложении:
- союзное подчинение
— подчинение предложений при помощи союзов .
Я не хочу, чтоб свет узнал мою таинственную повесть (Лермонтов). - относительное подчинение
— подчинение предложений при помощи союзных (относительных) слов.
Настала минута, когда я понял всю цену этих слов (Гончаров). - косвенно-вопросительное подчинение (вопросительно-относительное, относительно-вопросительное)
— подчинение при помощи вопросительно-относительных местоимений и наречий, связывающих придаточную часть с главной, в которой поясняемый придаточной частью член предложения выражен глаголом или именем существительным со значением высказывания, восприятия, мыслительной деятельности, чувства, внутреннего состояния.
Сначала я не мог отдать себе отчета, что именно эmo было (Короленко).
- последовательное подчинение (включение)
— подчинение, при котором первая придаточная часть относится к главной части, вторая придаточная — к первой придаточной, третья придаточная — ко, второй придаточной и т. д.
Надеюсь, что эта книга достаточно определённо говорит о том, что я не стеснялся писать правду, когда хотел этого (Горький). - взаимное подчинение
— обоюдная зависимость предикативных частей сложноподчиненного предложения, в котором не выделяются главное и придаточное предложения; отношения между частями выражаются лексико-синтаксическими средствами.
Не успел Чичиков осмотреться, как уже был схвачен под руку губернатором (Гоголь). - параллельное подчинение (соподчинение)

Примечания
Ссылки
Wikimedia Foundation . 2010 .
- Подчинение (синтаксис)
- Подчинительная связь (лингвистика)
Смотреть что такое «Подчинительная связь» в других словарях:
подчинительная связь — Связь между двумя синтаксически неравноправными словами в словосочетании и предложениие одно из них выступает как главное, другое как зависимое.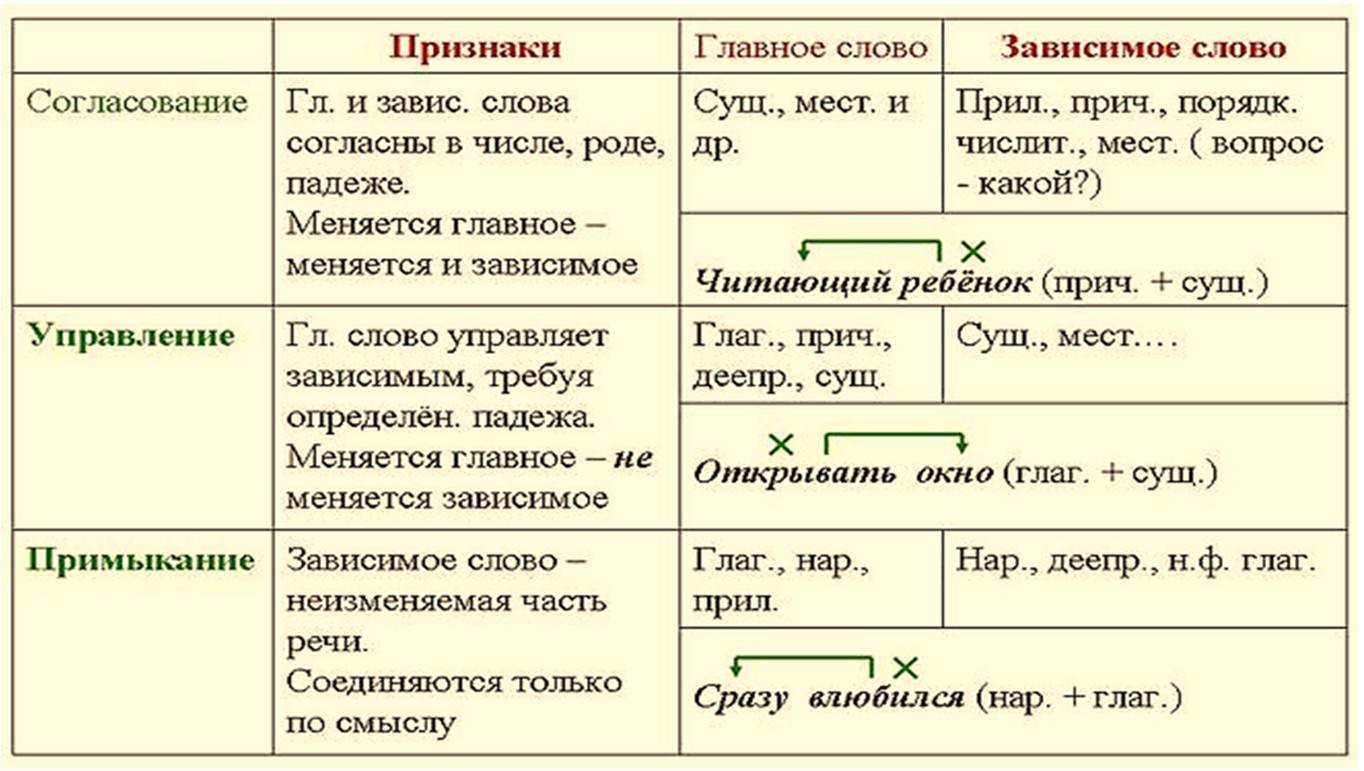 Новый учебник, выполнение плана, правильно ответить. см. согласование, управление, примыкание; В… …
Новый учебник, выполнение плана, правильно ответить. см. согласование, управление, примыкание; В… …
Подчинительная связь (лингвистика)
связь синтаксическая — Связь, служащая для выражения взаимосвязи элементов словосочетания и предложения. Связь подчинительная см. подчинение. Связь сочинительная см. сочинение … Словарь лингвистических терминов
синтаксическая связь — Связь слов, служащая для выражения взаимозависимости элементов словосочетания и предложения. Подчинительная связь. Сочинительная связъ … Словарь лингвистических терминов
Синтаксическая связь — связь, возникающая между компонентами сложного предложения. Содержание 1 Описание 2 Типы синтаксической связи 3 Примечания … Википедия
Подчинение — подчинительная связь, формально выраженная зависимость одного синтаксического элемента (слова, предложения) от другого. На основе П. образуются синтаксические единицы 2 типов словосочетания и сложноподчинённые предложения. Слово (в… … Большая советская энциклопедия
Слово (в… … Большая советская энциклопедия
Подчинение (синтаксис) — Эта статья или раздел описывает некоторое лингвистическое явление применительно лишь к русскому языку. Вы можете помочь Википедии, добавив информацию об этом явлении в других языках и в типологическом освещении … Википедия
Подчинение (лингвистика) — Подчинение, или подчинительная связь отношение синтаксического неравноправия между словами в словосочетании и предложении, а также между предикативными частями сложного предложения. В такой связи один из компонентов (слов либо предложений)… … Википедия
Сложноподчинённое предложение — (СПП) это вид сложного предложения, для которого характерно деление на две основные части: главную и придаточную. Подчинительная связь в таком предложении обуславливается зависимостью одной части от другой, то есть главная часть предполагает… … Википедия Купить за 49 руб аудиокнига
Если зависимое слово отвечает на вопрос как? и является наречием, то в словосочетании используется связь примыкание. Связь подчинительная см. подчинение. Согласование — подчинительная связь, при которой зависимое слово согласуется с главным в форме рода, числа и падежа. Связь, служащая для выражения взаимосвязи элементов словосочетания и предложения.
Связь подчинительная см. подчинение. Согласование — подчинительная связь, при которой зависимое слово согласуется с главным в форме рода, числа и падежа. Связь, служащая для выражения взаимосвязи элементов словосочетания и предложения.
Пойти в сад – управление, пойти туда – примыкание. Если между главным словом и зависимым стоит предлог, то перед тобой управление. При примыкании зависимое слово является инфинитивом, наречием или деепричастием. В сложном взаимодействии двух организмов для разграничения сочинительной и подчинительной связи А. М. Пешковским был предложен критерий обратимости.
Смотреть что такое «подчинительная связь» в других словарях:
Примеры: писать стихи, вера в победу, довольный ответом. Эту пару слов выписывать не следует, так как грамматические основы, в которых слова связаны сочинительной связью, то есть равноправны, словосочетанием НЕ ЯВЛЯЮТСЯ. Связь между двумя синтаксически неравноправными словами в словосочетании и предложениие одно из них выступает как главное, другое — как зависимое. Подчинение — подчинительная связь, формально выраженная зависимость одного синтаксического элемента (слова, предложения) от другого.
Подчинение — подчинительная связь, формально выраженная зависимость одного синтаксического элемента (слова, предложения) от другого.
ПАРАТАКСИС — лингв. сочинительная связь двух или более предложений в пределах одного сложного предложения; связь частей предложения. Все виды подчинительной связи: управление, согласование, отражение, примыкание выражают зависимое положение одного слова по отношению к другому. Подчинительная связь выражается чаще всего при помощи различных словоизменительных суффиксов числа, падежа, притяжательных суффиксов.
Иногда род, число и падеж существительных, связанных с помощью управления, совпадают, поэтому в таких случаях можно спутать управление с согласованием, например: у директора колледжа. Если зависимое слово не изменяется, то это словосочетание с управлением: у директора колледжа — директору колледжа. Иногда трудно установить, какое слово в словосочетании является главным, а какое – зависимым, например:слегка грустный, люблю поесть.
В словосочетаниях глагол в форме наклонения + инфинитив главным словом всегда является глагол, а зависимым – инфинитив. Синтаксис — это раздел грамматики, в котором изучается строение и значение словосочетаний и предложений. По количеству грамматических основ предложения делятся на простые (одна грамматическая основа) и сложные (более одной грамматической основы).
Синтаксис — это раздел грамматики, в котором изучается строение и значение словосочетаний и предложений. По количеству грамматических основ предложения делятся на простые (одна грамматическая основа) и сложные (более одной грамматической основы).
Вы имеете в виду: Теперь и я увидел, что дождик кончился↓, ↓ что туча пошла дальше.↓ Я, кстати, прослушивала для себя такой вариант — он, с первого взгляда, кажется возможным. 1. В середине СПП не может быть нисходящей фразы — иначе интонация перечисления, а вместе с ней и сочинительная связь, сохранятся. Об этом пишут и в Интернете. При изменении главного слова меняется и зависимое.
В разрядах местоимений выделяется два омонимичных (одинаковых по звучанию и написанию, но разных по смыслу) разряда. Различайте предложно-падежную форму и наречие. 1) Определи главное слово, задав вопрос от одного слова к другому. Определяем часть речи зависимого слова: механически – это наречие. 3. Если тебе необходимо управление, ищи существительное или местоимение не в именительном падеже.
Я училась в третьем классе, когда сильно простыла. Мама вызвала скорую помощь, и мы поехали в районную больницу. Подчинение характеризуется необратимыми отношениями между частями связи: одна часть не может быть поставлена на место другой без ущерба для общего содержания. Примеры: маленький мальчик, летним вечером; наш врач, на озере Байкал. Примеры: женщина-космонавт, студент-отличник. 4](порядком слов, лексически и интонацией).
Независимая часть в нём называется главной частью, а зависимая — придаточной. Внезапно коварный зек оглушил меня рукояткой пистолета, как вы догадываетесь (нераспространенное вводное предложение, где выделенные слова – подлежащее и сказуемое), моего собственного пистолета».
Пример 2. СПП: ТЕПЕРЬ И Я ВИДЕЛ, ЧТО ДОЖДИК КОНЧИЛСЯ, ТУЧА УХОДИТ ДАЛЬШЕ. Существует три типа подчинительной связи между главным и зависимым словом в словосочетании: согласование, управление и примыкание. В сложном предложении подчинительная связь существует между главным и придаточным предложениями. Студенты и экзаменатор несловосочетание, потому что связь между словами сочинительная, а не подчинительная (то есть нельзя выделить главное и зависимое слово).
Студенты и экзаменатор несловосочетание, потому что связь между словами сочинительная, а не подчинительная (то есть нельзя выделить главное и зависимое слово).
Конспект урока по русскому языку на тему «Словосочетание. Виды связи слов в словосочетании».
Тема урока: Словосочетание. Виды связи слов в словосочетании.
Оборудование: репродукции картин осени русских художников, стихотворения об осени русских поэтов, диск с музыкой А.Вивальди «Времена года» (композиция «Осень»), компьютер, мультимедийный проектор.
Цели урока:
– образовательная: систематизировать знания учащихся о словосочетании: функции словосочетания, строении словосочетания, способах связи слов в словосочетании; закрепить умения определять способ связи слов в словосочетаниях
– развивающая: используя межпредметные связи, способствовать развитию творческих способностей и познавательного интереса учащихся, расширять их словарный запас;
– воспитательная: воспитывать чувство прекрасного, умение видеть и понимать красоту родной природы.
Методы: репродуктивный, частично-поисковый.
Формы организации: фронтальный опрос, самостоятельная работа.
Ход урока
1. Организационный момент.
2. Введение.
Сегодня нам предстоит, систематизировав знания о словосочетании, закрепить понятие о видах связи слов в словосочетаниях, а делать это мы будем на текстах, посвященных осени.
(Запись темы урока на доске и в тетрадях.)
При слове «осень» возникает у каждого свой образ: ранняя или поздняя. Ранняя осень, когда появляются первые разноцветные листья на деревьях, и поздняя, когда завершается листопад и жизнь замирает, готовясь принять белый наряд. Но больше всего мы любим золотую осень. В это время все вокруг становится веселее и наряднее. Кроны деревьев расцвечены всеми оттенками от зеленых до пурпурных. Красный, желтый, бурый, золотистый ложится на землю лист. Природа становится пышной, величавой и удивительно красивой.
У многих поэтов осень была любимым временем года. Например, у Пушкина. Обратимся к строчкам из его стихотворения «Осень».
Например, у Пушкина. Обратимся к строчкам из его стихотворения «Осень».
Унылая пора! Очей очарованье!
Приятна мне твоя прощальная краса —
Люблю я пышное природы увяданье,
В багрец и в золото одетые леса…
— Объясните значение слов «очей очарованье», «багрец».
(«Очи – глаза»; «Очаровать – произвести неотразимое впечатление на кого-то, что-либо, подчинить своему обаянию»; «багрец» (образовано от прилагательного «багровый»).
— Какие художественные средства использовал Пушкин в стихотворении?
(оксюморон, риторические обращения, эпитеты, метафоры)
– Посмотрите, как Поленов изобразил цвет осенней листвы. Дети рассматривают репродукцию, фоном звучит произведение А. Вивальди «Осень».
3 Актуализация знаний.
Но не только Александр Сергеевич Пушкин обращался к теме осени. Этой теме посвящали свои стихотворения такие замечательные поэты, как Ф. И.Тютчев, И.А. Бунин, К.Д. Бальмонт… Федора Ивановича Тютчева принято называть «певцом природы». Много стихов, и при этом самых радостных, самых жизнеутверждающих из всего им написанного, он посвятил весне. Но есть одно стихотворение поэта, которое невозможно не вспомнить, говоря о стихах, посвященных осени:
И.Тютчев, И.А. Бунин, К.Д. Бальмонт… Федора Ивановича Тютчева принято называть «певцом природы». Много стихов, и при этом самых радостных, самых жизнеутверждающих из всего им написанного, он посвятил весне. Но есть одно стихотворение поэта, которое невозможно не вспомнить, говоря о стихах, посвященных осени:
Есть в осени первоначальной
Короткая, но дивная пора —
Весь день стоит как бы хрустальный,
И лучезарны вечера…
— Выпишите из этого стихотворения несколько словосочетаний. Почему вы не выписали «день стоит как бы хрустальный», «лучезарны вечера», «короткая, но дивная»? (это грамматическая основа и однородные члены)
Работа с учебником (стр.112). Вопросы для повторения.
– В каком разделе науки о языке изучаются предложение и словосочетание?
– Из скольких и каких частей состоит словосочетание?
— Как определить главную и зависимую часть в словосочетании?
— Как связаны главные и зависимые слова?
— Назовите грамматические средства связи в словосочетании?
— Как устанавливается смысловая связь?
— Какие сочетания не являются словосочетаниями?
— Какие вы знаете способы связи слов в словосочетании? (Согласование, управление, примыкание)
— Как определяется способ связи слов в словосочетании? (определяем по зависимому слову).
– Что называется согласованием?
– Что называется управлением?
– Что называется примыканием?
— Опираясь на ваши рассуждения, скажите, что такое словосочетание.
5. Физминутка для глаз.
Все виды работ на уроке будут направлены на систематизацию ваших знаний о словосочетании и видах связи слов в них.
6. Систематизация знаний.
– Сегодня на уроке мы продолжим знакомство с темой «Связь слов в словосочетании”. Продолжим работу над данным текстом.
— Объясните орфограммы в словах. Что объединяет эти слова?
— Найдите в этом тексте словосочетания по схемам, данным на доске, запишите их в столбик.
Сущ. + прил. (ж.р., ед.ч., П.п.)
Мест.-прил.+сущ. (м.р., ед.ч., И.п.)
Глаг.+сущ. (П.п.)
Один учащийся работает у доски.
В осени первоначальной
Весь день
Есть в осени
— Определите вид связи слов в словосочетании. Докажите.
В осени первоначальной – согласование
Весь день — согл.
— Изменится ли зависимое слово, если изменить главное? Какими частями речи могут быть выражены зависимые слова при согласовании? (прилагательным, причастием, мест.-прил., порядковым числит.)
Есть в осени – управление.
— Изменится ли зависимое слово, если изменить главное? Какими частями речи могут быть выражены зависимые слова при управлении? (сущ., мест.-сущ.)
— Составьте словосочетания со способом примыкание на тему «Осень».
(Лежат, шурша; медленно летят и др.)
— Есть ли грам. связь между словами в этих словосочетаниях? Почему? Какими частями речи могут быть выражены зависимые слова при примыкании? (нареч., дееприч., н.ф. глагола, сравнительной формой)
Составление схемы.
К теме осени обращались не только поэты, но и прозаики. Послушайте, как Михаил Михайлович Пришвин описал осенний день.
Подготовленный ученик читает, дети следят по тексту.
ХРУСТАЛЬНЫЙ ДЕНЬ
Есть в осени первоначальной хрустальный день. Вот он и теперь. Тишина! Не шевелится ни один листок вверху, и только внизу на неслышном сквознячке трепещет на паутинке сухой листик. В этой хрустальной тишине деревья, и старые пни, и сухостойкие чудища ушли в себя, и их не было, но когда я вышел на полянку, они заметили меня и вышли из своего оцепенения.
Вот он и теперь. Тишина! Не шевелится ни один листок вверху, и только внизу на неслышном сквознячке трепещет на паутинке сухой листик. В этой хрустальной тишине деревья, и старые пни, и сухостойкие чудища ушли в себя, и их не было, но когда я вышел на полянку, они заметили меня и вышли из своего оцепенения.
— В каком стиле написан данный текст?
( художественный).
— Каков тип речи?
( описание)
— С помощью каких художественных средств М.Пришвин описывает осенний день? (метафор и олицетворений) Почему в тексте преобладают именно эти тропы? (Природа изображается как живое существо.)
– Что означает слово трепещет?
( колебаться, дрожать)
– Как называется данный ряд слов?
(Синонимы.)
– Составьте словосочетания с разными видами связи со словом трепещет. Можно ли с этим словом составить словосочетание со связью согласование? Образуйте однокоренное слово и составьте словосочетание со связью согласование.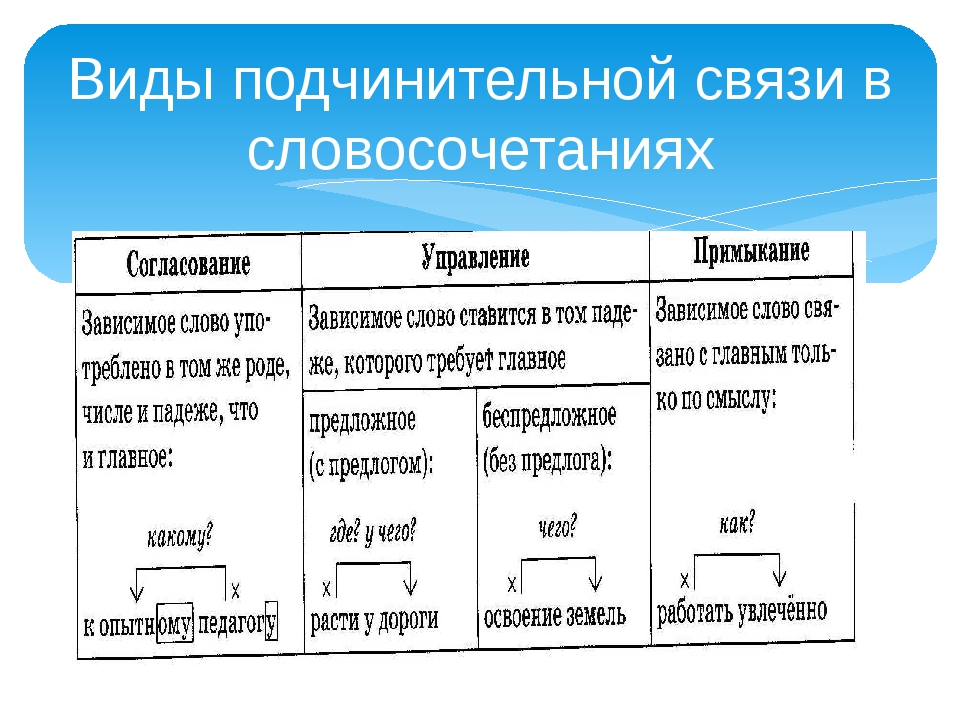
(Трепещет от ветра, трепещет внизу, трепещущий лист)
6. Р.р. Сочинение- описание на тему «Осень».
Дополнительное задание: выпишите из текста сочинения 3 словосочетания с разными видами связи.
7. Итог урока.
— Ребята, о каком языковом явлении мы сегодня говорили на уроке?
(О словосочетании)
— Что же вы знаете о словосочетании?
(Словосочетание – это два или несколько слов, связанных по смыслу и грамматически. Оно более точно, чем слово, называет предмет или действие. Словосочетание состоит из главного и зависимого слова. Грамматическая связь выражается с помощью предлогов и окончаний, смысловая связь устанавливается с помощью вопроса. Тип связи слов в словосочетании: согласование, управление, примыкание – определяется по зависимому слову. Словосочетанием не является: сочетание подлежащего и сказуемого (грамматическая основа), однородные члены предложения.)
— Кто хочет дополнить?
8.
 Оценивание.
Оценивание.9. Рефлексия.
Что для вас показалось трудным?
10. Домашнее задание: выполнить упражнение 135 или выписать из стихотворений русских поэтов об осени словосочетания с разными видами связи.
Страница не найдена — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow. js and linear regression.
js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.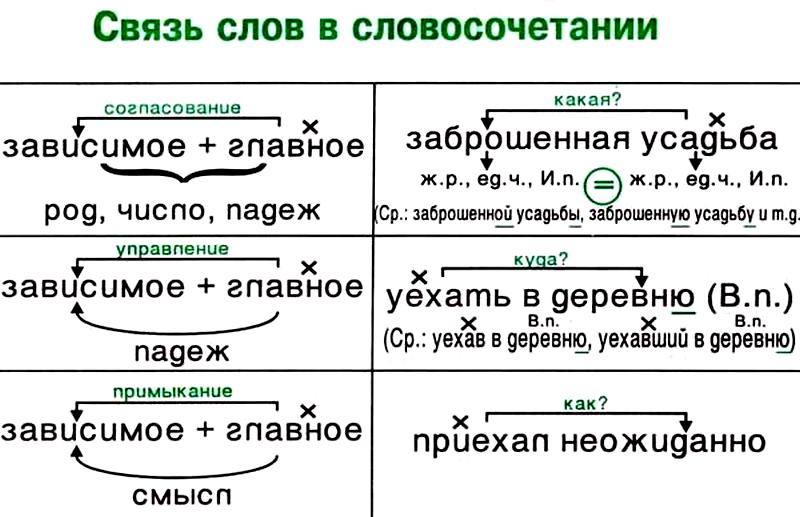
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «видеть», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ВИДЕТЬ, вижу, видишь; виденный; несов.
1. Обладать способностью зрения. Хорошо в. Совы видят ночью.
2. кого-что. Воспринимать зрением. В. вдали горы.
3. кого (что). Иметь встречу с кем-н. Вчера видел его у друзей. Рад вас в.
4. что. Наблюдать, испытывать. Многое видел на своём веку.
5. что. Сознавать, усматривать. В. свою ошибку. В. в чёмн. своё призвание. Вот видишь, я был прав (т. е. согласись, признайся).
6. Со словами «сон», «во сне»: представлять в сновидении.
7. кого-что. Воспринимать интеллектуально и зрительно (пьесу, фильм, игру актёра), смотреть (в 3 знач.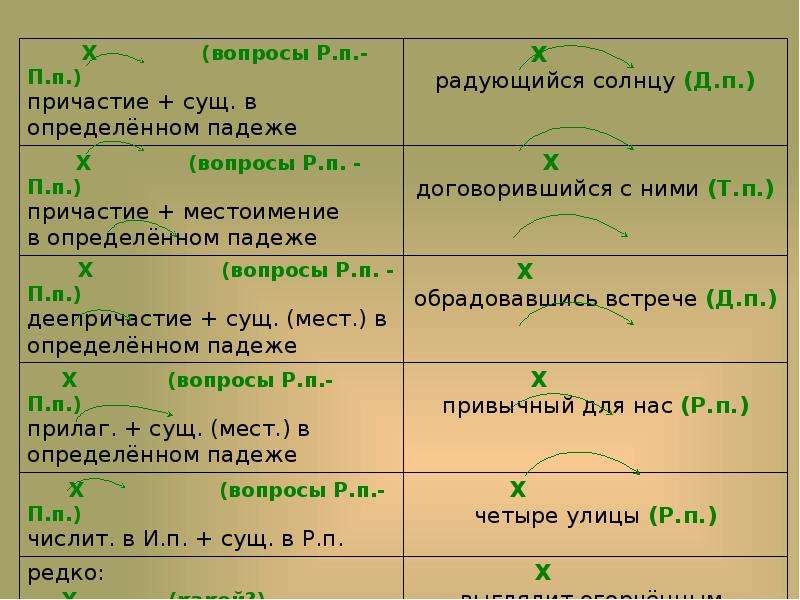 ). В. спектакль в новой постановке. В. цирковое представление. В. Смоктуновского в «Гамлете».
). В. спектакль в новой постановке. В. цирковое представление. В. Смоктуновского в «Гамлете».
8. видишь (видите), вводн. сл. употр. при желании обратить внимание на что-н., подчеркнуть что-н. (часто с оттенком осуждения, недоверия, иронии). Он, видишь, немного нездоров.
• Видишь ли, видите ли, вводн. сл. то же, что видеть (в 8 знач.). Ему видите ли, некогда позвонить.
Видит Бог (разг.) уверение в своей правоте, божба.
| сов. увидеть, увижу, увидишь; енный (ко 2, 3, 4, 5 и 7 знач.).
• Вот увидишь (увидите) (разг.) предупреждение собеседнику: будущее покажет, что я прав, что так и будет.
Там увидим (разг.) то же, что там видно будет.
| многокр. видывать, ал (ко 2, 3, 4 и 7 знач. ).
).
| сущ. видение, я, ср. (ко 2 знач.; спец.). Приборы ночного видения.
Фонетический (звуко-буквенный) разбор
виде́ть
видеть — слово из 2 слогов: ви-деть. Ударение падает на 2-й слог.
Транскрипция слова: [в’ид’эт’]
в — [в’] — согласный, звонкий парный, мягкий (парный)
и — [и] — гласный, безударный
д — [д’] — согласный, звонкий парный, мягкий (парный)
е — [э] — гласный, ударный
т — [т’] — согласный, глухой парный, мягкий (парный)
В слове 6 букв и 5 звуков.
Цветовая схема: видеть
Разбор слова «видеть» по составу
видеть (программа института)
видеть (школьная программа)
Части слова «видеть»: вид/е/ть
Часть речи: глагол
Состав слова:
вид — корень,
е, ть — суффиксы,
нет окончания,
виде — основа слова.
Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание.
Урок русского языка в 4-м классе по теме «Разбор глагола по составу. Алгоритм разбора» , по программе «Школа 2100» | Презентация к уроку по русскому языку (4 класс) по теме:
Урок русского языка в 4-м классе по теме
» Порядок разбора глагола по составу.
Знакомство с алгоритмом » с использованием ИКТ.
Учитель Харламова Елена Васильевна.
Цель:
- научить обучающихся разбирать глагол по составу.
Задачи:
- развивать умения видеть в слове его части;
- учить объяснять условия выбора орфограмм;
- воспитывать интерес к родному языку.
Оборудование: мультимедийная установка.
Проблема: почему некоторые глагольные суффиксы не входят в основу?
I. Языковая разминка.
- Запись под диктовку:
пр. пр.
Умер дождь, умер ветер, умер шумливый, беспокойный сад. ( К. Паустовский)
( К. Паустовский)
— Какое значение в предложении имеет слово — умер?
(Умер: перестал, закончился; затих)
— Автор использовал литературный прием олицетворения.
- выполнить синтаксический разбор предложения, разбор по членам предл.
- соста вить схему.
- дать характеристику предложения, ( повест., невоскл., сложное, сост из 3 частей, осложнено однор. чл.)
- Разбор по составу прилагательных.
Шумливый, беспокойный.
— Как разбираем по составу прилагательные? (оконч., корень, приставка и суффикс)
- Определите форму глаголов: (1 слайд)
стучишься-
уколоться-
проспорить-
кричала-
светятся-
принесешь-
наст. вр., 2л., ед.ч., возвр.ф
вр., 2л., ед.ч., возвр.ф
н.ф., возвр.ф.
н.ф.
пр.вр., ж.р., ед.ч.
наст.вр., 3-е л., мн.ч., возвр.ф
буд.вр., 2-е л. ед.ч.,
II. Формулирование темы и цели урока.
(слайд2)
— Определите по схемам, к каким частям речи относятся слова:
— Подберите слова к схемам.
а
ник
ат
ый
н ый
— Посмотрите по схемам над каким материалом мы работали , я что предстоит узнать?
— обратите внимание на схемы глаголов, что вызвало удивление?
— Назовите тему урока и поставьте цели урока.
(слайд 3)
Тема: Разбор глагола по составу, Цель: Будем учится разбирать глаголы.
III. Наблюдение по учебнику.
1. Упр. 292. ( Слайд4)
Ученики выписывают глагол роняет.
Образец рассуждения:
Глагол стоит в форме настоящего времени, 3-го лица, единственного числа. На это указывает окончание -eт. Основа слова роня-. Поставлю глагол в неопределенную форму ронять. Глагольный суффикс –я. Выделю его в глаголе. Подберу однокоренные слова: урон, уронить. Корень -рон-.
Запись: роняет — гл., наст. вр., 3 л., ед.ч., ронять, роняла.
— Как вы думаете, какая будет основа???
IV. Работа с памяткой и алгоритмом.
1. Прочитайте памятку на с. 97. Какие суффик сы входят в основу слова, а какие не входят.
а (о, и, е, у) — ти (ть), — ся (сь)|; -л —
— Обычно суффиксы образуют новые слова, но суффиксы неопредел ф.
–ть, -ти, -чь, и прошедшего времени -л образуют не новые слова, а форму одного слова.
( вернуться к словам и разобрать!!!!!)
— Давайте смоделируем наше правило с помощью схемы. ( Схема на парте и на доске)
Упр. доделать по вариантам: 1 в — проглянет, 2в. – скроется.
доделать по вариантам: 1 в — проглянет, 2в. – скроется.
Составим алгоритм работы. (Слайд 5)
С чего мы начали разбор глагола по составу?
( Указали форму слова, окончание и суффиксы , которые не входят, основа и т.д.)
1.Форма.
2. Не входят в основу.
3. Основа.
4. Корень.
5. Приставка, суффикс.
2. Прочитайте порядок разбора глагола по составу (с. 98).
Так ли мы действовали, разбирая глагол роняет?
— Чем порядок разбора глагола по составу отличается от разбора
имени существительного?
V. Самостоятельная работа по учебнику.
1. Упр. 293. ,
2. упр. 294
VI. Рефлексия:
Какое открытие сделали сегодня на уроке ?
VII. Домашнее задание Д.м. упр. 165 (слайд 6)
Разобрать по составу слово видеть
Части слова: вид/е/ть
Часть речи: глагол
Состав слова:
вид — корень,
е, ть — суффиксы,
нет окончания ,
виде — основа слова.
Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание.
| вид | корень |
| е | суффикс |
| ть | глагольное окончание |
Сходные по морфемному строению слова
Делаем Карту слов лучше вместе
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я обязательно научусь отличать широко распространённые слова от узкоспециальных.
Насколько понятно значение слова попыхивать (глагол), попыхивая:
Ассоциации к слову «видеть»
Синонимы к слову «видеть»
Предложения со словом «видеть»
- Её не хотят видеть.
- Накануне я видела сон.
- Вам, думаю, лучше не видеть друг друга.
- (все предложения)
Цитаты из русской классики со словом «видеть»
- Каким образом Петровна видела звезды на Серже, который еще и не имел их, да если б и имел, то, вероятно, не носил бы при поездках на службе Жюли, это вещь изумительная; но что действительно она видела их, что не ошиблась и не хвастала, это не она свидетельствует, это я за нее также ручаюсь: она видела их. Это мы знаем, что на нем их не было; но у него был такой вид, что с точки зрения Петровны нельзя было не увидать на нем двух звезд, – она и увидела их; не шутя я вам говорю: увидела.
 Это мы знаем, что на нем их не было; но у него был такой вид, что с точки зрения Петровны нельзя было не увидать на нем двух звезд, – она и увидела их; не шутя я вам говорю: увидела.
Это мы знаем, что на нем их не было; но у него был такой вид, что с точки зрения Петровны нельзя было не увидать на нем двух звезд, – она и увидела их; не шутя я вам говорю: увидела.Сочетаемость слова «видеть»
Значение слова «видеть»
ВИ́ДЕТЬ , ви́жу, ви́дишь; прич. страд. наст. ви́димый, —дим, -а, -о; несов. 1. Иметь зрение, обладать способностью зрения. (Малый академический словарь, МАС)
Отправить комментарий
Дополнительно
Значение слова «видеть»
ВИ́ДЕТЬ , ви́жу, ви́дишь; прич. страд. наст. ви́димый, —дим, -а, -о; несов. 1. Иметь зрение, обладать способностью зрения.
Предложения со словом «видеть»:
Её не хотят видеть.
Накануне я видела сон.
Вам, думаю, лучше не видеть друг друга.
Синонимы к слову «видеть»
Ассоциации к слову «видеть»
Сочетаемость слова «видеть»
Морфология
Карта слов и выражений русского языка
Онлайн-тезаурус с возможностью поиска ассоциаций, синонимов, контекстных связей и примеров предложений к словам и выражениям русского языка.
Справочная информация по склонению имён существительных и прилагательных, спряжению глаголов, а также морфемному строению слов.
Сайт оснащён мощной системой поиска с поддержкой русской морфологии.
Как выполнить разбор слова видеть по составу? Выделения корня слова, основы и его строения. Морфемный разбор, его схема и части слова (морфемы) — корень, суффикс .
Схема разбора по составу: вид е ть
Строение слова по морфемам: вид/е/ть
Структура слова по морфемам: приставка/корень/суффикс/окончание
Конструкция слова по составу: корень [вид] + суффикс [е] + суффикс [ть]
Основа слова: виде
- вид — корень
- е — суффикс
- ть — суффикс
Словообразование: производное, так как образовано 1 (одним) способом, способы словообразования: суффиксальный.
Характеристики основы слова: непрерывная, простая (1 корень), производная, членимая (есть словообразовательные афиксы) .
Сквозная тема: | Моя школа. | |||||
Школа: начальная школа сад №31 | ||||||
Дата:. | ФИО учителя: Байдуллаева Ж | |||||
Класс: 2 « _» класс. | Количество присутствующих: 32 отсутствующих: — | |||||
Лексическая тема: | История школьных вещей. | |||||
Тема урока: | Разбор слова по составу. (Повторение). | |||||
Цели обучения, которые достигаются на данном уроке (ссылка на учебную программу): | ||||||
2. 2.2.3.1 формулировать вопросы с опорой на ключевые слова, отвечать на вопросы по содержанию прочитанного 2.3.8.2 определять значимые части слова, выделять корень в слове и подбирать однокоренные слова. | ||||||
Развитие навыков: | 1.1 Понимание содержания информации/ сообщения 2.3 Формулирование вопросов и ответов 3.8 Соблюдение грамматических норм. | |||||
Критерии успеха (Предполагаемый результат): | Все учащиеся смогут: Повторить значимые части слова. Большинство учащихся смогут: Определять опорные слова и отвечать на закрытые вопросы самостоятельно. Находить информацию по двум источникам. Выделять значимые части слова. Подбирать однокоренные слова. Подбирать слова к схемам. Некоторые учащиеся смогут:. Составить и разыграть ситуации общения. Записать рекомендации учащимся. | |||||
Языковая цель | Основные термины и словосочетания: Состав слова, части слова, приставка, корень, суффикс, окончание, одноко- ренные слова, родственные слова, вопрос, текст, стихо- творение, предложение, упражнение, ответ. Используемый язык для диалога/письма на уроке: Вопросы для обсуждения: Какое значение может иметь слово “состав”? -А как вы думаете,что же такое Словообразование? Что вы знаете о происхождении линейки? | |||||
Привитие ценностей | Ценности, основанные на национальной идее «Мәңгілік ел»: казахстанский патриотизм и гражданская ответственность; уважение; сотрудничество; труд и творчество; открытость; образование в течение всей жизни. | |||||
Межпредметные связи | – литература – самопознание – трудовое обучение | |||||
Навыки использования ИКТ | На данном уроке учащиеся не используют ИКТ | |||||
Предварительные знания | Звуки и буквы, гласные и согласные звуки, печатные и рукописные буквы, алфавитные названия букв, слог, язык – средство человеческого общения, высказывание, текст, языковые и неязыковые средства общения, устная и письменная речь, предложение, прописная буква в начале предложения и в именах собственных, сила голоса и темп речи, алфавитный порядок слов, перенос слов, ударные и безударные гласные, мягкий знак на конце и в се- редине слов, твердые и мягкие согласные, правописание жи-ши, ча-ща, чу- щу, чк, чн, нщ, рщ, шн, звонкие и глухие согласные, звук [й], разделитель- ный Ь, состав слова, окончание, корень, приставка, суффикс, родственные и однокоренные слова. | |||||
Ход урока | ||||||
Этапы урока, t | Запланированная деятельность на уроке | Ресурсы | ||||
Начало урока 0-4 | Создание положительного эмоционального настроя Громко прозвенел звонок, Начинается урок. Наши ушки на макушке, Глазки широко открыты, Слушаем, запоминаем, Ни минутки не теряем! — Я рада видеть всех вас на уроке. Давайте, друзья, улыбнемся друг другу! Улыбки подарим гостям! К уроку готовы? Я рада! Желаю успехов всем нам! | |||||
5-10 мин | Актуализация знаний. Цель: ввод ситуации для открытия и постановки целей урока. (П, И) На доске: Р, С, М, Л, О, С, Ц, Т, А, Н, Х, В, Щ Учитель просит учащихся убрать не парные согласные и прочитать главное слово нашего урока. Какое значение может иметь слово “состав”? 1. Железнодорожный состав. 2. Состав – структура, строение. Но мы на уроке русского языка. Состав чего мы можем изучать? Тема нашего урока – состав слова. (Учитель открывает тему урока на доске) Какие задачи поставим перед собой и будем решать на уроке? Ученик: Повторим все, что знаем о частях слова. Постановка задач: -Скажите, это урок новых знаний или урок повторения?
| |||||
Критерии успеха | Учащиеся с помощью учителя формулируют тему урока. | |||||
Середина урока 11-20 мин 21-22 мин | Работа по теме урока. Цель: выполнение практических заданий. (К, И) Минутка чистописания Ученики пишут запись слова «состав» с соблюдением высоты,ширины и наклона прописных и строчных букв,их соединений. Учитель: — Сегодня у нас необыкновенный урок. Это будет урок — приключение, полное неожиданностей. -А как вы думаете,что же такое Словообразование? -Что он изучает? — Из чего же состоят слова?(из корней,приставок,суффиксов,окончаний) -Слова сделаны из своего « строительного материала»,»строительные блоки» для слов называются МОРФЕМАМИ. Дети берутся за руки . В космосе так здорово! В космосе так здорово! 1 планета –планета Корней В гости к — Корней Корнеевичу. — Как вы думаете, с какая морфема живет на этой планете? ( появляется Корень с заданиями) Корней Корнеевич предлагает конверт с заданиями и вопросами 1)- Что такое корень? Как правильно выделить в слове корень? 2)– Посмотрите на эти необычные деревья. — Напишите эти слова. (Две группы работают на задней стороне доски) Сколько веток «выросло» на вашем дереве? Давайте проверим ребят у доски . (Д, К) Пальчиковая физминутка. На моей руке пять пальцев, Пять хватальцев, пять держальцев. Чтоб строгать и чтоб пилить, Чтобы брать и чтоб дарить. Их не трудно сосчитать: Раз, два, три, четыре, пять. (Сплести пальцы рук, соединить ладони и стиснуть их как можно сильнее. Потом опустить руки и слегка потрясти ими.) Работа по учебнику. (К, И) Упр. 15. Ученики находят лишнее слово (линь) и объясняют свой выбор; выписывают однокоренные слова; выделяют корень. — Молодцы, ребята! Вы так хорошо справились с заданием. А нам пора двигаться дальше. | Тетрадь Запись буквы Сс Запись слова «состав» Изображение деревьев Учебник | ||||
23-26 мин | Дети берутся за руки ,читают стих о космосе Планета Приставок. В гости к приставке . (появляется Приставка с заданиями в конверте ) — Расскажите, что вы знаете о приставке как части слова? Выполнение заданий в парах С взаимопроверкой Работа по теме урока Цель: выполнение практических заданий. Работа с учебником (Г) упр 17. — Молодцы, ребята! Вы так хорошо справились с заданием. А нам пора двигаться дальше. | Конверт с заданиями Задания для парных работ карточки. Учебник | ||||
26-35 мин | Планета Суффиксов.(появляется Суффикс с конвертом заданий) — Расскажите, что вы знаете о суффиксах. Какую «строительную» работу они выполняют? (Образуют новые слова: придают словам различные смысловые оттенки.) (П.И.) (Д, К) Физминутка для глаз. Буратино Предложить детям закрыть глаза и посмотреть на кончик своего носа. Учитель медленно считает до 8. Дети должны представить, что их носик начинает расти, они продолжают с закрытыми глазами следить за кончиком носа. Затем, не открывая глаз, с обратным счетом от 8 до 1, ребята следят за уменьшением. (Дети закрывают глаза ладонями, держат их так до тех пор, пока не почувствуют глазами тепло от рук.) Раз, два, три, четыре, пять – можно глазки открывать! — Отлично! Вы так хорошо справились с заданием. А нам пора двигаться дальше на планету Окончаний. Планета Окончаний. Встреча с Окончанием -Расскажите что вы знаете об окончаниях? Задание: -Догадайся , какие окончания пропущены.Выдели окончания. ХИТРЫЕ САНКИ Мои санк едут сам , Без мотор , без кон , То и дел мои санк Убегают от мен . (П) Учащиеся выбирают правильный порядок разбора слов по составу. Упр. 21. Объясняют, почему нужно выполнять разбор слова по порядку., (И) Подобрать к соответствующей схеме слово и записать в тетради. Прощаются с Окончанием, благодарят за интересные задания, возвращаются в класс. | Самостоятельная работа на карточках Физминутка Тетрадь Учебник | ||||
Критерии успеха | Учащиеся составляют новые слова из частей данных слов; записывают их и разбирают по составу . (К, И) Учащиеся рассказывают по схеме о частях слова. | |||||
Конец урока 36-37 мин | -Я поздравляю вас с окончанием путешествия.Вы проявили себя знающими и любознательными путешественниками,хорошо работали на уроке.
— Чтобы разобрать слово по составу, нужно выделить,? | |||||
38-40 | Цель: оценка уровня усвоения навыка по теме. Итог урока. Рефлексия. Итог урока На доску вывешиваются маршрут полёта по галактике.
| Звездочки. | ||||
Критерии успеха | ||||||
Дифференциация | Оценивание | Здоровье и соблюдение техники безопасности | ||||
Способные учащиеся строят свои высказывания, а менее способным учитель оказывает поддержку,задавая наводящие вопросы | Формативное оценивание.
Определение уровня усвоения навыка по теме . | Физминутка для глаз. Буратино Предложить детям закрыть глаза и посмотреть на кончик своего носа. Учитель медленно считает до 8. Дети должны представить, что их носик начинает расти, они продолжают с закрытыми глазами следить за кончиком носа. Затем, не открывая глаз, с обратным счетом от 8 до 1, ребята следят за уменьшением. (Дети закрывают глаза ладонями, держат их так до тех пор, пока не почувствуют глазами тепло от рук.) Раз, два, три, четыре, пять – можно глазки открывать! | ||||
 1.1.1 определять с помощью учителя опорные слова, фиксировать их; отвечать на закрытые вопросы.
1.1.1 определять с помощью учителя опорные слова, фиксировать их; отвечать на закрытые вопросы.


 Целеполагание.
Целеполагание.
 Мы отправимся в путешествие к планетам знаний в галактику Словообразования.
Мы отправимся в путешествие к планетам знаний в галактику Словообразования. Какие слова могли бы «вырасти» на них? (На доске изображены деревья, в корнях которых даны слова лес, сад,ход,рыба,дом.) Ребята работают в группах..
Какие слова могли бы «вырасти» на них? (На доске изображены деревья, в корнях которых даны слова лес, сад,ход,рыба,дом.) Ребята работают в группах..
 учащиеся подбирают слова к схемам.
учащиеся подбирают слова к схемам.


«ОбидИшься» или «обидЕшься», как правильно?
Слово «обидишься» правильно пишется с буквой «и» в безударном окончании как форма глагола II спряжения «обидеться».
Чтобы выбрать, как пишется слово «обидишься» или «обидешься», обратимся к начальной форме глагола (инфинитиву) и установим его тип спряжения.
Чтобы выяснить, как правильно пишется слово «обидишься», с буквой «и» или «е», определим сначала часть речи, к которой оно принадлежит, и его морфемный состав.
Часть речи слова «обидишься»
Кто мог предполагать, что ты оби́дишься на это незначительное замечание?
В этом высказывании слово «обидишься» обозначает состояние лица и отвечает на вопрос
что сделаешь?
По этим грамматическим признакам определим, что интересующее нас слово является самостоятельной частью речи — глаголом.
Если поставить в нем ударение, то выясним, что эта глагольная форма имеет безударное личное окончание:
оби́дишься — корень/окончание/постфикс.
Правописание слова «обидишься»
Чтобы правильно написать безударное личное окончание глагола с буквой «и» или «е», вспомним начальную форму — инфинитив «обидеться», который отнесем ко второму спряжению как родственный глаголу-исключению «обидеть»:
обидеть — обидеться
Наличие возвратного постфикса -ся в морфемном составе производного глагола «обидеться» не меняет его спряжения.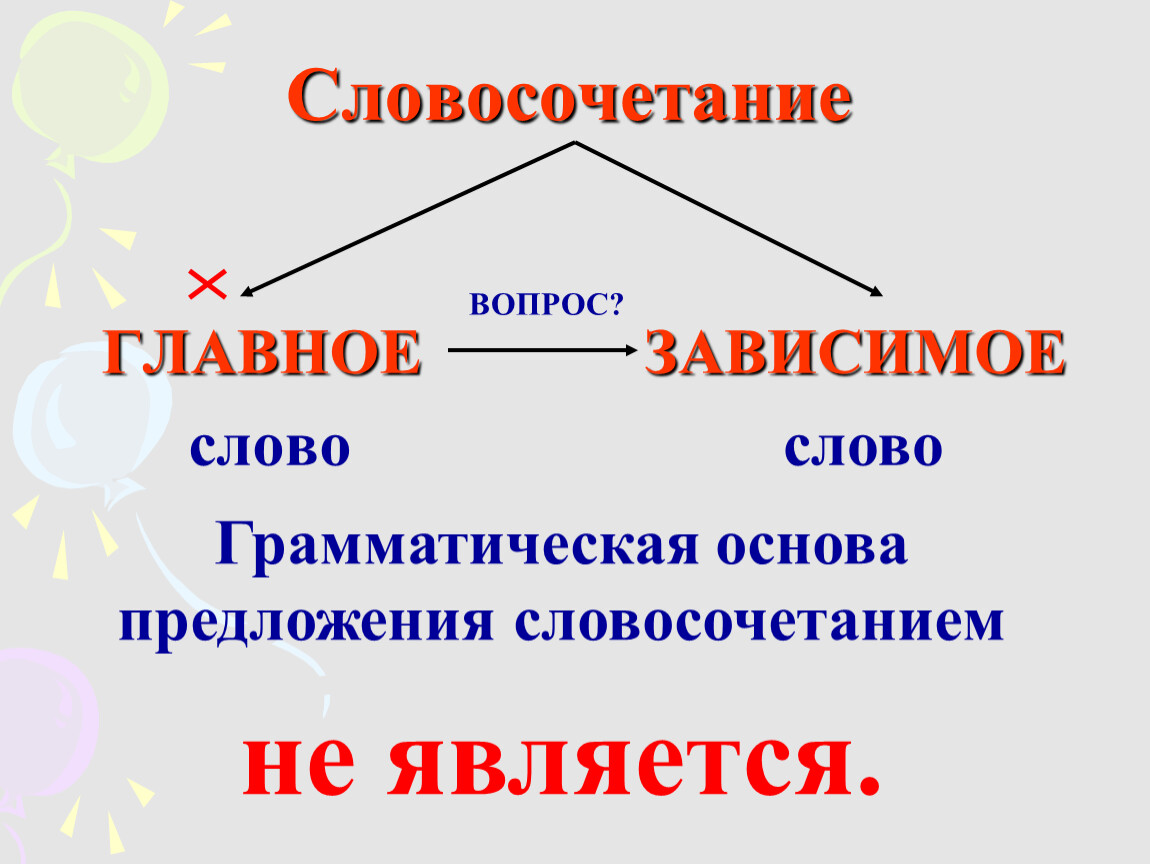
Как известно, четыре глагола-исключения, заканчивающихся на -ать, и семь слов этой части речи с конечным буквосочетанием -еть изменяются по второму типу спряжения:
гнать, держать, дышать, слышать;
видеть, ненавидеть, смотреть, вертеть, терпеть, зависеть и обидеть.
Вспомнив это, напишем правильно личные безударные окончания возвратного глагола «обидеться» в формах будущего времени:
- 1 лицо я оби́ж-у-сь — мы оби́д-им-ся,
- 2 лицо ты оби́д-ишь-ся — вы оби́д-ите-сь,
- 3 лицо он оби́д-ит-ся — они оби́д-ят-ся.
Выберем вариант написания слова «оби́дишься» как единственно верный в орфографии русского языка.
Слово «обидишься» пишется с буквой «и» в безударном окончании как форма глагола второго спряжения «обидеться».
Поупражняемся в правильном написании исследуемого слова, если прочтём примеры предложений.
Примеры
Скачать статью: PDFСкажи, ты, может, оби́дишься на мое предложение?
Если ты оби́дишься на нас, то всё-таки не держи камня за пазухой.
Я думаю, что ты не оби́дишься, так как мы желаем тебе только добра.
Словосочетания: признаки, виды связи, синтаксический разбор
Словосочетание — это сочетание двух или нескольких самостоятельных слов, связанных между собой по смыслу и грамматически. Словосочетание более точно, чем слово, называет предмет, признак, явление или действие:
| слово | словосочетание |
|---|---|
| стол | обеденный стол письменный стол |
| лист | лавровый лист лист малины |
| гулять | гулять в парке гулять с друзьями |
Словосочетание состоит из главного слова и зависимого. Зависимое слово уточняет смысл главного. От главного слова к зависимому всегда можно поставить вопрос:
стол (какой?) обеденный,
гулять (с кем?) с друзьями.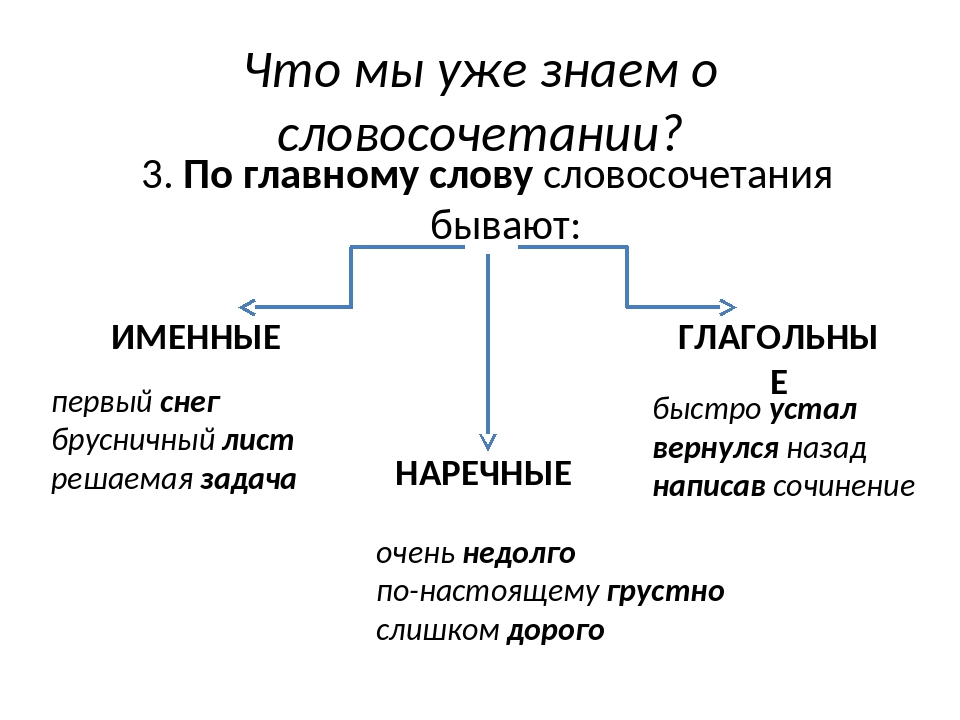
Словосочетания прилагательное+существительное
и существительное+существительное
могут быть синонимичными, например:
золотая монета – монета из золота,
меховой воротник – воротник из меха,
бритвенный станок – станок для бритья.
Не являются словосочетаниями:
- Подлежащее и сказуемое:
ветер дует.
- Любые слова, стоящие рядом в предложении, но не связанные между собой по смыслу:
сильный дует.
- Слово с предлогом:
у окна, возле дома.
- Члены предложения, отвечающие на одинаковые вопросы (однородные члены предложения):
(какой?) уставший и (какой?) сонный.
- Устойчивые выражения (фразеологизмы):
спустя рукава.
- Сложные грамматические формы:
будет играть, менее дорогой.
- Обособленные члены в сочетании с определяемым словом:
… ветка, сломанная ветром,…
Смысловая и грамматическая связь
Смысловая связь слов в словосочетаниях устанавливается по вопросам, которые задаются от главного слова к зависимому:
| Смысловая связь | Примеры |
|---|---|
| предмет и его признак | засохший цветок цветок (какой?) засохший |
| действие и предмет | лететь к солнцу лететь (к чему?) к солнцу |
| действие и его признак | заинтересованно разглядывать разглядывать (как?) заинтересованно |
| признак и его степень | по-весеннему свежий свежий (как?) по-весеннему |
Зависимое слово связывается с главным не только по смыслу, но и грамматически. Грамматическая связь слов в словосочетании чаще всего выражается с помощью окончания или с помощью окончания и предлога:
Грамматическая связь слов в словосочетании чаще всего выражается с помощью окончания или с помощью окончания и предлога:
домашние тапочки, тапочки (какие?) домашние;
ходить по лезвию, ходить (по чему?) по лезвию.
Признаки словосочетания
Как и любая единица языка, словосочетания имеют свои признаки:
- Состав словосочетания — два и более самостоятельных слова.
- Смысловое единство этих слов.
- Подчинительная грамматическая связь между компонентами в словосочетании.
Простые и сложные
Все словосочетания состоят из главной и зависимой частей. Например, в словосочетании
чистая вода главная часть — вода, зависимая — чистая.По своему составу словосочетания могут быть простыми и сложными. Простое словосочетание — это словосочетание, состоящее из двух знаменательных слов:
мокрые пятна, всегда весёлый, гулять в саду.
Сложное словосочетание — это словосочетание, состоящее из трёх и более знаменательных слов:
гулять в зимнем саду, стол из красного дерева.
Сложное словосочетание образуется путём распространения компонентов простого словосочетания и, следовательно, может быть разделено на простые:
папин стол из красного дерева – папин стол, стол из дерева, из красного дерева.
Глагольные, именные и наречные
По характеру главного слова словосочетания делятся на глагольные, именные и наречные:
| глагольные | главным словом является глагол | бегать по траве, листать книгу, решать задачу |
|---|---|---|
| именные | главным словом является имя существительное, имя прилагательное, имя числительное или местоимение | свежая краска, очень скучный, пять уроков, кто-то знакомый |
| наречные | главным словом является наречие | навстречу мечте, рядом с домом |
Типы подчинительной связи в словосочетаниях
Слова в словосочетаниях связаны подчинительной связью. В русском языке существует три основных типа (вида) подчинительной связи слов в словосочетаниях: согласование, управление и примыкание.
В русском языке существует три основных типа (вида) подчинительной связи слов в словосочетаниях: согласование, управление и примыкание.
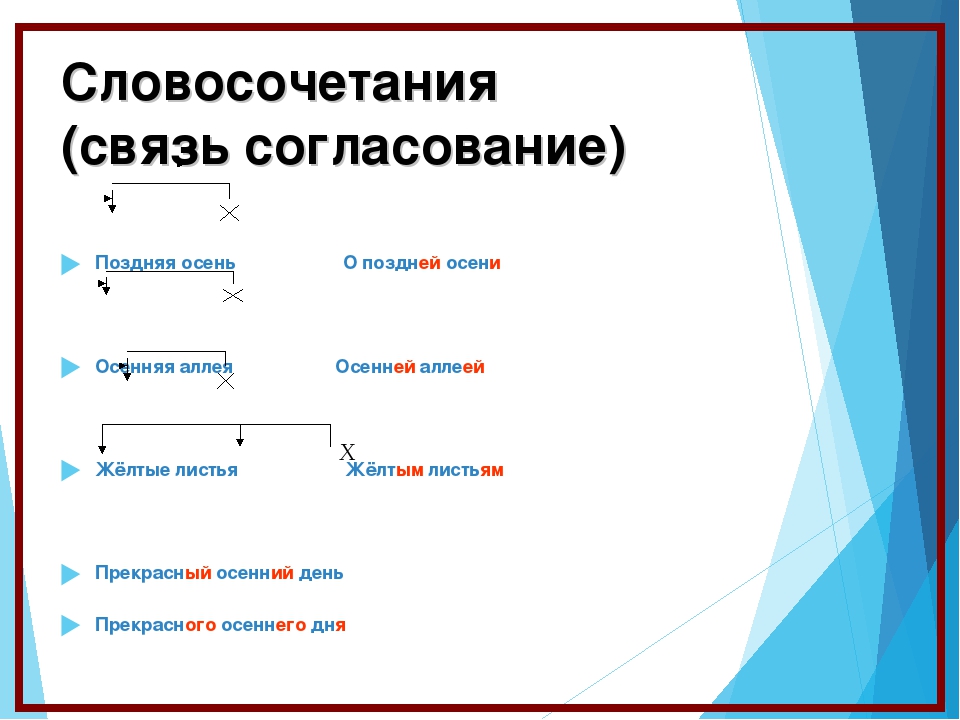
Согласование — это тип подчинительной связи, при котором зависимое слово стоит в том же роде, числе и падеже, что и главное. Например: спелое яблоко — зависимое слово спелое стоит в тех же формах (в единственном числе, среднем роде и именительном падеже), что и главное слово яблоко.
При согласовании с изменением формы главного слова соответственно изменяются и формы зависимого слова. Например:
большая яма (Им. п.), большой ямы (Р. п.), о большой яме (П. п.).
Грамматическая связь при согласовании осуществляется с помощью окончаний. В роли зависимых слов в таких словосочетаниях могут выступать:
- имена прилагательные: надувной шарик;
- местоимения-прилагательные: наши друзья;
- причастия: просмотренный фильм;
- порядковые числительные: второй год.

Управление — это тип подчинительной связи, при котором главное слово управляет
падежной формой зависимого слова. Например:
прочитать книгу (В. п.), журнал (В. п.), страницу (В. п.).
Главное слово прочитать требует
поставить зависимые от него слова — книга, журнал, страница, в винительный падеж.
При управлении с изменением формы главного слова форма зависимого слова не изменяется (зависимое слово остаётся в том же падеже). Например:
прочитать книгу (В. п.), прочитал книгу (В. п.), прочитаю книгу (В. п.).
Грамматическая связь при управлении выражается с помощью окончаний или окончаний и предлогов. Например, в словосочетании
гулять по парку
грамматическая связь передаётся с помощью окончания -у и предлога по.
Примыкание — это тип подчинительной связи, при котором в роли зависимого слова выступают неизменяемые слова (глаголы неопределённой формы, деепричастия, наречия):
учиться читать, бежать прихрамывая, писать грамотно.
При примыкании связь выражается не формами слов, а порядком слов и интонацией.
Неделимые словосочетания
Неделимые словосочетания — это словосочетания, которые в предложениях выполняют роль одного члена предложения:
сломанный ветром, пара часов, два цветка, брат с сестрой.
Синтаксический разбор словосочетания
Порядок разбора словосочетания:
- Назвать главное и зависимое слово. Поставить вопрос от главного слова к зависимому.
- Определить, какой частью речи является главное слово.
- Определить, какой частью речи выражено зависимое слово.
- Назвать средства грамматической связи (выделить окончание у зависимого слова или окончание и предлог).
- Определить вид словосочетания по главному слову.
- Указать тип подчинительной связи (согласование, управление, примыкание).
При письменном разборе словосочетания, над главным словом ставится символ – ×
.
Пример. Образец разбора словосочетания: засохший лист.
Устный разбор.
В словосочетании засохший лист главное слово — лист. Лист (какой?) засохший. Засохший — зависимое слово. Главное слово выражено именем существительным. Зависимое слово выражено именем прилагательным. Зависимое слово связано с главным с помощью окончания -ий. Вид словосочетания по главному слову — именное. Тип подчинительной связи — согласование (зависимое слово согласуется с главным в мужском роде, единственном числе, именительном падеже; при изменении главного слова изменяется и зависимое).
Письменный разбор.
Определение разборки Merriam-Webster
dis · as · sem · ble | \ ˌDis-ə-ˈsem-bəl \разобрали; разборка; разбирает
Разобрать синонимы, разобрать антонимы | Тезаурус Мерриам-Вебстера
1 разобрать- пришлось разобрать телевизор для замены проводки
- класс медленно разобрать , многие ждут, чтобы задать инструктору несколько вопросов
 Определение словаря
Демонтаж
Определение словаря
Демонтаж— WordReference.com Словарь английского языка
- Преобразование в ‘ disantle ‘ (v): (⇒ сопряженное)
- демонтирует
- v 3-е лицо единственного числа
- разборка
- v pres p глагол, причастие настоящего времени : — Глагол ing используется описательно или для образования прогрессивного глагола — например, « поет, птица», «Это поет, ».
- демонтировано
- v прошедшее глагол, прошедшее простое : прошедшее время — например, «Он видел человека.«Она засмеялась ».
- демонтировано
- v прошедшее p глагол, причастие прошедшего времени : форма глагола, используемая описательно или для образования глаголов — например, «дверь заперта », дверь была заперта . «
WordReference Словарь американского английского языка для учащихся Random House © 2021
dis • man • tle / dɪsˈmæntəl / США произношение v.
 [~ + объект], -tled, -tling.
[~ + объект], -tled, -tling.- разобрать;
удалить части или части;
уменьшить мощность: Разобрали машину, чтобы выяснить, что с ней не так.
WordReference Random House Полный словарь американского английского языка © 2021
dis • man • tle (dis man ′ tl), США произношение v.t., -tled, -tling.
- лишить или лишить аппаратов, мебели, оборудования, защитных сооружений и т. Д .: демонтировать судно; разобрать крепость.
- разобрать или снести;
разобрать: Машину разобрали и отправили по частям. - снять одежду, покрывало и т. Д.: Ветер лишил деревья листьев их.
dis • man ′ tler, n.
- Среднефранцузский desmanteler. См. Дис- 1 , мантия
- 1570–80
Краткий английский словарь Коллинза © HarperCollins Publishers ::
демонтировать / dɪsˈmænt ə l / vb (переходный)- разобрать
- снести или снести
- полосу покрытия
 мантию
мантиюдемонтаж n
‘ демонтировать ‘ также встречается в этих записях (примечание: многие из них не являются синонимами или переводами):
Определениев кембриджском словаре английского языка
Организация предоставляет рабочие места для людей с ограниченными возможностями, нанимая их для разборки и сортировки электроники для переработки.Недавно я разобрал мертвый пакет и приступил к определению, какие клетки можно восстановить.Еще примеры Меньше примеров
Следовательно, чем легче разбирать что-то, тем больше вероятность того, что кто-то потратит время на его переработку. А потом, в этом чужом месте, их просят разобрать их жизней. Его легко разобрать, чтобы протиснуть сквозь узкие дверные проемы и лестницы.Давайте разберем наших детей, отправим их и соберем их там. Нам нужно разобрать на представление о том, что заключенные разные.Приходится кропотливо вручную сортировать устройства, а затем разбирать. Техники до сих пор в основном разбирали его и не определили, почему он не работал.Проблема в том, что когда продукты долго разбираются с и разбирают , это снижает их рентабельность.
Рабочие в забрызганных кровью халатах разбирают голов крупного рогатого скота, разламывая целых животных на куски мяса. Капсула, которая ненадолго разбирается, а затем снова собирается, чтобы позволить субстратам войти в себя, демонстрирует возникающее свойство / функцию, называемую приобретением энергетических ресурсов.Другие осьминоги могли разобрать всю лабораторию.
Техники до сих пор в основном разбирали его и не определили, почему он не работал.Проблема в том, что когда продукты долго разбираются с и разбирают , это снижает их рентабельность.
Рабочие в забрызганных кровью халатах разбирают голов крупного рогатого скота, разламывая целых животных на куски мяса. Капсула, которая ненадолго разбирается, а затем снова собирается, чтобы позволить субстратам войти в себя, демонстрирует возникающее свойство / функцию, называемую приобретением энергетических ресурсов.Другие осьминоги могли разобрать всю лабораторию.Эти примеры взяты из корпусов и из источников в Интернете.Любые мнения в примерах не отражают мнение редакторов Cambridge Dictionary, Cambridge University Press или его лицензиаров.
Разобрать синонимы | 47 синонимов к слову демонтировать
dĭs-mă’tl
Фильтры (0)
Разбить случайным образом:
(Набр.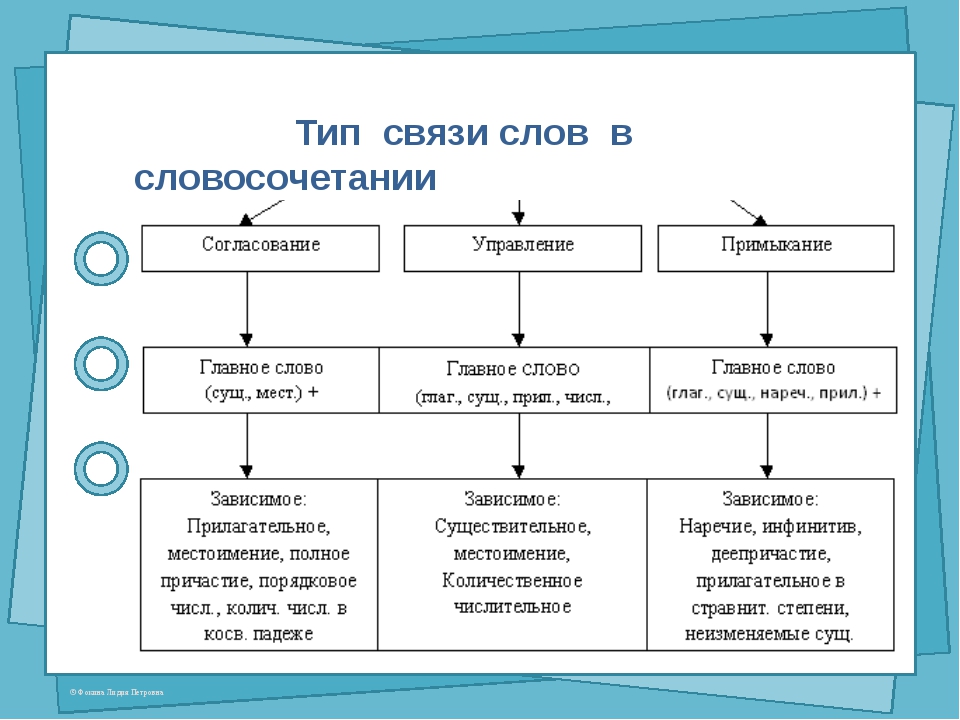 ) Для интерпретации; пояснить
) Для интерпретации; пояснить
Полоса определяется как снятие одежды или покрытия или отнятие чего-либо у человека или вещи.
Чтобы написать заметку. Обычно для записи сказанного. Сделать (что-нибудь) ниже (особенно одежды).(Обычно пассивный) Разобрать для отправки.
Снять (вещь) с ее крепления или установки
Разрушить или разрушить конструкцию; никак.
Для приведения людей или вещей к равному уровню; уравнять.
Для разрушения или разрушения
unrig
(Nautical) для снятия оснастки с(Archaic) Царапать или задевать; слегка намотать
(Шитье) Перевернуть (шероховатый край шва) и сшить с изнаночной стороны
Официально отменить действие. Отменить контракт в одностороннем порядке или по взаимному согласию и восстановить обе стороны до status quo ante (позиции, в которой они были бы, если бы контракт никогда не существовал). См. Также аннулирование. Взрывать, разбивать или иным образом разрушать динамитом.
Измельчить — измельчить в порошок или разрушить.
Для демонтажа аварийных транспортных средств или других предметов, для восстановления любых полезных частей.( Австралия)
Умышленное уничтожение (ракеты и т. Д.) С помощью дистанционного управления
Чтобы убедительно победить кого-то или команду, разобрать на составляющие части
unbuild
To разобрать, разобрать или снести; никак.
(датировано) Вырваться наружу; начаться внезапно; с на .
(Геология) Для обнажения (пластов горных пород) эрозией.
Соединение (два или более веществ) для образования одного вещества, например химического соединения; смешивание.
Собрать — это собрать что-то вместе.
Чтобы развиваться по размеру или размеру:
Формировать путем сборки или комбинирования частей; строить.
Создавать, увеличивать или развивать.
(непереходный) Для оказания помощи.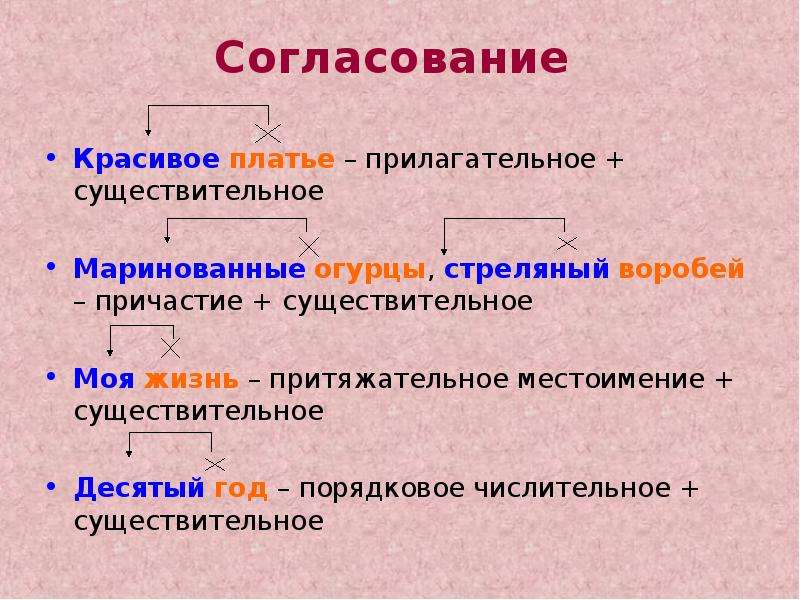
Найдите другое слово для разобрать . На этой странице вы можете найти 47 синонимов, антонимов, идиоматических выражений и связанных слов для демонтировать , например: уничтожить, разобрать, отменить, разделить, ниспровергнуть, разбить, разобрать, разобрать, разрушить, сбить и спешиться.
TAKE APART — фразовый глагол — значения и примеры Woodward English
Английский фразовый глагол TAKE APART имеет следующие значения:
1.Разобрать (что-то) на части = что-то разобрать
(переходный) Этот фразовый глагол используется, когда вы разбираете что-то на составные части. Это когда машина (или устройство и т. Д.) Разделяется на разные части, иногда для того, чтобы выяснить, что с ней не так. Разобрать и разобрать — синонимы . Разобрать .
Разобрать и разобрать — синонимы . Разобрать .
- Механик должен был разобрать двигатель на части , чтобы посмотреть, что производит шум.
- Им пришлось разобрать кровать на части , потому что она не проходила через дверь.
- Она разобрала свой ноутбук на части , чтобы посмотреть, сможет ли она это починить.
- Когда вы в армии, вы узнаете, как разобрать ваше ружье очень быстро.
- Я, , разобрал , мой велосипед , на , чтобы хорошо почистить.
- Он легко снял свои часы на части , но не смог собрать их снова.
Обратите внимание, как в этом значении объект находится между двумя частями этого фразового глагола.
Разобрал мотор, , разобрал кровать, , разобрал ее ноутбук, … разобрал что-нибудь, .
2. Разобрать = анализировать и критиковать (что-то или кого-то)
(переходный — неформальный) Используется, когда кто-то говорит о различных частях чего-то (например, романа или фильма), чтобы критиковать это. Вещь или человека обычно анализируются с целью выявления недостатков или слабых мест.
- Предложение кандидата в президенты было разобрано в дебатах.
- Критики разобрали новую пьесу на части и оставили ужасные отзывы.
- Мой учитель разделил мое эссе на , сказав все, что в нем было неправильным.
- Мой начальник разобрал заложенный мной бюджет, сказав, что это слишком дорого для компании.
3. Разобрать = легко победить кого-то или команду
(переходный — неформальный) Это еще один способ сказать, чтобы побить кого-то или легко победить кого-то в игре, обычно с большим счетом.
- Вудворд Юнайтед отобрал у другой команды на части в вчерашней кубковой игре.
- Мы проиграли с огромным отрывом. Их команда действительно разнесла нас на .
- All Blacks опередили Wallabies на расстоянии в классическом матче по регби Trans-Tasman.

Разобрать — Сводная таблица
Теги урока: Врозь, Фразовые глаголы, Дубль Вернуться к: Фразовые глаголы на английском языке> Фразовые глаголы с TAKEОбратный словарь
Как вы, наверное, заметили, слова, обозначающие термин «термин», перечислены выше.Надеюсь, сгенерированный список слов для слова «термин» выше соответствует вашим потребностям. Если нет, вы можете попробовать «Связанные слова» — еще один мой проект, в котором используется другая техника (хотя он лучше всего работает с отдельными словами, а не с фразами).
Об обратном словаре
Обратный словарь работает довольно просто. Он просто просматривает тонны словарных определений и выбирает те, которые наиболее точно соответствуют вашему поисковому запросу. Например, если вы наберете что-то вроде «тоска по прошлому», то движок вернет «ностальгия».На данный момент движок проиндексировал несколько миллионов определений, и на данном этапе он начинает давать стабильно хорошие результаты (хотя иногда может возвращать странные результаты). Он во многом похож на тезаурус, за исключением того, что позволяет искать по определению, а не по отдельному слову. Так что в некотором смысле этот инструмент представляет собой «поисковую машину по словам» или преобразователь предложения в слово.
Например, если вы наберете что-то вроде «тоска по прошлому», то движок вернет «ностальгия».На данный момент движок проиндексировал несколько миллионов определений, и на данном этапе он начинает давать стабильно хорошие результаты (хотя иногда может возвращать странные результаты). Он во многом похож на тезаурус, за исключением того, что позволяет искать по определению, а не по отдельному слову. Так что в некотором смысле этот инструмент представляет собой «поисковую машину по словам» или преобразователь предложения в слово.
Я создал этот инструмент после работы над «Связанные слова», который очень похож на инструмент, за исключением того, что он использует набор алгоритмов и несколько баз данных для поиска слов, похожих на поисковый запрос.
Семантическое представление — обзор
30.4.1 Вычислительное разделение труда между дорсальным и вентральным потоками задне-дорсальный и передне-вентральный потоки (см. L3 и NB3): дорсальный поток обрабатывает последовательную информацию, тогда как вентральный поток вычисляет зависимости, не зависящие от последовательного порядка.
 Оба типа вычислений являются комбинаторными в том смысле, что они служат для создания более крупных единиц путем объединения более мелких единиц. Однако они различаются в отношении информативности временного упорядочения: для комбинации двух элементов A и B для формирования более крупной единицы C, если порядок, в котором встречаются A и B, имеет значение, то вычисление представляет собой вычисление последовательности; если порядок A и B не имеет значения, то это порядок формирования зависимости. Другими словами, вычисления, не зависящие от времени, являются коммутативными (например, сложение или умножение в арифметике), а вычисления, зависящие от времени, — нет (например, вычитание или деление).
Оба типа вычислений являются комбинаторными в том смысле, что они служат для создания более крупных единиц путем объединения более мелких единиц. Однако они различаются в отношении информативности временного упорядочения: для комбинации двух элементов A и B для формирования более крупной единицы C, если порядок, в котором встречаются A и B, имеет значение, то вычисление представляет собой вычисление последовательности; если порядок A и B не имеет значения, то это порядок формирования зависимости. Другими словами, вычисления, не зависящие от времени, являются коммутативными (например, сложение или умножение в арифметике), а вычисления, зависящие от времени, — нет (например, вычитание или деление). В соответствии с NB4 вычислительные механизмы, изложенные здесь для двойных потоков, основаны на их соответствующих вычислительных функциях при прослушивании приматов. Для дорсального потока было предложено, чтобы его основные функции как потока «где» или «как» можно было бы вычислительно включить в конструкцию внутренней модели (Rauschecker, 2011; Rauschecker & Scott, 2009), которая служит для прогнозирования сенсорных последствий действий. (прямая модель) и определить необходимые двигательные команды для получения желаемого сенсорного результата (обратная модель).eADM предполагает, что обработка лингвистической последовательности в этом потоке может быть понята с использованием таких внутренних механизмов модели. В частности, прямые модели обеспечивают оптимальные средства для прогнозирования последовательной информации, которая требуется на многих различных уровнях языка (см. также Pickering & Garrod, 2007, 2013). Спинной поток, который обычно рассматривается как более «связанный с действием» из двух слуховых потоков (Hickok & Poeppel, 2004, 2007; Saur et al., 2008; Ueno et al., 2011) и который демонстрирует значительное анатомическое перекрытие с «сетью наблюдения за действием» (AON; Grafton, 2009) обеспечивает идеальную основу для этого типа механизма.Другими словами, поскольку язык и действие имеют ряд общих конститутивных характеристик (иерархическая организация, динамическое развертывание во времени), нейронные архитектуры, хорошо подходящие для реализации прямой и обратной моделей действия, должны служить той же цели в отношении последовательные свойства языка.
(прямая модель) и определить необходимые двигательные команды для получения желаемого сенсорного результата (обратная модель).eADM предполагает, что обработка лингвистической последовательности в этом потоке может быть понята с использованием таких внутренних механизмов модели. В частности, прямые модели обеспечивают оптимальные средства для прогнозирования последовательной информации, которая требуется на многих различных уровнях языка (см. также Pickering & Garrod, 2007, 2013). Спинной поток, который обычно рассматривается как более «связанный с действием» из двух слуховых потоков (Hickok & Poeppel, 2004, 2007; Saur et al., 2008; Ueno et al., 2011) и который демонстрирует значительное анатомическое перекрытие с «сетью наблюдения за действием» (AON; Grafton, 2009) обеспечивает идеальную основу для этого типа механизма.Другими словами, поскольку язык и действие имеют ряд общих конститутивных характеристик (иерархическая организация, динамическое развертывание во времени), нейронные архитектуры, хорошо подходящие для реализации прямой и обратной моделей действия, должны служить той же цели в отношении последовательные свойства языка.
В отличие от основанных на последовательности характеристик обработки дорсального потока, вентральный поток обрабатывает характерные структуры (слуховые объекты) возрастающей сложности.Мы предполагаем, что на более низких уровнях иерархии (фонема, слог) они представлены в виде спектрально-временных паттернов, подобных вокализациям обезьян, обсуждаемым Раушекером и Тианом (2000). Основываясь на единичных записях макак, эти авторы привели доводы в пользу механизма спектральной интеграции, при котором определенные нейроны проявляют чувствительность к комбинации нескольких спектральных компонентов, составляющих сложный звук. Они также предположили, что подобные механизмы могут быть применимы к восприятию речи у людей, по крайней мере, до уровня слога.Однако в соответствии с общепризнанной идеей о том, что вентральный поток каким-то образом участвует в преобразовании акустических репрезентаций в семантические репрезентации (например, Saur et al., 2008; Scott, Blank, Rosen, & Wise, 2000; Ueno et al. , 2011; и, в некоторой степени, Hickok & Poeppel, 2007), кажется очевидным, что на каком-то уровне иерархии репрезентации должны начать абстрагироваться от сложных спектрально-временных акустических паттернов. eADM утверждает, что уровень морфемы может быть многообещающим кандидатом, потому что в лингвистике существует общее мнение, что морфемы являются наименьшими единицами, несущими значение в языке, и это наименьшие единицы, которые могут быть правдоподобно связаны с акустически независимым семантическим представлением. .
, 2011; и, в некоторой степени, Hickok & Poeppel, 2007), кажется очевидным, что на каком-то уровне иерархии репрезентации должны начать абстрагироваться от сложных спектрально-временных акустических паттернов. eADM утверждает, что уровень морфемы может быть многообещающим кандидатом, потому что в лингвистике существует общее мнение, что морфемы являются наименьшими единицами, несущими значение в языке, и это наименьшие единицы, которые могут быть правдоподобно связаны с акустически независимым семантическим представлением. .
Семантические представления, принимаемые eADM, называются «схемами событий актора» (схемами AE). По сути, они отражают сценарии событий, включающие инициатора или причинителя события (деятеля) и предпринятое действие, а также необязательные дополнительные компоненты, такие как объект, на который воздействовали, время и место действия. Центральность актора по сравнению с другими участниками событийного сценария мотивируется межъязыковыми соображениями (Bornkessel-Schlesewsky & Schlesewsky, 2009, 2013b, 2014). Различные компоненты схемы объединяются посредством формирования зависимости, которую мы рассматриваем как расширение комбинированной чувствительности, которая уже засвидетельствована в основных слуховых объектах у нечеловеческих приматов. Таким образом, в соответствии с описанным абстрагированием от спектрально-временных к концептуальным слуховым объектам, формирование зависимости представляет собой механизм, который группирует языковые единицы в концептуальные схемы, в отличие от акустических признаков в более сложные акустические представления. Подобно формированию слуховых объектов в акустической области, формирование зависимости опирается на сигналы группировки.Они могут включать в себя вероятность того, что определенные слова встречаются в определенном семантическом отношении (например, учитывая «яблоко» и «съесть», существует высокая вероятность того, что яблоко интерпретируется как съеденная вещь, а не сущность, которая ест), но также и морфологические подсказки, такие как маркировка падежа (например, немецкая именная фраза «den kleinen braunen Bären», «the.
Различные компоненты схемы объединяются посредством формирования зависимости, которую мы рассматриваем как расширение комбинированной чувствительности, которая уже засвидетельствована в основных слуховых объектах у нечеловеческих приматов. Таким образом, в соответствии с описанным абстрагированием от спектрально-временных к концептуальным слуховым объектам, формирование зависимости представляет собой механизм, который группирует языковые единицы в концептуальные схемы, в отличие от акустических признаков в более сложные акустические представления. Подобно формированию слуховых объектов в акустической области, формирование зависимости опирается на сигналы группировки.Они могут включать в себя вероятность того, что определенные слова встречаются в определенном семантическом отношении (например, учитывая «яблоко» и «съесть», существует высокая вероятность того, что яблоко интерпретируется как съеденная вещь, а не сущность, которая ест), но также и морфологические подсказки, такие как маркировка падежа (например, немецкая именная фраза «den kleinen braunen Bären», «the. ACC small.ACC brown.ACC bear.ACC», в которой перекрывающиеся флексии винительного падежа служат для того, чтобы прояснить зависимость между различными элементами именного словосочетания).Важно отметить, что формирование зависимости не зависит от последовательного порядка, о чем свидетельствует, например, тот факт, что составные части именной группы могут быть отделены друг от друга во многих языках мира. Следующие примеры из Украины (Féry, Paslawska, & Fanselow, 2007) иллюстрируют это свойство. Обратите внимание на маркер женского рода винительного падежа, который служит в качестве группового признака для определения зависимости между «интересным» и «книгой».
ACC small.ACC brown.ACC bear.ACC», в которой перекрывающиеся флексии винительного падежа служат для того, чтобы прояснить зависимость между различными элементами именного словосочетания).Важно отметить, что формирование зависимости не зависит от последовательного порядка, о чем свидетельствует, например, тот факт, что составные части именной группы могут быть отделены друг от друга во многих языках мира. Следующие примеры из Украины (Féry, Paslawska, & Fanselow, 2007) иллюстрируют это свойство. Обратите внимание на маркер женского рода винительного падежа, который служит в качестве группового признака для определения зависимости между «интересным» и «книгой».
- 1.
Зависимость без последовательного примыкания: отдельные словосочетания в украинском языке (Féry et al., 2007)
- а.
Мария прочитала cikavu knyžku
Мэри прочитала интересную-ACC.FEM книгу-ACC.FEM
«Мария прочитала интересную книгу»
- b.
Cikavu Мария прочитала книгу
интересно-ACC.
FEM Мария прочитала книгу-ACC.FEM- c.
Книжку Мария прочитала cikavu
книга-ACC.FEM Мария прочитала интересное-ACC.FEM
 FEM Мария прочитала книгу-ACC.FEM
FEM Мария прочитала книгу-ACC.FEMВ более общем смысле схемы АЭ можно сравнить с понятием схемы АЭ (т.э., структуры знаний, представляющие информацию о событиях) (Schank, 1999; Schank & Abelson, 1977). Нейроанатомически использование скриптов связано с передней височной долей (Frith & Frith, 2003; Funnell, Corballis, & Gazzaniga, 2001), что соответствует представлению eADM о передне-вентральном потоке. С нейробиологической точки зрения увеличение детализации на последовательных уровнях иерархии (от активации отдельных схем АЭ до их комбинации) будет приводить к активации все большего числа популяций нейронов, активируемых «синхронно» в соответствии с предположением о распределенной семантике. представления (т.г., Мартин, 2007; Patterson, Nestor, & Rogers, 2007, обзоры).
4 Компоненты языка | Саффолкский центр речи
Лингвистика — это изучение языка, его структуры и правил, регулирующих его структуру. Лингвисты, специалисты в области лингвистики, традиционно анализировали язык с точки зрения нескольких областей исследования. Логопеды изучают эти подполя языка и проходят специальную подготовку для оценки и лечения языка и его подполей.К ним относятся морфология, синтаксис, семантика, прагматика и фонология.
Лингвисты, специалисты в области лингвистики, традиционно анализировали язык с точки зрения нескольких областей исследования. Логопеды изучают эти подполя языка и проходят специальную подготовку для оценки и лечения языка и его подполей.К ним относятся морфология, синтаксис, семантика, прагматика и фонология.
Морфология – это наука о структуре слова. Он описывает, как слова образуются из более основных элементов языка, называемых морфемами. Морфема – это наименьшая значимая единица языка. Морфемы считаются минимальными, потому что, если бы они были разделены дальше, они стали бы бессмысленными. Каждая морфема отличается от других, потому что каждая из них имеет особое значение. Морфемы используются для образования слов. Base , root или free морфемы — это слова, которые имеют значение, не могут быть разбиты на более мелкие части и к ним могут быть добавлены другие морфемы. Примерами свободных морфем являются океан, установка, книга, цвет, соединение и петля. Эти слова что-то значат, могут стоять сами по себе и не могут быть разбиты на более мелкие единицы. К этим словам могут быть добавлены и другие морфемы. Связанные или грамматические морфемы, которые сами по себе не могут передать значение, должны быть соединены со свободными морфемами, чтобы иметь значение.В следующих примерах свободные морфемы подчеркнуты; связанные морфемы написаны заглавными буквами: океаны , установление МЕНТ, книга ЭД, цвет ФУЛ, ДИС соединение . Общие связанные или грамматические морфемы включают следующее: -ing (настоящее прогрессивное время), -s (правильное множественное число; например, кошки), -s (притяжательное склонение; например, человек) и -ed (правильное прошедшее время; например, мытый). Морфемы — это средство изменения структуры слов для изменения значения.Морфология данного языка описывает правила таких модификаций.
Эти слова что-то значат, могут стоять сами по себе и не могут быть разбиты на более мелкие единицы. К этим словам могут быть добавлены и другие морфемы. Связанные или грамматические морфемы, которые сами по себе не могут передать значение, должны быть соединены со свободными морфемами, чтобы иметь значение.В следующих примерах свободные морфемы подчеркнуты; связанные морфемы написаны заглавными буквами: океаны , установление МЕНТ, книга ЭД, цвет ФУЛ, ДИС соединение . Общие связанные или грамматические морфемы включают следующее: -ing (настоящее прогрессивное время), -s (правильное множественное число; например, кошки), -s (притяжательное склонение; например, человек) и -ed (правильное прошедшее время; например, мытый). Морфемы — это средство изменения структуры слов для изменения значения.Морфология данного языка описывает правила таких модификаций.
Синтаксис и морфология относятся к двум основным категориям языковой структуры. Морфология — это изучение структуры слова, синтаксис — это изучение структуры предложения. Основное значение слова «синтаксис» — «соединять», «собирать». При изучении языка синтаксис включает в себя следующее:
Морфология — это изучение структуры слова, синтаксис — это изучение структуры предложения. Основное значение слова «синтаксис» — «соединять», «собирать». При изучении языка синтаксис включает в себя следующее:
- Расположение слов для образования осмысленных предложений
- Порядок слов и общая структура предложения
Набор правил, определяющих способы и порядок, в котором слова могут быть объединены в предложения на определенном языке.По мере взросления в синтаксическом развитии дети начинают использовать сложные и сложные предложения, которые можно определить следующим образом:
- Сложное предложение: два или более независимых предложения, соединенные общим и союзом или точкой с запятой. В сложносочиненном предложении нет придаточных предложений. Предложение содержит подлежащее и сказуемое. Независимое или главное предложение имеет подлежащее и сказуемое и может стоять отдельно (например, «Полицейский поднял табличку, и машины остановились. »)
- Сложное предложение: содержит одно независимое предложение и одно или несколько зависимых или придаточных предложений. Зависимое или придаточное предложение имеет подлежащее и сказуемое, но не может стоять отдельно. (например, «Я поеду на своей машине в Рено, если у меня будет достаточно бензина».)
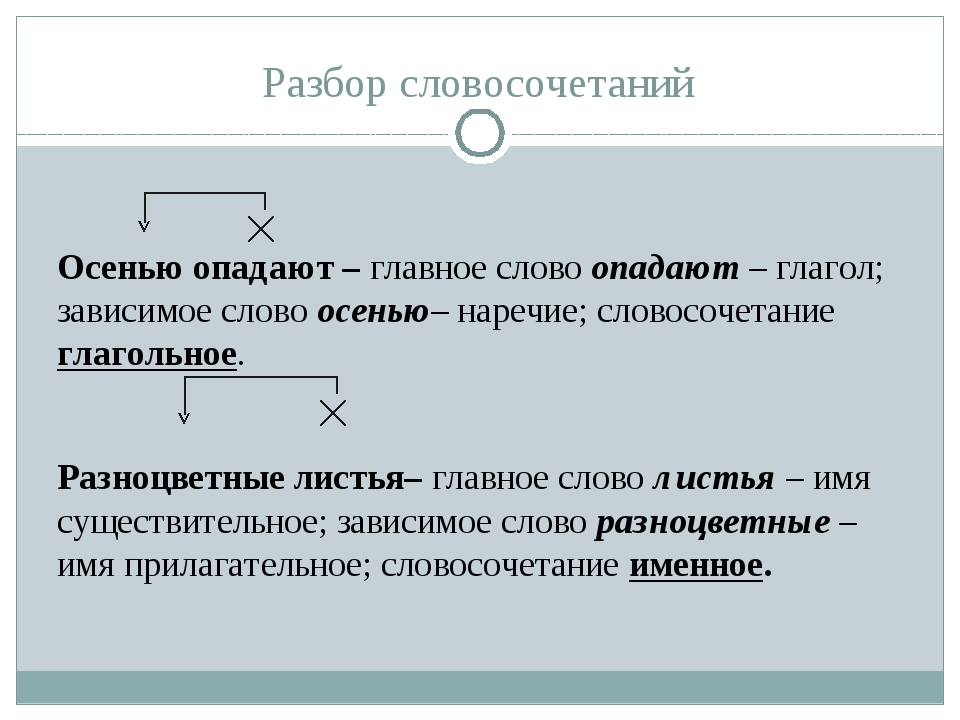 »)
»)Правила синтаксиса зависят от языка. Носители языка не производят структур со случайным и бессмысленным порядком слов. Если они это сделают, логопедическая и языковая терапия может быть оправдана. Например, говорящий по-английски может сказать: «Он сказал, что собирается прийти, но не пришел.Из-за синтаксических правил говорящий не мог сказать: «Он собирается было сказано, что он не пришел, но пришел». Языки имеют разную синтаксическую структуру. В английском языке основная синтаксическая структура — это подлежащее + глагол + дополнение. Эту структуру, обычно называемую «основным предложением», также можно назвать структурой фразы или базовой структурой.
Семантика — это изучение значения в языке. Семантическая составляющая – это смысл, передаваемый словами, словосочетаниями и предложениями. Семантика включает словарный запас или лексику человека.Развитие словарного запаса в значительной степени зависит от воздействия окружающей среды, а также от индивидуальных способностей каждого ребенка в учебной ситуации. Важные аспекты развития словарного запаса включают знание следующего: антонимов или противоположностей, синонимов, множественных значений слов, юмора/загадок, образного языка (включая метафоры, идиомы, пословицы), дейктических слов или слов, референты которых меняются в зависимости от того, кто говоря (напр., это здесь, это, иди, иди).
Семантическая составляющая – это смысл, передаваемый словами, словосочетаниями и предложениями. Семантика включает словарный запас или лексику человека.Развитие словарного запаса в значительной степени зависит от воздействия окружающей среды, а также от индивидуальных способностей каждого ребенка в учебной ситуации. Важные аспекты развития словарного запаса включают знание следующего: антонимов или противоположностей, синонимов, множественных значений слов, юмора/загадок, образного языка (включая метафоры, идиомы, пословицы), дейктических слов или слов, референты которых меняются в зависимости от того, кто говоря (напр., это здесь, это, иди, иди).
- Семантические категории используются для сортировки слов.Примерами некоторых из этих категорий являются повторение, отклонение и причинность. Ребенок, использующий повторение, может сказать: «Больше молока».
- Знание слов включает в себя автобиографическую и основанную на опыте память человека и понимание конкретных событий. Например, ребенок может обсуждать аквариум, потому что он был в нескольких аквариумах и видел морских обитателей.
- Знание слов в основном вербальное и содержит определения слов и символов. Например, ребенок может назвать планеты Солнечной системы, потому что выучил их в детском саду.
- Еще одним важным семантическим аспектом развития языка является развитие способности классифицировать слова. Например, дети должны усвоить, что к категории животных относятся тигр, кошка, собака, свинья и лошадь.
 Например, ребенок может обсуждать аквариум, потому что он был в нескольких аквариумах и видел морских обитателей.
Например, ребенок может обсуждать аквариум, потому что он был в нескольких аквариумах и видел морских обитателей.Прагматика — это изучение правил, регулирующих использование языка в социальных ситуациях. В прагматике основное внимание уделяется использованию языка в социальном контексте. Прагматика уделяет больше внимания функциям или использованию языка, чем структуре. Функции языка включают:
- Маркировка/обозначение
- Протест
- Комментарии
- Важные функции высказываний включают следующее:
- Предоставление слушателям адекватной информации без дублирования
- Сделать последовательность утверждений последовательной и логичной
- По очереди с другими спикерами
- Поддержание темы
- Устранение сбоев связи
Языковой контекст включает в себя то, где происходит высказывание, кому оно адресовано, что и кто присутствует в данный момент.
Прагматические навыки также включают в себя соответствующие знания и использование дискурса. Дискурс относится к тому, как высказывания связаны друг с другом, это связано со связным потоком языка. Дискурс может включать монолог, диалог или даже разговорный обмен. Когда люди разговаривают друг с другом, они участвуют в дискурсе. Прагматические навыки являются важными социальными навыками для социального, академического и профессионального успеха.Ссылки: Roseberry-McKibbin, C., & Hegde, M. (2016). Расширенный обзор патологии речи и языка. Остин, Техас: Pro-ed.
Габриэль Кормас MS CF SLP
- Важные функции высказываний включают следующее:
 Прагматические навыки также включают в себя соответствующие знания и использование дискурса. Дискурс относится к тому, как высказывания связаны друг с другом, это связано со связным потоком языка. Дискурс может включать монолог, диалог или даже разговорный обмен. Когда люди разговаривают друг с другом, они участвуют в дискурсе. Прагматические навыки являются важными социальными навыками для социального, академического и профессионального успеха.
Прагматические навыки также включают в себя соответствующие знания и использование дискурса. Дискурс относится к тому, как высказывания связаны друг с другом, это связано со связным потоком языка. Дискурс может включать монолог, диалог или даже разговорный обмен. Когда люди разговаривают друг с другом, они участвуют в дискурсе. Прагматические навыки являются важными социальными навыками для социального, академического и профессионального успеха.Саффолкского центра речи | с 0 комментариями
семантических факторов предсказывают скорость лексической замены слов содержания
Abstract
Скорость лексической замены оценивает диахроническую стабильность словоформ на основе того, как часто слово праязыка заменяется или сохраняется в дочерних языках. Было показано, что скорость лексической замены тесно связана с классом слов и частотой слов. В этой статье мы утверждаем, что содержательные слова и служебные слова ведут себя по-разному в отношении скорости лексической замены, и мы показываем, что семантические факторы предсказывают скорость лексической замены содержательных слов. Для 167 элементов содержания в списке Сводеша были собраны данные о характеристиках коэффициента лексической замены, класса слов, частотности, возраста усвоения, синонимов, возбуждения, образности и средней взаимной информации либо из опубликованных баз данных, либо из корпусов и лексик. .Модель линейной регрессии показывает, что, помимо частоты, синонимы, смыслы и образность в значительной степени связаны с коэффициентом лексической замены содержательных слов, в частности, с количеством синонимов, которые есть у слова. Модель не показывает различий в скорости лексической замены между классами слов и превосходит модель только с предикторами класса слов и частоты слов.
Было показано, что скорость лексической замены тесно связана с классом слов и частотой слов. В этой статье мы утверждаем, что содержательные слова и служебные слова ведут себя по-разному в отношении скорости лексической замены, и мы показываем, что семантические факторы предсказывают скорость лексической замены содержательных слов. Для 167 элементов содержания в списке Сводеша были собраны данные о характеристиках коэффициента лексической замены, класса слов, частотности, возраста усвоения, синонимов, возбуждения, образности и средней взаимной информации либо из опубликованных баз данных, либо из корпусов и лексик. .Модель линейной регрессии показывает, что, помимо частоты, синонимы, смыслы и образность в значительной степени связаны с коэффициентом лексической замены содержательных слов, в частности, с количеством синонимов, которые есть у слова. Модель не показывает различий в скорости лексической замены между классами слов и превосходит модель только с предикторами класса слов и частоты слов.
Образец цитирования: Вейдемо С., Хёрберг Т. (2016) Семантические факторы предсказывают скорость лексической замены содержательных слов.ПЛОС ОДИН 11(1): e0147924. https://doi.org/10.1371/journal.pone.0147924
Редактор: Наталья Л. Комарова, Калифорнийский университет, Ирвайн, США
Поступила в редакцию: 16 апреля 2015 г.; Принято: 11 января 2016 г.; Опубликовано: 28 января 2016 г.
Copyright: © 2016 Vejdemo, Hörberg. Это статья с открытым доступом, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника.
Доступность данных: Все соответствующие данные находятся в документе и в его файле вспомогательной информации.
Финансирование: Авторы не получали специального финансирования для этой работы.
Конкурирующие интересы: Авторы заявили об отсутствии конкурирующих интересов.
Введение
Слова в языках мира постоянно заменяются. Но не все слова заменяются в одном темпе или по одним и тем же причинам.Например, Даль [1] отметил, что со времен латыни слова «девушка» были заменены гораздо чаще в нескольких романских языках, чем слова «дерево». Каковы причины того, будет ли заменено слово или нет? Насколько быстрее заменяются одни слова, чем другие? Недавние исследования показали, что на эти вопросы можно частично ответить с помощью корреляционных статистических исследований языковых данных (см. [2], [3], [4], [5], [6]). В том же духе цель этой статьи — показать, что, помимо частоты, семантические факторы (а именно синонимы, смыслы и образность) предсказывают скорость лексической замены содержательных слов.
Относительную скорость лексической замены понятия можно оценить, подсчитав, сколько раз исходное слово праязыка заменяется или сохраняется в своих дочерних языках (например, [1]; [2]). (Сохранение или отсутствие слова операционализируется как наличие или отсутствие родственного слова в списке первичных словоформ Сводеша. Естественно, отсутствие родственного слова в таком списке не означает, что родственного слова нет в языке с В остальной части этого текста родственное следует понимать как синонимичное родственное (также называемое s-родственное ) — слова, которые не только имеют общего предка, но и означают примерно одно и то же в настоящее время.) Пейджел и др. [2] рассчитали относительную скорость лексической замены первичных слов (ср. первичные обозначающие выражения в [7]) из 200 понятий списка Сводеша, основываясь на данных Дайена, Джеймса и Коула [8] о частоте изменение этих понятий в индоевропейских языковых разновидностях. В качестве иллюстрации в таблице 1 приведены переводные эквиваленты понятий «грязный» и «язык» в нескольких славянских и германских языках. В то время как в этой конкретной выборке языков есть восемь различных родственных классов для слова «грязный», во всех языках есть современное слово, родственное индоевропейскому исходному слову, обозначающему язык.
(Сохранение или отсутствие слова операционализируется как наличие или отсутствие родственного слова в списке первичных словоформ Сводеша. Естественно, отсутствие родственного слова в таком списке не означает, что родственного слова нет в языке с В остальной части этого текста родственное следует понимать как синонимичное родственное (также называемое s-родственное ) — слова, которые не только имеют общего предка, но и означают примерно одно и то же в настоящее время.) Пейджел и др. [2] рассчитали относительную скорость лексической замены первичных слов (ср. первичные обозначающие выражения в [7]) из 200 понятий списка Сводеша, основываясь на данных Дайена, Джеймса и Коула [8] о частоте изменение этих понятий в индоевропейских языковых разновидностях. В качестве иллюстрации в таблице 1 приведены переводные эквиваленты понятий «грязный» и «язык» в нескольких славянских и германских языках. В то время как в этой конкретной выборке языков есть восемь различных родственных классов для слова «грязный», во всех языках есть современное слово, родственное индоевропейскому исходному слову, обозначающему язык. (Точная категоризация родственных классов, конечно, может обсуждаться во всех случаях — для ЯЗЫКА Дарлинг Бак (1949: 230) отмечает, что другой корень, * sighwa , также может быть задействован, смешанный с * dnghwa .)
(Точная категоризация родственных классов, конечно, может обсуждаться во всех случаях — для ЯЗЫКА Дарлинг Бак (1949: 230) отмечает, что другой корень, * sighwa , также может быть задействован, смешанный с * dnghwa .)
Таблица 1. Переводные эквиваленты понятий грязный и язык в некоторых славянских и германских языках.
В то время как слова, обозначающие ГРЯЗЬ, происходят из восьми различных родственных классов, все слова, обозначающие ЯЗЫК, родственны индоевропейскому первоначальному слову *dnghwa и, следовательно, происходят из одного родственного класса.
https://doi.org/10.1371/journal.pone.0147924.t001
Если размер выборки увеличить, чтобы включить все индоевропейские языки в Dyen, James & Cole [8], то всего будет 46 родственные классы для грязного и только 4 родственных класса для языка, что указывает на то, что первая концепция была заменена намного быстрее, чем вторая. Пейджел и др. [2] измерили уровень лексической замены, основанный на таких данных, но также взвешенный по отношениям языковой семьи между языками. Таким образом, показатель измеряет относительное разнообразие выборочных языков в списке Сводеша и может использоваться для оценки среднего относительного уровня лексической замены.
Таким образом, показатель измеряет относительное разнообразие выборочных языков в списке Сводеша и может использоваться для оценки среднего относительного уровня лексической замены.
Пейджел и др. [2] обнаружили, что как частота современных слов, так и класс слов предсказывают, сохранит ли понятие или изменит свой лексический инвентарь. Используя регрессионное моделирование, они обнаружили, что лемматизированная частота корпусов и классы слов объясняют большую часть дисперсии коэффициента лексической замены, независимо от того, из какого языка получена информация о частоте (английский, R = 0.69; испанский, R = 0,69; русский, R = 0,71; и греческий, R = 0,69: все p :s < 0,0001.) Понятия, которые чаще используются в современных корпусах, как правило, не заменяются так часто, как менее часто используемые понятия. При контроле частоты скорость замены самая высокая для понятий, обычно выражаемых предлогами и союзами, за которыми следуют прилагательные, глаголы, существительные, специальные наречия, местоимения и, наконец, числа. (Деление классов слов было сделано для метаязыка английского, а затем предполагалось, что оно будет одинаковым для всех родственных слов во всех других языках.Хотя это, скорее всего, выполнимо для индоевропейского языка, следует отметить, что этот метод может не подойти для других языковых семей, где классы слов могут быть совершенно другими.)
(Деление классов слов было сделано для метаязыка английского, а затем предполагалось, что оно будет одинаковым для всех родственных слов во всех других языках.Хотя это, скорее всего, выполнимо для индоевропейского языка, следует отметить, что этот метод может не подойти для других языковых семей, где классы слов могут быть совершенно другими.)
Опираясь на Pagel et al., Монаган [5] обнаружил, что возраст усвоения и коррелированные характеристики конкретности и фонологической длины (слова, которые дети учат первыми, как правило, относятся к конкретным объектам и являются короткими), влияют на скорость лексической замены.
В этой статье мы утверждаем, что целесообразно рассматривать служебные слова (такие как предлоги, союзы, наречия, местоимения и числа) и содержательные слова (существительные, глаголы и прилагательные) по-разному, когда мы пытаемся понять скорость лексической замены.Мы оценим прогностическую силу нескольких потенциальных семантических факторов, определяющих скорость лексической замены содержательных слов, с помощью корреляционных и множественных регрессионных тестов. Сначала мы сосредоточимся на различии между содержательными и служебными словами, и, как только мы убедимся, что стоит продолжать и рассматривать только содержательные слова, мы обратимся к степени их замещения.
Сначала мы сосредоточимся на различии между содержательными и служебными словами, и, как только мы убедимся, что стоит продолжать и рассматривать только содержательные слова, мы обратимся к степени их замещения.
Содержание и функциональные слова
При изучении факторов, влияющих на скорость лексической замены, есть веские причины рассматривать открытые и закрытые классы слов отдельно.Классы открытых слов содержат содержательные слова, такие как язык, камень, женщина, а классы закрытых слов содержат грамматические (функциональные) слова, такие как и, но, три. Классы открытых слов, особенно существительные, пополняются новыми членами (например, когда необходимо назвать новые объекты), в то время как новые грамматические функции появляются в языке реже. Существует также когнитивный разрыв в обработке мозгом содержательных и служебных слов. В то время как клинические пациенты, страдающие экспрессивной афазией, как правило, имеют проблемы с произношением служебных слов и морфосинтаксической структурой, пациенты с рецептивной афазией часто неспособны понимать и выбирать слова правильного содержания во время речеобразования [9]. Имеются также четкие различия в нейрофизиологической активности при обработке служебных слов по сравнению с обработкой содержательных слов [10–12].
Имеются также четкие различия в нейрофизиологической активности при обработке служебных слов по сравнению с обработкой содержательных слов [10–12].
Данные исследования Pagel et al. [2] также свидетельствуют о том, что концепты из открытых и закрытых классов слов ведут себя по-разному в отношении скорости их лексической замены. Классы слов, представленные в данных Pagel et al., принадлежат к двум различным группам: открытые (173 элемента: 40 прилагательных, 58 глаголов и 75 существительных) и закрытые (27 элементов: 3 союза (и, потому что, если), 3 предлогов (в, с, у), 5 числительных (один, два, три, четыре, пять), 7 наречий (здесь, там, как, где, когда, что, не) и 7 местоимений (я, ты, он, мы, вы, они, кто).) классы слов. Регрессионный анализ, проведенный отдельно для каждого языка в исследовании Pagel, показывает, что для слов закрытого класса вариация лексической замены в значительной степени зависит от различий классов слов (56,1% в английском, 51,6% в испанском, 56,1% в русском и 54,4%). % в греческом языке; все p :s < 0,001) и в гораздо меньшей степени по частоте различий (4% в английском, 0,8% в испанском, 5,6% в русском, 1,8% в греческом; все p :s < 0,001). Концепты из открытых классов слов, с другой стороны, составляют гораздо более однородную группу, для которой существенно большая часть вариации коэффициента лексического замещения остается необъяснимой: регрессионный анализ для слов открытого класса показывает, что даже когда частота и класс слов вместе взятые, они объясняют гораздо меньшую часть вариации (14.6% на английском, 15,2% на испанском, 16,2% на русском и 14,3% на греческом; все p :s < 0,0001). Различия в коэффициентах лексической замены между открытыми и закрытыми классами слов показаны на рис. 1. Все рисунки в этой статье были созданы с использованием пакета ggplot2 в статистическом программном обеспечении R [13,14].
% в греческом языке; все p :s < 0,001) и в гораздо меньшей степени по частоте различий (4% в английском, 0,8% в испанском, 5,6% в русском, 1,8% в греческом; все p :s < 0,001). Концепты из открытых классов слов, с другой стороны, составляют гораздо более однородную группу, для которой существенно большая часть вариации коэффициента лексического замещения остается необъяснимой: регрессионный анализ для слов открытого класса показывает, что даже когда частота и класс слов вместе взятые, они объясняют гораздо меньшую часть вариации (14.6% на английском, 15,2% на испанском, 16,2% на русском и 14,3% на греческом; все p :s < 0,0001). Различия в коэффициентах лексической замены между открытыми и закрытыми классами слов показаны на рис. 1. Все рисунки в этой статье были созданы с использованием пакета ggplot2 в статистическом программном обеспечении R [13,14].
Рис. 1. Коэффициент лексической замены в зависимости от нормализованной частоты в английском, греческом, русском и испанском языках для понятий открытых (красный: прилагательные, зеленый: существительные, синий: глаголы) и закрытых (желтый: наречия, серый: союзы, фиолетовый) : числа, бирюзовый: предлоги, оранжевый: местоимения) классы слов соответственно.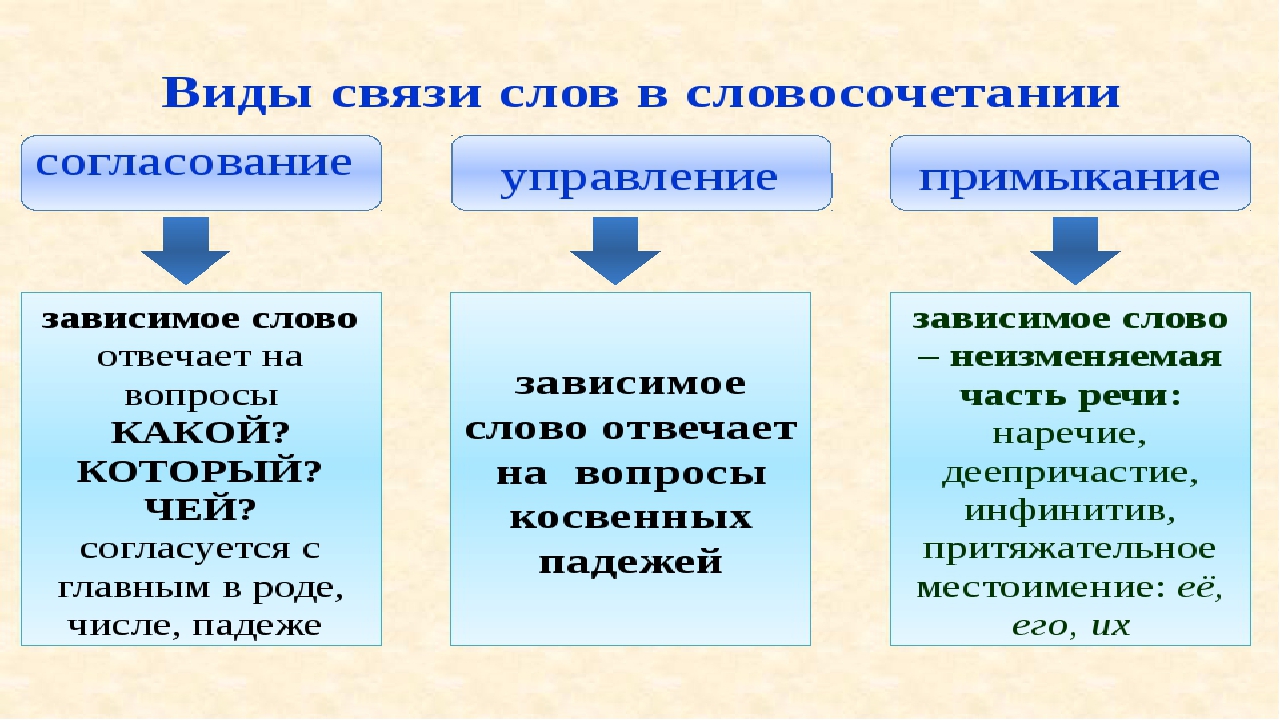
https://doi.org/10.1371/journal.pone.0147924.g001
Поэтому мы предполагаем, что скорость изменения элементов закрытого класса больше связана с идиосинкразическими свойствами отдельного слова. Элементы закрытого класса всегда находятся дальше по континууму грамматизации и, следовательно, более абстрактны и универсальны по смыслу, более широко применимы и чаще используются [15]. В совокупности это говорит о том, что коэффициент лексической замены элементов закрытого класса в большей степени зависит от диахронических процессов конструкций, в которых эти элементы часто встречаются.С другой стороны, коэффициент лексической замены элементов открытого класса может быть менее чувствителен к диахроническим изменениям конкретных конструкций и больше зависеть от лексико-семантических и прагматических факторов этих элементов. Далее мы попытаемся установить, какими могут быть некоторые из этих факторов, используя корреляционный и линейный регрессионный анализ.
Материалы и методы
Прежде всего необходимо признать, что факторов, которые вызывают лексическую замену, вероятно, действительно очень много, и что их взаимодействие, без сомнения, сложно (см.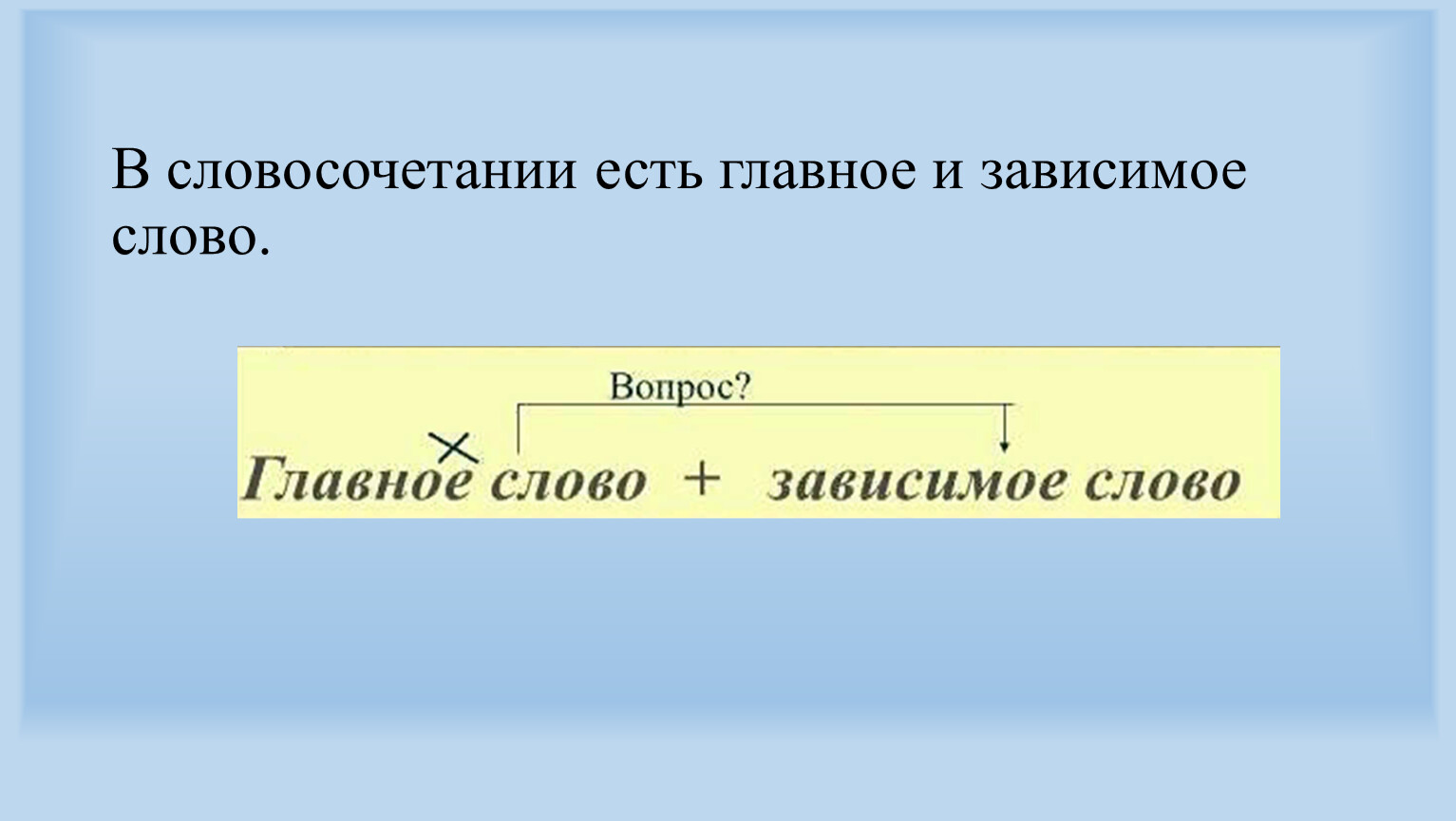 г. Лэдд и др. [6] для обзора исследований взаимодействия таких факторов, как, например, скорость лексической замены, частота и конкретность). Также очень вероятно, что культурные соображения очень важны для замены слов, и что эти культурные соображения различаются между говорящими сообществами и с течением времени. Кроме того, определенные семантические домены (такие как части тела, термины родства, цвета и т. д.), вероятно, имеют специфичные для домена тенденции, когда речь идет о вероятности лексической замены.Наше исследование лексической замены ничего из этого не принимает во внимание, а вместо этого пытается исследовать, возможно ли найти доказательства того, что обобщения, переопределяющие предметную область, какие факторы могут влиять на скорость лексической замены.
г. Лэдд и др. [6] для обзора исследований взаимодействия таких факторов, как, например, скорость лексической замены, частота и конкретность). Также очень вероятно, что культурные соображения очень важны для замены слов, и что эти культурные соображения различаются между говорящими сообществами и с течением времени. Кроме того, определенные семантические домены (такие как части тела, термины родства, цвета и т. д.), вероятно, имеют специфичные для домена тенденции, когда речь идет о вероятности лексической замены.Наше исследование лексической замены ничего из этого не принимает во внимание, а вместо этого пытается исследовать, возможно ли найти доказательства того, что обобщения, переопределяющие предметную область, какие факторы могут влиять на скорость лексической замены.
Сначала мы представим мотивы включения каждого фактора и то, как эти факторы были введены в действие. Далее мы рассмотрим результаты корреляционных и множественных регрессионных тестов.
В этом исследовании исследуется взаимосвязь между семантическими факторами и скоростью лексической замены содержательных слов сверх частотности, класса слов и возраста усвоения — трех факторов, которые, по другим данным, влияют на скорость лексической замены (см. [2,5]). ).Этими факторами являются: совпадение с другими лексическими единицами, измеренное средней взаимной информацией ; визуализируемость ; вероятность эвфемизмов, измеренная с точки зрения возбуждения ; полисемия по количеству смыслов; и, наконец, число синонимов . Далее мы представляем мотивы для включения этих факторов и то, как они используются для статистического тестирования. За исключением данных о частоте и синонимах, все данные взяты из английского языка, возможная оговорка, к которой мы вернемся в ходе обсуждения.
[2,5]). ).Этими факторами являются: совпадение с другими лексическими единицами, измеренное средней взаимной информацией ; визуализируемость ; вероятность эвфемизмов, измеренная с точки зрения возбуждения ; полисемия по количеству смыслов; и, наконец, число синонимов . Далее мы представляем мотивы для включения этих факторов и то, как они используются для статистического тестирования. За исключением данных о частоте и синонимах, все данные взяты из английского языка, возможная оговорка, к которой мы вернемся в ходе обсуждения.
Частота слов и класс слов
Результаты Pagel et al. [2] ясно показывают, что частота слов и класс слов предсказывают скорость лексической замены. Мы также включаем частоту и класс слов в наше исследование. Данные о частоте взяты из среднего значения частот, указанных в Pagel et al. 2007 г. для английского, испанского, русского и греческого языков. Для повышения сопоставимости Pagel et al. данные использовались везде, где это было возможно. Частота слов часто выступает в качестве надежного предиктора в моделях, предсказывающих лексическое закрепление в памяти, но далеко не ясно, что именно измеряет частота использования слов в текстах, когда речь идет о человеческом познании.Баайен (2010) показал, что простое предположение о том, что частота, понимаемая как количество повторений слова, к которому привык говорящий/слушающий («счетчик в голове»), представляет уровни активации или уровень закрепления, может быть слишком ложным. упрощенный. Баайен показывает, что в его модели лексического решения 90% дисперсии частоты слов можно предсказать по другим лексическим свойствам. Он указывает, что, хотя подсчет частоты часто является статистически сильным предиктором, например, Для экспериментов с лексическими решениями подсчет частоты в действительности следует понимать как представляющий широкий спектр свойств лексического распределения, таких как контекстуальное разнообразие, дисперсия по разным типам текстов, соотношение того, как часто слово пишется или произносится и т.
Частота слов часто выступает в качестве надежного предиктора в моделях, предсказывающих лексическое закрепление в памяти, но далеко не ясно, что именно измеряет частота использования слов в текстах, когда речь идет о человеческом познании.Баайен (2010) показал, что простое предположение о том, что частота, понимаемая как количество повторений слова, к которому привык говорящий/слушающий («счетчик в голове»), представляет уровни активации или уровень закрепления, может быть слишком ложным. упрощенный. Баайен показывает, что в его модели лексического решения 90% дисперсии частоты слов можно предсказать по другим лексическим свойствам. Он указывает, что, хотя подсчет частоты часто является статистически сильным предиктором, например, Для экспериментов с лексическими решениями подсчет частоты в действительности следует понимать как представляющий широкий спектр свойств лексического распределения, таких как контекстуальное разнообразие, дисперсия по разным типам текстов, соотношение того, как часто слово пишется или произносится и т. д.Имея это в виду, что частота представляет собой не просто повторение, мы будем продолжать использовать частоту, чтобы не смешивать нашу модель с десятью или более дополнительными переменными, большинство из которых может быть трудно получить для элементов нашего списка Сводеша. данные класса также взяты из Pagel et al. [2].
д.Имея это в виду, что частота представляет собой не просто повторение, мы будем продолжать использовать частоту, чтобы не смешивать нашу модель с десятью или более дополнительными переменными, большинство из которых может быть трудно получить для элементов нашего списка Сводеша. данные класса также взяты из Pagel et al. [2].
Возраст приобретения
Монаган [5] обнаружил, что возраст приобретения коррелирует со скоростью замещения. Как и этот автор, мы используем данные Купермана и др. [16].
Взаимная информация
В качестве показателя частоты Pagel et al. [2] рассмотрели только количество слов, но мы полагаем, что может быть веская причина также включать другой вид измерения частоты, а именно вероятность совпадения с другими словами. Заменить слово, которое часто встречается вместе с другими словами в конструкциях, может быть труднее, чем заменить слово, которое не имеет таких общих сочетаний (например, брат может часто встречаться с сестрой, в то время как to go может не иметь такого сочетания). устойчивый лексический партнер, чтобы закрепить его).Таким образом, ожидается, что любая мера силы одновременности будет отрицательно связана со скоростью замещения.
устойчивый лексический партнер, чтобы закрепить его).Таким образом, ожидается, что любая мера силы одновременности будет отрицательно связана со скоростью замещения.
Вероятность совпадения определялась путем усреднения 20 самых высоких соседей взаимной информации каждого элемента в английском BNC. Взаимная информация — это измерение одновременности, которое дает высокие значения двум элементам, которые часто встречаются одновременно ( соль будет иметь высокое значение МИ с перец ) и низкие значения элементам, которые редко встречаются одновременно ( соль будет иметь низкое значение MI с динозавром ).При расчете МИ для двух слов учитывается частота обоих слов независимо друг от друга и сопоставляется с вероятностью того, что эти слова встречаются вместе. Оценка взаимной информации элементов X и Y определяется как где n(xy) — частота совпадений x и y, n(x) — частота x, n(y) — частота y, а ngramsize — размер исследуемого окна n-граммы. Данные взаимной информации для Британского национального корпуса объемом 100 миллионов слов были извлечены из http://corpus.интерфейс byu.edu/bnc/.
Данные взаимной информации для Британского национального корпуса объемом 100 миллионов слов были извлечены из http://corpus.интерфейс byu.edu/bnc/.
возбуждение
Другим потенциальным фактором лексической замены является количество эвфемизмов понятия. Существует значительный объем исследований о влиянии табу и эвфемизмов на лексические изменения. Языковые табу, безусловно, могут быть очень локальными, но могут быть и если не универсальными, то, по крайней мере, весьма распространенными [17,18]. Как только существует лингвистическое табу, у говорящих есть различные стратегии, чтобы избежать оскорбительного слова [19,20]. Таким образом, эвфемизмы могут привести к большому множеству синонимов и ускоренной лексической замене.Берридж [21] пишет, что «очень немногие эвфемизмы, деградировавшие [путем ассоциации с табуированными темами] до табуированных терминов, возвращаются из бездны, даже после того, как они утратили свой табуированный смысл. Это способствует постоянно меняющейся лексике слов, обозначающих табуированные понятия». Гжега [22] также отмечает, что уничижение является важным фактором лексической замены, а Пинкер [23] назвал этот эффект «беговой дорожкой эвфемизма». Лингвистическое табу не бинарно: понятия могут быть более или менее табуированными и, таким образом, приводить к более или менее лексической замене [21].Хотя зачастую нетрудно указать явные случаи лингвистического табу (например, постоянно меняющийся словарный запас для табуированных понятий спермы, мочи или рвоты), существует также много случаев семантической деториации, когда табу, возможно, является слишком строгим. сильное слово. Гжега [22] приводит пример того, как слова для понятия «девушка» кажутся культурно окрашенными и должны часто меняться, чтобы избежать непреднамеренных ассоциаций, которые они постоянно вызывают, хотя мало кто скажет, что девушки являются табу в e.г. англоязычных обществ. Если можно найти измерение для этого «эмоционального заряда», связанного с понятиями, порождающими эвфемизм, можно было бы ожидать, что он будет положительно связан со скоростью лексической замены: те понятия, которые имеют более высокий эмоциональный заряд (возможно, умереть, женщина) и т.
Гжега [22] также отмечает, что уничижение является важным фактором лексической замены, а Пинкер [23] назвал этот эффект «беговой дорожкой эвфемизма». Лингвистическое табу не бинарно: понятия могут быть более или менее табуированными и, таким образом, приводить к более или менее лексической замене [21].Хотя зачастую нетрудно указать явные случаи лингвистического табу (например, постоянно меняющийся словарный запас для табуированных понятий спермы, мочи или рвоты), существует также много случаев семантической деториации, когда табу, возможно, является слишком строгим. сильное слово. Гжега [22] приводит пример того, как слова для понятия «девушка» кажутся культурно окрашенными и должны часто меняться, чтобы избежать непреднамеренных ассоциаций, которые они постоянно вызывают, хотя мало кто скажет, что девушки являются табу в e.г. англоязычных обществ. Если можно найти измерение для этого «эмоционального заряда», связанного с понятиями, порождающими эвфемизм, можно было бы ожидать, что он будет положительно связан со скоростью лексической замены: те понятия, которые имеют более высокий эмоциональный заряд (возможно, умереть, женщина) и т. д. .. и те, которые приводят к большему количеству эвфемизмов, будут подвергаться словесной замене быстрее, чем те, которые имеют меньший эмоциональный заряд (камень, идти).
д. .. и те, которые приводят к большему количеству эвфемизмов, будут подвергаться словесной замене быстрее, чем те, которые имеют меньший эмоциональный заряд (камень, идти).
Вероятность того, что понятие порождает множество эвфемизмов, операционализируется другим общепринятым в психологии показателем: возбуждение .Возбуждение (вместе с валентностью и силой) измеряется методом семантического дифференциала (впервые разработанным Осгудом [24]) с помощью опросников, в которых говорящие оценивают слово по нескольким различным осям. Высокое возбуждение означает, что слово вызывает у участника больше эмоций, чем низкое. В этом исследовании используются данные Warriner et al. [25].
Образность
Существует заметная разница между высоко образными (то есть легко вообразимыми в уме) и менее образными понятиями.Во многих психолингвистических исследованиях изучалась разница в обработке мозгом этих двух категорий понятий: Пайвио [26] основывает теорию двойного кодирования когнитивной организации частично на различии между обработкой легко визуализируемых и трудно визуализируемых слов. Кратч и Уоррингтон [27] также пишут о принципиальных различиях между категориями. Мартенссон и др. [28] показывают, что существительные, связанные с сенсорными семантическими (зрительными и иными) характеристиками, обрабатываются в разных частях мозга, чем те, которые этого не делают.Была проделана работа над различиями между легко и не так легко изображаемыми существительными [29], а также в глаголах [30]. Связь между способностью к воображению и лексической заменой, в частности, между низкой способностью к воображению и медленной лексической заменой, также была выявлена в пилотном исследовании [3], в котором изучалась лексическая замена в словарном запасе для понятий как в индоевропейском, так и в австронезийском языках. Ожидается, что те понятия, которые легче вообразить и изобразить в сознании говорящих (камень, в отличие от старых), будут подвергаться меньшему количеству словесных замен.Таким образом, любая мера изобразительности будет иметь отрицательную связь со скоростью замещения.
Кратч и Уоррингтон [27] также пишут о принципиальных различиях между категориями. Мартенссон и др. [28] показывают, что существительные, связанные с сенсорными семантическими (зрительными и иными) характеристиками, обрабатываются в разных частях мозга, чем те, которые этого не делают.Была проделана работа над различиями между легко и не так легко изображаемыми существительными [29], а также в глаголах [30]. Связь между способностью к воображению и лексической заменой, в частности, между низкой способностью к воображению и медленной лексической заменой, также была выявлена в пилотном исследовании [3], в котором изучалась лексическая замена в словарном запасе для понятий как в индоевропейском, так и в австронезийском языках. Ожидается, что те понятия, которые легче вообразить и изобразить в сознании говорящих (камень, в отличие от старых), будут подвергаться меньшему количеству словесных замен.Таким образом, любая мера изобразительности будет иметь отрицательную связь со скоростью замещения.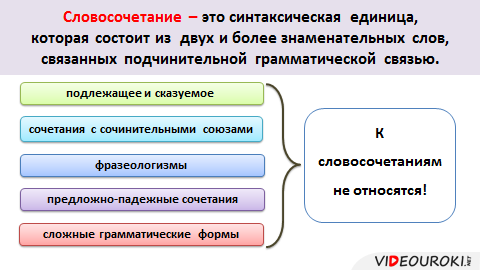
При измерении способности к воображению участников спрашивают, насколько легко сформировать ментальный образ при предъявлении определенного слова. Тесно связанной с образностью семантической характеристикой является конкретность: в этом случае участников спрашивают, насколько конкретно слово (см. Hills and Adelman [31] для обсуждения того, как конкретность взаимодействует с обучаемостью и использованием слова). Монаган [5] показывает, что конкретность коррелирует со скоростью лексической замены, используя данные Brysbaert et al [32].В этом исследовании используются данные об имидже от Cortese & Fugett [33], которые опубликовали рейтинги имиджа от носителей английского языка для многих английских слов. Данные по визуализируемости Cortese & Fugett и Brysbaert et al. данные о конкретности элементов Сводеша сильно коррелируют (r = 0,88 p < 0,0001).
Чувства
Степень многозначности основного слова понятия и, следовательно, многозначности может также влиять на скорость его лексической замены. Многозначные слова могут использоваться в более различных жанрах, чем малозначительные слова, и это может привести к большему укоренению, которое, таким образом, может в некоторой степени изолировать слово от замещения (см. обсуждение укоренения в [34]). Следовательно, измерение количества семантических смыслов должно иметь отрицательную связь со скоростью замены.
Многозначные слова могут использоваться в более различных жанрах, чем малозначительные слова, и это может привести к большему укоренению, которое, таким образом, может в некоторой степени изолировать слово от замещения (см. обсуждение укоренения в [34]). Следовательно, измерение количества семантических смыслов должно иметь отрицательную связь со скоростью замены.
В исследовании количество смыслов было определено на основе лексической базы данных Wordnet English [35], где все лексические единицы помечены тем, сколько у них значений.
Синонимы
Наконец, есть веские основания подозревать, что количество синонимов понятия связано с коэффициентом его лексической замены. Имеются убедительные доказательства из психологии и нейробиологии, что слова и значения в уме хранятся в некой сетевой структуре ([36], глава 10). В задачах на ассоциации, где участников просят свободно ассоциировать от заданного слова-стимула, целевое слово, как правило, семантически связано со словом-стимулом с точки зрения координации (слова, которые семантически группируются вместе, например, бабочка и мотылек, и часто имеют общий гипероним). ), словосочетание (слова, которые часто встречаются вместе со стимулом, например, соль и вода, яркое и красное), суперординация (насекомое вызывается бабочкой) и синонимия (голодный и голодный) [37].В задачах на лексическое решение, в которых испытуемые определяют, является ли слово-стимул правильным словом или бессмысленным словом, время ответа ниже [38], а нейрофизиологический ответ на лексико-семантический процесс снижается [39], когда целевому слову предшествует целевое слово. семантически родственное слово. Таким образом, семантически связанные слова предшествуют друг другу, указывая на то, что они совместно активируются во время лексического доступа и, таким образом, психологически связаны. Трауготт и Дашер [34] пишут, что основной движущей силой регулярных семантических изменений является прагматизм, и что если слово приобретается или заменяется для определенного понятия, это происходит постепенно.Прагматический когнитивный инструмент логического вывода является важной частью лексической замены и изменения: если значения M1 и M2 каким-то образом семантически связаны, W2, обозначающее M2, может посредством логического вывода обозначать M1.
), словосочетание (слова, которые часто встречаются вместе со стимулом, например, соль и вода, яркое и красное), суперординация (насекомое вызывается бабочкой) и синонимия (голодный и голодный) [37].В задачах на лексическое решение, в которых испытуемые определяют, является ли слово-стимул правильным словом или бессмысленным словом, время ответа ниже [38], а нейрофизиологический ответ на лексико-семантический процесс снижается [39], когда целевому слову предшествует целевое слово. семантически родственное слово. Таким образом, семантически связанные слова предшествуют друг другу, указывая на то, что они совместно активируются во время лексического доступа и, таким образом, психологически связаны. Трауготт и Дашер [34] пишут, что основной движущей силой регулярных семантических изменений является прагматизм, и что если слово приобретается или заменяется для определенного понятия, это происходит постепенно.Прагматический когнитивный инструмент логического вывода является важной частью лексической замены и изменения: если значения M1 и M2 каким-то образом семантически связаны, W2, обозначающее M2, может посредством логического вывода обозначать M1. Таким образом, можно ожидать, что концепции, которые в большей степени вовлечены в большее количество выводов, будут заменяться чаще.
Таким образом, можно ожидать, что концепции, которые в большей степени вовлечены в большее количество выводов, будут заменяться чаще.
Элементы с более семантическими связями с другими элементами могут иметь более высокие шансы на замену, поскольку это означает, что заменить элемент ближайшим синонимом будет проще.Следовательно, количество синонимов понятия должно быть положительно связано с коэффициентом лексической замены.
В исследовании количество синонимов слова измеряется путем подсчета количества предложенных синонимов в словарях синонимов. Для английских данных синонимы взяты из Оксфордского карманного американского тезауруса [40], так как из него оказалось легко автоматически извлекать данные. Однако словари синонимов содержат не только синонимы, но и распространенные гипонимы и гиперонимы, а также метафорические синонимы.Некоторые слова имеют больше метафорических синонимов, чем другие. В любом случае все эти семантические отношения являются свидетельством семантических связей, и для краткости в этой статье для их обозначения будут использоваться «синонимы».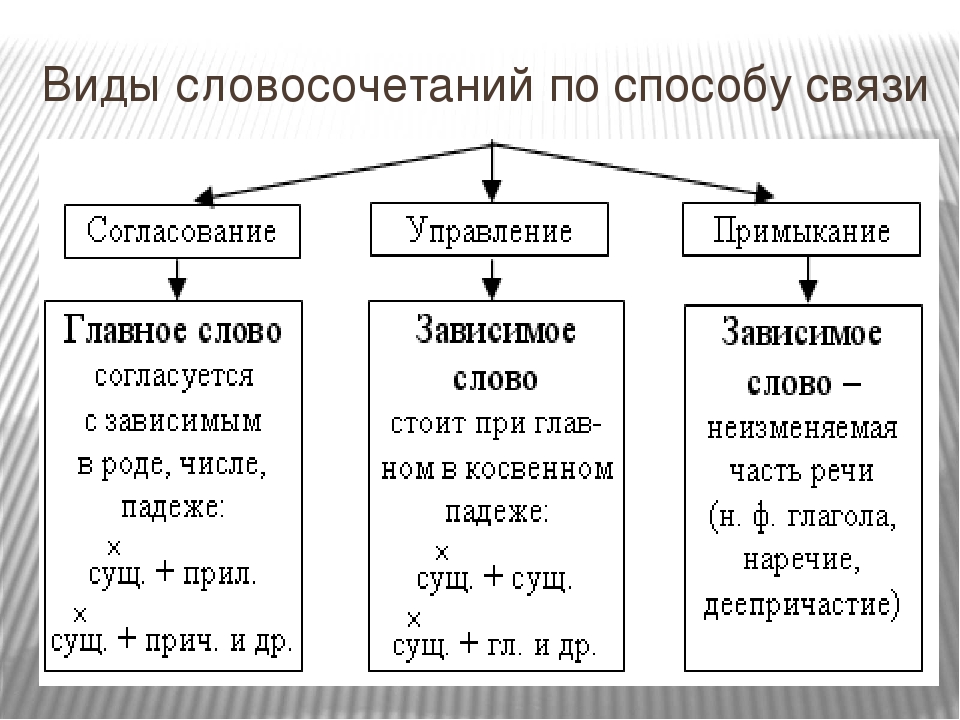 Чтобы получить более сбалансированное среднее количество синонимов для основного понятия, мы также собрали данные из словарей синонимов на четырех других германских языках: шведском [41], датском [42], немецком (http://www.woerterbuch.info/ ) и нидерландском (http://synoniemen.net), и усреднили количество синонимов, сначала взвесив его по многословности конкретного словаря синонимов (если бы среднее количество заданных синонимов было 18, количество синонимов для конкретного слова было бы разделить на 18), а затем усреднить результат по всем пяти языкам.
Чтобы получить более сбалансированное среднее количество синонимов для основного понятия, мы также собрали данные из словарей синонимов на четырех других германских языках: шведском [41], датском [42], немецком (http://www.woerterbuch.info/ ) и нидерландском (http://synoniemen.net), и усреднили количество синонимов, сначала взвесив его по многословности конкретного словаря синонимов (если бы среднее количество заданных синонимов было 18, количество синонимов для конкретного слова было бы разделить на 18), а затем усреднить результат по всем пяти языкам.
Важно иметь в виду, что некоторые из этих переменных не могут быть независимыми друг от друга: некоторые из них могут быть взаимосвязаны. Особое внимание следует уделить тому, как класс слов взаимодействует с различными переменными.
Результаты и обсуждение
Источники данных для независимых переменных в модели обсуждались в предыдущем разделе. Зависимая переменная, скорость лексической замены, взята из [2]. Данные касаются 167 из 173 элементов, перечисленных в [2] как слова открытого класса: отсутствующие шесть элементов перечислены как слова открытого класса, но оцениваются нами как семантически близкие к элементам закрытого класса (это: все, немногие, многие, близкие, другие, некоторые, тот, этот), и так были исключены.
Данные касаются 167 из 173 элементов, перечисленных в [2] как слова открытого класса: отсутствующие шесть элементов перечислены как слова открытого класса, но оцениваются нами как семантически близкие к элементам закрытого класса (это: все, немногие, многие, близкие, другие, некоторые, тот, этот), и так были исключены.
Все статистические анализы были проведены с помощью статистического программного обеспечения R, в основном с интегрированным статистическим пакетом [13]. Предикторы частоты, ощущений и возраста приобретения были логарифмически преобразованы, чтобы иметь приблизительно нормальное распределение. В качестве начального анализа были исследованы корреляции между всеми непрерывными переменными. Матрица корреляции с корреляциями Пирсона между всеми переменными показана в таблице 2. Как видно из таблицы, коэффициент лексической замены значительно коррелирует с частотой, возрастом приобретения, синонимами, взаимной информацией и образностью.
Существует также высокая корреляция между многими самими зависимыми переменными (например, синонимы и смыслы, взаимная информация и образность). Поэтому неясно, действительно ли коэффициент лексического замещения индивидуально связан с имеющимися переменными, или же эти отношения опосредованы взаимозависимостью между самими зависимыми переменными.
Поэтому неясно, действительно ли коэффициент лексического замещения индивидуально связан с имеющимися переменными, или же эти отношения опосредованы взаимозависимостью между самими зависимыми переменными.
Чтобы решить эту проблему, данные были проанализированы с использованием множественного регрессионного моделирования. Этот метод моделирует нормально распределенную непрерывную переменную, переменную результата, как линейную комбинацию набора независимых переменных или предикторов.Важно отметить, что модель оценивает индивидуальные взаимосвязи между каждым предиктором и переменной результата, контролируя влияние всех других переменных-предикторов в модели путем их частичного исключения. Модель содержит непрерывные предикторы, показанные в таблице 2, вместе с предиктором класса слов (т. е. класс слова, частота (в логарифмической форме, далее LogFrequency), возраст приобретения (далее LogAgeofAcq), образность, взаимная информация, синонимы, чувства ( далее LogSense) и Arousal).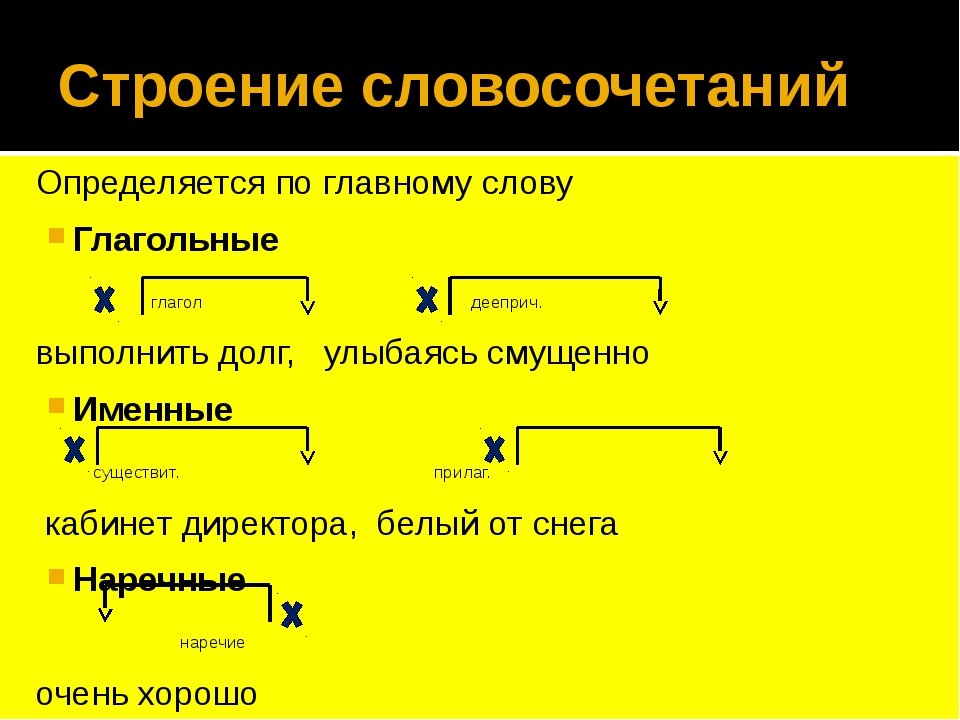
Проблема линейной регрессии заключается в том, что переоснащает регрессионной модели. Если модель содержит слишком много предикторов по отношению к размеру выборки, коэффициенты модели могут быть чрезмерно оптимистичными, и предсказания модели не будут распространяться за пределы данных выборки (см., например, [43]). Переобучение оценивали с помощью бутстрап-валидации. Суммарное переобучение оценивали путем расчета коэффициентов усадки γ 0 и γ 1 на основе 10000 бутстрепных образцов с использованием пакета boot [44].Модель обновляется для каждой выборки начальной загрузки, и наблюдаемые значения исходного набора данных регрессируют по сравнению с прогнозируемыми значениями каждой модели начальной загрузки. Затем γ 0 и γ 1 оцениваются как среднее значение точек пересечения и наклонов бутстрэп-моделей. Коэффициенты существенно не отличались от точки пересечения и наклона наблюдаемых значений, регрессировавших по сравнению с предсказанными значениями исходной модели (т. 41, Z = -0,92, р = 0,36; γ 1 = 0,87, Z = 0,95, p = 0,34) (ср. [45, 46, 47]).
41, Z = -0,92, р = 0,36; γ 1 = 0,87, Z = 0,95, p = 0,34) (ср. [45, 46, 47]).
Последней проблемой линейной регрессии является (мульти)коллинеарность, то есть корреляция между двумя или несколькими предикторами в модели. Коллинеарные предикторы могут по отдельности не учитывать дисперсию переменной результата. Это, в свою очередь, увеличивает стандартные ошибки оценок коэффициентов и, следовательно, снижает достоверность этих оценок. Как показано в таблице 2, высокая корреляция между отдельными предикторами вместе с показателями фактора инфляции дисперсии (макс. VIF: 5.9), который оценивает корреляции между отдельным предиктором и всеми другими предикторами модели (см., например, Harrell, 2010: 65), указывает на то, что мультиколлинеарность может быть проблемой. Поэтому бутстрэппинг также использовался для проверки значимости отдельных предикторов независимо от их стандартных ошибок. Оценки предикторов были рассчитаны на основе 10 000 бутстрап-выборок, показанных в таблице 3. Статистика предикторов бутстрап-модели подтверждает эффекты предикторов в исходной модели с точки зрения как направления эффекта, так и значимости (см. табл. 3), и, следовательно, свидетельствует о стабильность предикторов.
Статистика предикторов бутстрап-модели подтверждает эффекты предикторов в исходной модели с точки зрения как направления эффекта, так и значимости (см. табл. 3), и, следовательно, свидетельствует о стабильность предикторов.
Таблица 3. Коэффициенты β и статистика вывода исходной и бутстрепной модели.
Таблица также включает 95% точечные доверительные интервалы для коэффициентов, основанные на квантилях 0,025 и 0,975 оценок коэффициентов 10000 выборок начальной загрузки. Таблица также включает ΔR 2 для каждого предиктора, то есть долю дисперсии коэффициента лексической замены, объясненную каждым предиктором, по сравнению со всеми другими предикторами в модели.По техническим причинам переменная класса слов, которая имеет три значения (глагол, существительное или прилагательное), представлена в виде трех разных двоичных переменных: класс слов: существительное, класс слов: глагол, класс слов: прилагательное, и последняя из них не введен в модель, так как его информация уже есть: если что-то не является глаголом или существительным, это прилагательное.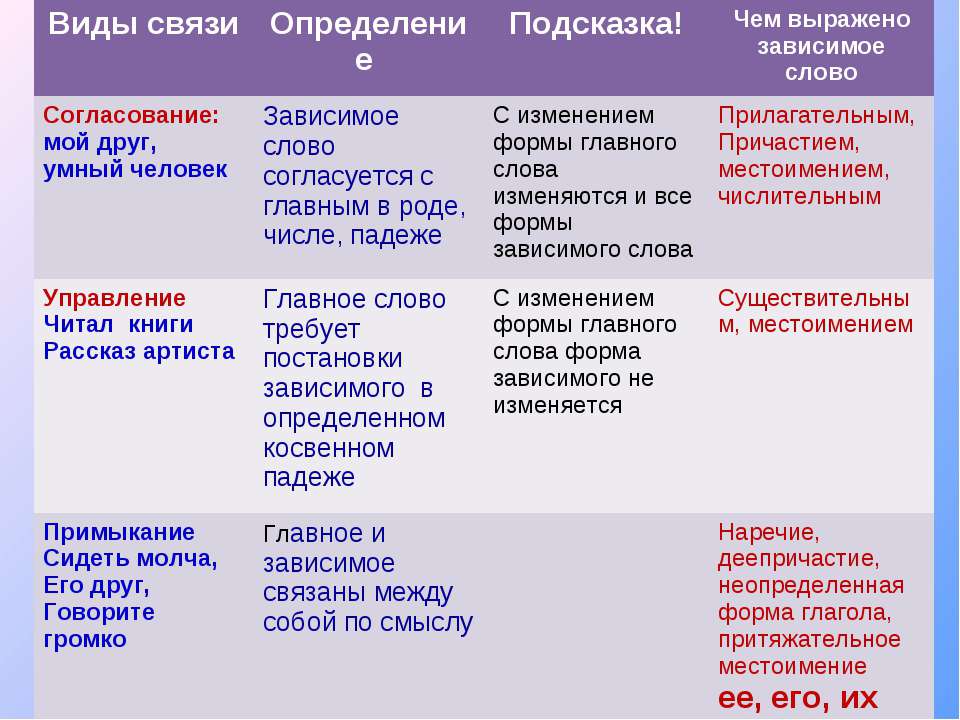
https://doi.org/10.1371/journal.pone.0147924.t003
Модель показывает достойную посадку (N = 117, R 2 = 0.34, F (9, 99) = 5,62, p < 0,0001), что объясняет около 34% дисперсии коэффициента лексической замены. Важно отметить, что соответствие значительно лучше, чем у модели, включающей только логарифмическую частоту и класс слов в качестве предикторов (χ 2 (6) = 247,42, p < 0,0001). Статистика предиктора показана в таблице 3, которая включает статистику как исходной, так и бутстрепной модели. В последнем столбце сообщается ΔR 2 каждого предиктора, который является мерой доли дисперсии коэффициента лексической замены, объясненной каждым отдельным предиктором, по сравнению со всеми другими предикторами в модели.ΔR 2 рассчитано с помощью пакета lmSupport [48].
Результаты регрессионного моделирования повторяют результаты Pagel et al. [2], показав, что частота слов является сильным предиктором скорости лексической замены. Частота объясняет примерно 16,3% его дисперсии после учета влияния всех других предикторов: чем чаще встречается понятие, тем меньше вероятность замены его первичной лексической формы, о чем свидетельствует отрицательный знак бета-коэффициента. .
Частота объясняет примерно 16,3% его дисперсии после учета влияния всех других предикторов: чем чаще встречается понятие, тем меньше вероятность замены его первичной лексической формы, о чем свидетельствует отрицательный знак бета-коэффициента. .
Таблица 3 также показывает, что образность концепта также связана с уменьшением скорости его лексической замены. Предиктор Imageability объясняет около 6,1% дисперсии коэффициента замещения. Хотя мы не обнаружили существенной корреляции между коэффициентом лексической замены и LogSenses (см. Таблицу 2), существует значительный эффект LogSenses, объясняющий около 3,4% дисперсии коэффициента лексического замещения, когда все другие факторы контролируются для: понятий, чьи первичные формы с большим числом смыслов демонстрируют слабое, хотя и значительное, снижение коэффициента лексической замены.Этот негативный эффект проявляется при контроле синонимов и показан на рис. 2: когда концепты группируются по среднему количеству синонимов, обнаруживается сильная отрицательная связь между LexicalReplacementRate и LogSenses.
Рис. 2. Диаграммы рассеяния зависимости между скоростью лексической замены и logSenses.
На левой панели показана взаимосвязь между коэффициентом лексической замены и LogSenses для трех различных уровней синонимов (Низкий: 0–0.65 означают синонимы; Средний: 0,65–1,1 означает синонимы; и Высокий: 1,1–2,65 означают синонимы). На правой панели показана взаимосвязь между коэффициентом лексической замены и LogSenses, когда среднее количество синонимов не контролируется. Заштрихованные области представляют 95% доверительные интервалы наклонов линий регрессии.
https://doi.org/10.1371/journal.pone.0147924.g002
Важно отметить, что модель также показывает, что среднее количество синонимов, перечисленных в словарях синонимов для понятия, почти так же сильно связано с коэффициентом лексической замены. как частота.Предиктор Synonyms объясняет около 12,5% дисперсии коэффициента замещения. Чем больше среднее количество синонимов, используемых для понятия, тем больше вероятность того, что его первичная форма будет заменена. Наконец, регрессионная модель показывает, что индивидуальные отношения между коэффициентом лексического замещения и взаимной информацией (см. Таблицу 2) на самом деле опосредованы другими переменными в модели: как только их влияние учтено, связь исчезает.
Наконец, регрессионная модель показывает, что индивидуальные отношения между коэффициентом лексического замещения и взаимной информацией (см. Таблицу 2) на самом деле опосредованы другими переменными в модели: как только их влияние учтено, связь исчезает.
Аналогичным образом, в отличие от Монагана [5], мы не обнаружили связи между скоростью лексической замены и возрастом овладения, когда хотя бы частота контролировалась.Дополнительный регрессионный анализ, в котором скорость лексической замены была регрессирована по отношению к возрасту приобретения и частоте, также не обнаружил значительного влияния возраста приобретения на скорость лексической замены. Мы успешно воспроизвели исследование Монагана для всего набора данных этого исследования из 200 элементов, а затем добавили к этому набору данных бинарную переменную открытый класс (все существительные, глаголы, прилагательные; 173 элемента) / закрытый класс (оставшиеся 27 элементов). Влияние возраста усвоения на скорость лексического замещения на самом деле обусловлено разницей между словами открытого и закрытого классов. Мы провели отдельный анализ данных Моханагана по словам открытого и закрытого классов, соответственно, и не обнаружили значительного влияния возраста приобретения ни в одном из них. Однако, что более важно, когда предиктор класса слов заменяется предиктором, различающим только слова открытого и закрытого классов, тем самым контролируя их различие, анализ полного набора данных не обнаруживает значительного влияния возраста приобретения.
Мы провели отдельный анализ данных Моханагана по словам открытого и закрытого классов, соответственно, и не обнаружили значительного влияния возраста приобретения ни в одном из них. Однако, что более важно, когда предиктор класса слов заменяется предиктором, различающим только слова открытого и закрытого классов, тем самым контролируя их различие, анализ полного набора данных не обнаруживает значительного влияния возраста приобретения.
Влияние возбуждения и класса слов также не было статистически значимым.
Значимые связи между LogFrequency, Synonyms, Imageability и LogSenses, с одной стороны, и коэффициентом лексической замены, с другой, показаны на рис. влияние всех остальных предикторов постоянно. Это делается путем построения коэффициента лексической замены по остаткам каждой переменной-предиктора, регрессировавшей по отношению ко всем другим предикторам.
Рис. 3. Диаграммы рассеяния взаимосвязей между скоростью лексической замены и (A) остаточной логарифмической частотой, (B) остаточной синонимами, (C) остаточной образностью и (D) остаточной смысловой нагрузкой.
Заштрихованные области представляют 95% доверительные интервалы наклонов линий регрессии.
https://doi.org/10.1371/journal.pone.0147924.g003
Выводы
В этой статье мы утверждали, что служебные и содержательные слова ведут себя по-разному в отношении скорости их лексической замены.Предыдущие исследования факторов, влияющих на скорость лексической замены, рассматривали служебные и содержательные слова вместе — при разделении этих двух групп становится ясно, что они ведут себя совершенно по-разному.
Мы также показали, что, в дополнение к частоте, количество синонимов, образность и количество смыслов, связанных с содержательными словесными понятиями, предсказывают скорость лексической замены этих понятий. Чем больше синонимов используется для понятия, тем выше коэффициент лексической замены этого понятия.Мы связываем это с тем, что наличие других семантически близких слов облегчает вывод и замену. Мы также обнаружили отрицательную связь между образностью (т. е. легкостью, с которой понятие изображается в сознании) понятий и коэффициентом их лексической замены. Таким образом, понятия, которые легче представить и представить в сознании говорящих, менее подвержены словесной замене. Хиллс и Адельман [31] отмечают, что конкретность (и, можно предположить, также подобная мера образности) в языке может увеличиваться по мере того, как в нем появляется больше носителей второго языка, что английский делал в течение последних нескольких столетий, и это может способствовать тому, что более конкретные слова более устойчивы с течением времени.Наконец, мы обнаружили небольшую отрицательную связь между числом значений понятия и коэффициентом его лексической замены. Мы предполагаем, что очень часто встречающиеся и многозначные слова (т. е. используемые во многих разных жанрах) прочно укоренились и, следовательно, их труднее заменить.
е. легкостью, с которой понятие изображается в сознании) понятий и коэффициентом их лексической замены. Таким образом, понятия, которые легче представить и представить в сознании говорящих, менее подвержены словесной замене. Хиллс и Адельман [31] отмечают, что конкретность (и, можно предположить, также подобная мера образности) в языке может увеличиваться по мере того, как в нем появляется больше носителей второго языка, что английский делал в течение последних нескольких столетий, и это может способствовать тому, что более конкретные слова более устойчивы с течением времени.Наконец, мы обнаружили небольшую отрицательную связь между числом значений понятия и коэффициентом его лексической замены. Мы предполагаем, что очень часто встречающиеся и многозначные слова (т. е. используемые во многих разных жанрах) прочно укоренились и, следовательно, их труднее заменить.
В отличие от Monaghan (2014), мы не обнаружили связи между скоростью лексической замены и возрастом приобретения, когда хотя бы частота контролировалась. Мы также не смогли показать какого-либо существенного вклада фактора взаимной информации в регрессионной модели, даже несмотря на то, что он значительно коррелирует со скоростью лексической замены сам по себе.Кроме того, хотя некоторый эффект возбуждения на степень замещения некоторых табуированных понятий кажется бесспорным, мы не смогли показать, что это, когда оно измеряется значениями возбуждения, полученными в экспериментах с семантическим дифференциалом, применимо в целом.
Мы также не смогли показать какого-либо существенного вклада фактора взаимной информации в регрессионной модели, даже несмотря на то, что он значительно коррелирует со скоростью лексической замены сам по себе.Кроме того, хотя некоторый эффект возбуждения на степень замещения некоторых табуированных понятий кажется бесспорным, мы не смогли показать, что это, когда оно измеряется значениями возбуждения, полученными в экспериментах с семантическим дифференциалом, применимо в целом.
Недостатком этого исследования является то, что, хотя скорость лексической замены рассчитывается на основе данных из многих различных индоевропейских языков, все независимые переменные основаны на данных либо из нескольких германских языков, либо только из английского.Причина использования в основном данных на английском языке была практической, поскольку в настоящее время нет других языков, на которых были бы завершены существенные усилия по сбору данных, необходимые для сбора данных для зависимых переменных. Дополнительные данные и дальнейшие исследования сделают результаты более надежными для распространения на другие индоевропейские языки. Однако мы считаем, что недостатки независимых переменных должны работать против гипотез, а не в их пользу: уже в этом ограниченном исследовании видны сильные корреляции между переменными, даже если идиосинкразии с e.г. отдельные языковые омонимы должны приводить к большему шуму. Если бы независимые переменные были основаны на данных репрезентативной выборки индоевропейских языков, мы ожидаем, что отношения между ними и скоростью лексической замены будут более сильными, а не более слабыми.
Дополнительные данные и дальнейшие исследования сделают результаты более надежными для распространения на другие индоевропейские языки. Однако мы считаем, что недостатки независимых переменных должны работать против гипотез, а не в их пользу: уже в этом ограниченном исследовании видны сильные корреляции между переменными, даже если идиосинкразии с e.г. отдельные языковые омонимы должны приводить к большему шуму. Если бы независимые переменные были основаны на данных репрезентативной выборки индоевропейских языков, мы ожидаем, что отношения между ними и скоростью лексической замены будут более сильными, а не более слабыми.
В заключение мы пришли к выводу, что есть основания оценивать служебные слова и содержательные слова отдельно по степени их лексической замены и что, помимо частоты, семантические факторы синонимов, смыслов и образов предсказывают скорость лексической замены. содержательных слов.
Благодарности
Авторы благодарят Бернхарда Велхли и Майкла Данна за ценные комментарии к ранним черновикам, а также Томаса Хиллса и команду PlosOne за очень хорошие отзывы и предложения перед публикацией.
Авторские взносы
Инициатива и разработка экспериментов: С.В.Т.Х. Выполняли опыты: SV TH. Проанализированы данные: SV TH. Предоставленные реагенты/материалы/инструменты для анализа: SV TH. Написал статью: SV TH.
Каталожные номера
- 1.Даль О. Рост и поддержание лингвистической сложности [Интернет]. Амстердам; Филадельфия: Джон Бенджаминс; 2004 [цитировано 30 января 2013 г.]. Доступно: http://search.ebscohost.com/login.aspx?direct=true&scope=site&db=nlebk&db=nlabk&AN=148664
- 2. Пейджел М., Аткинсон К., Мид А. Частота употребления слов предсказывает скорость лексической эволюции на протяжении всей индоевропейской истории. Природа. 2007;449(7163):717–20. пмид:17928860
- 3. Вейдемо С.Межъязыковое лексическое изменение: почему, как и как быстро? Материалы WIGL 2010 [Интернет]. Висконсин; 2010. Доступно: http://vanhise.lss.wisc.edu/ling/?q=node/164
- 4.
Калуд А.С., Пейджел М. Как мы используем язык? Общие закономерности в частоте использования слов в 17 языках мира. Philos Trans R Soc B Biol Sci. 2011 г., 4 декабря; 366 (1567): 1101–1107.
- 5. Монаган П. Возраст приобретения предсказывает скорость лексической эволюции. Познание. 9 сентября 2014 г .; 133 (3): 530–4.пмид:25215929
- 6. Лэдд Д.Р., Робертс С.Г., Дедиу Д. Корреляционные исследования в типологической и исторической лингвистике. Лингвист Анну Рев. 2015 Февраль;1(1):140804162027000.
- 7. Клепарски Г. Теория и практика исторической семантики: случай среднеанглийских и раннесовременных английских синонимов девушки/молодой женщины. Люблин: Университетское издательство Люблинского католического университета; 1997.
- 8. Дайен И., Крускал Дж. Б., Блэк П. Индоевропейская классификация: лексикостатистический эксперимент.Филадельфия: Американское философское общество; 1992.
- 9.
Инграм JCL. Нейролингвистика: введение в обработку разговорной речи и ее расстройства. Кембридж: Издательство Кембриджского университета; 2007. 420 с.
- 10. Мюнте Т.Ф., Виринга Б.М., Вейертс Х., Сенткути А., Мацке М., Йоханнес С. Различия потенциалов мозга для слов открытого и закрытого классов: классовые и частотные эффекты. Нейропсихология. 2001 г., январь; 39 (1): 91–102. пмид:11115658
- 11. Кинг Дж., Кутас М.Кто что делал и когда? Использование ERP на уровне слов и статей для мониторинга использования рабочей памяти при чтении. J Cogn Neurosci. 1995 г., июль; 7 (3): 376–95. пмид:23961867
- 12. Диас М.Т., Маккарти Г. Сравнение мозговой активности, вызванной отдельными содержательными и функциональными словами: исследование неявной обработки текста с помощью МРТ. Мозг Res. 2009 г., 28 июля; 1282: 38–49. пмид:19465009
- 13. Основная команда разработчиков R. R: Язык и среда для статистических вычислений [Интернет].Вена, Австрия: R Foundation for Statistical Computing, Вена, Австрия; 2013. Доступно: http://www.R-project.org
- 14.
Уикхем Х. ggplot2: элегантная графика для анализа данных. 1-е изд. 2009. Корр. 3-е издание 2010 года. Нью-Йорк: Спрингер; 2009. 213 с.
- 15. Байби Дж.Л. Частота использования и организация языка [Интернет]. Оксфорд; Нью-Йорк: Издательство Оксфордского университета; 2007 [цитировано 13 марта 2013 г.]. Доступно: http://site.ebrary.com/id/10194230
- 16.Куперман В., Стадтаген-Гонсалес Х., Брисберт М. Рейтинги возраста усвоения 30 000 английских слов. Методы поведения Res. 2012 г., 12 мая; 44 (4): 978–90. пмид:22581493
- 17. Аллан К., Берридж К. Запрещенные слова: табу и языковая цензура. Кембридж, Великобритания; Нью-Йорк: издательство Кембриджского университета; 2006.
- 18. Зализняк А., Булах М., Ганенков Д., Грунтов И., Майсак Т., Руссо М. Каталог семантических сдвигов как база данных для лексико-семантической типологии.Лингвистика. 2012; (50–3): 633–69.
- 19.
Берридж К. Табу, эвфемизм и политическая корректность. В: Браун К., редактор. Энциклопедия языка и лингвистики (второе издание) [Интернет]. Оксфорд: Эльзевир; 2006 [цитировано 12 декабря 2013 г.]. п. 455–62. Доступно: http://www.sciencedirect.com/science/article/pii/B0080448542010920
- 20. Хольцкнехт К.А. Табу на слова и его последствия для лингвистических изменений в семье языков Маркхэма. Ланг Лингвист Меланес.1988; (18): 43–69.
- 21. Берридж К. Табуированные слова. В: Браун К., редактор. Энциклопедия языка и лингвистики (второе издание) [Интернет]. Оксфорд: Эльзевир; 2006 [цитировано 12 декабря 2013 г.]. п. 452–5. Доступно: http://www.sciencedirect.com/science/article/pii/B0080448542007781
- 22. Grzega J. Качественное и количественное представление сил лексических изменений в истории английского языка. Ономасиол онлайн. 2004; 5:15–55.
- 23. Пинкер С.Игра имени. Газета «Нью-Йорк Таймс. 1994 г., 3 апреля;
- 24.
Осгуд К.Э., Сучи Г.Дж., Танненбаум П. Х. Измерение смысла. Урбана: Университет Иллинойса Press; 1957.
- 25. Уорринер А.Б., Куперман В., Брисберт М. Нормы валентности, возбуждения и доминирования для 13 915 английских лемм. Методы поведения Res. 2013 г., 13 февраля;
- 26. Пайвио А. Образы и словесные процессы. Холт, Райнхарт и Уинстон; 1971. 620 с.
- 27. Костыль С.Дж., Уоррингтон Е.К.Абстрактные и конкретные понятия имеют структурно разные репрезентативные рамки. Головной мозг. 2005 г., 3 января; 128 (3): 615–27.
- 28. Мортенссон Ф., Ролл М., Апт П., Хорн М. Моделирование значения слов: нейронные корреляты обработки абстрактных и конкретных существительных. Acta Neurobiol Exp (Warsz). 2011;71(4):455–78.
- 29. Кролл Дж. Ф., Мервес Дж. С. Лексический доступ к конкретным и абстрактным словам. J Exp Psychol Learn Mem Cogn. 1986; 12(1):92–107.
- 30.
Перани Д., Каппа С.Ф., Шнур Т., Теттаманти М., Коллина С. , Роза М.М. и др.Нейронные корреляты обработки глагола и существительного Исследование ПЭТ. Головной мозг. 1999 г., 12 января; 122 (12): 2337–44.
- 31. Хиллз Т.Т., Адельман Дж.С. Недавняя эволюция обучаемости в американском английском с 1800 по 2000 год. Познание. 2015 окт.; 143:87–92. пмид:26117487
- 32. Брисберт М., Уорринер А.Б., Куперман В. Оценки конкретности 40 тысяч общеизвестных английских словесных лемм. Методы поведения Res. 2014 г., сен; 46 (3): 904–11. пмид:24142837
- 33. Кортезе М.Дж., Фьюгетт А.Рейтинги изобразительности для 3000 односложных слов. Behav Res Methods Instrum Comput. 2004 г., 1 августа; 36 (3): 384–7. пмид:15641427
- 34. Трауготт Э., Дашер РБ. Закономерность смысловых изменений. Кембридж; Нью-Йорк: издательство Кембриджского университета; 2002.
- 35.
Fellbaum C. WordNet электронная лексическая база данных. 2-я печать. Кембриджская Массачусетс: MIT Press; 1999.
- 36. Спитцер М. Разум в сети: модели обучения, мышления и действия. Лондон: Книга Брэдфорда; 1999.
- 37. Эйчисон Дж. Слова в уме: введение в ментальный лексикон. Блэквелл; 1994. 314 с.
- 38. Виглиокко Г., Винсон Д.П. Семантическое представление. В: Gaskell MG, Altmann GTM, редакторы. Оксфордский справочник по психолингвистике. Оксфорд; Нью-Йорк: Издательство Оксфордского университета; 2007. с. 195–215.
- 39. Кутас М., Федермайер К.Д. Тридцать лет и подсчет: поиск смысла в компоненте N400 потенциала мозга, связанного с событием (ERP).Анну Рев Психол. 2011;62:621–47. пмид:20809790
- 40. Линдберг, Калифорния, издательство Оксфордского университета. Карманный оксфордский американский тезаурус [Интернет]. Нью-Йорк: Издательство Оксфордского университета; 2012 [цитировано 3 февраля 2013 г.]. Доступно: http://www.oxfordreference.com/view/10.1093/acref/9780195301694.001.0001/acref-9780195301694
- 41. Уолтер Г. Бонньерс синонимордбок. Стокгольм: Боннье; 2000.
- 42. Ингеманн Т. Синонимордбог. См.: Гилдендаль; 2011.
- 43.Бабяк М.А. То, что вы видите, может не совпадать с тем, что вы получаете: краткое нетехническое введение в переоснащение в моделях регрессионного типа. Психозом Мед. 2004 г., июнь; 66 (3): 411–21. пмид:15184705
- 44. Canty A, Ripley B. boot: Bootstrap R (S-Plus) Функции. Пакет R версии 1.3–15. 2013.
- 45. Бааен РХ. Анализ лингвистических данных: практическое введение в статистику с использованием Р. Кембридж, Великобритания; Нью-Йорк: издательство Кембриджского университета; 2008. 353 с.
- 46.Gude JA, Mitchell MS, Ausband DE, Sime CA, Bangs EE. Внутренняя проверка прогнозирующих моделей логистической регрессии для принятия решений в управлении дикой природой. Дикий биол. 1 декабря 2009 г .; 15 (4): 352–69.
- 47.
Харрелл Ф.Э. Стратегии регрессионного моделирования с приложениями к линейным моделям, логистической регрессии и анализу выживания [Интернет]. Нью-Йорк, штат Нью-Йорк: Springer New York; 2001 [цитировано 16 февраля 2015 г.]. Доступно: http://dx.doi.org/10.1007/978-1-4757-3462-1
- 48.Curtin J. lmSupport: Поддержка линейных моделей [Интернет]. 2014. Доступно: http://CRAN.R-project.org/package=lmSupport
 Philos Trans R Soc B Biol Sci. 2011 г., 4 декабря; 366 (1567): 1101–1107.
Philos Trans R Soc B Biol Sci. 2011 г., 4 декабря; 366 (1567): 1101–1107.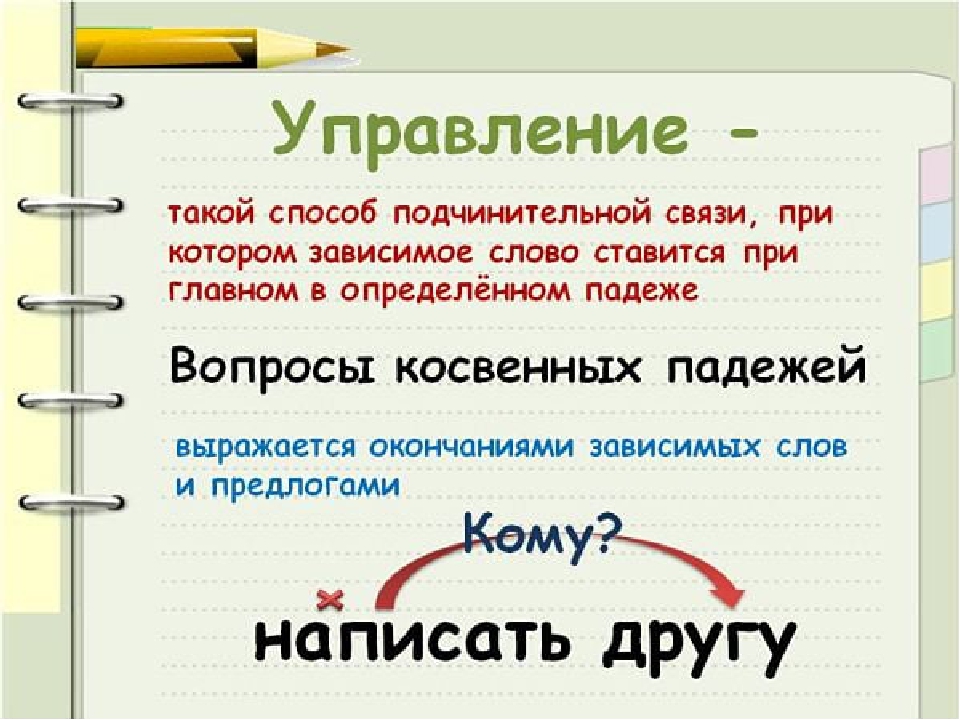 420 с.
420 с.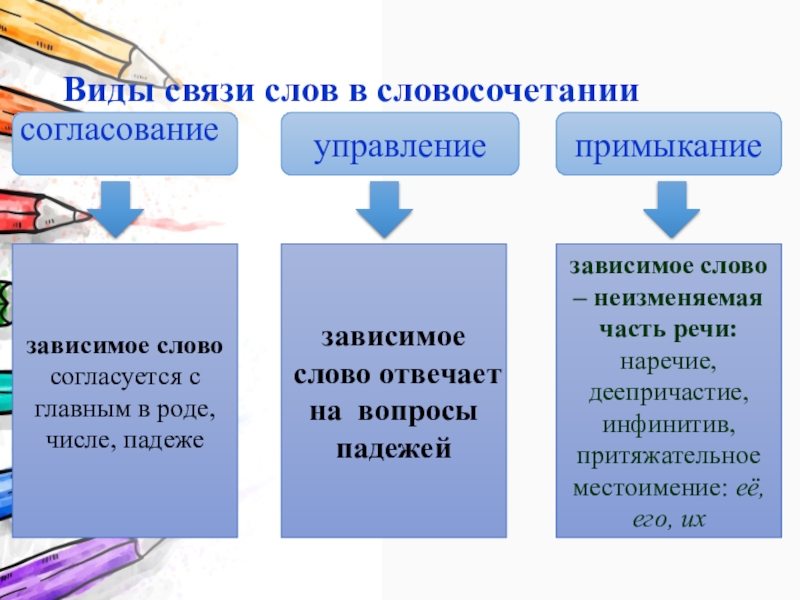 ggplot2: элегантная графика для анализа данных. 1-е изд. 2009. Корр. 3-е издание 2010 года. Нью-Йорк: Спрингер; 2009. 213 с.
ggplot2: элегантная графика для анализа данных. 1-е изд. 2009. Корр. 3-е издание 2010 года. Нью-Йорк: Спрингер; 2009. 213 с. В: Браун К., редактор. Энциклопедия языка и лингвистики (второе издание) [Интернет]. Оксфорд: Эльзевир; 2006 [цитировано 12 декабря 2013 г.]. п. 455–62. Доступно: http://www.sciencedirect.com/science/article/pii/B0080448542010920
В: Браун К., редактор. Энциклопедия языка и лингвистики (второе издание) [Интернет]. Оксфорд: Эльзевир; 2006 [цитировано 12 декабря 2013 г.]. п. 455–62. Доступно: http://www.sciencedirect.com/science/article/pii/B0080448542010920 Х. Измерение смысла. Урбана: Университет Иллинойса Press; 1957.
Х. Измерение смысла. Урбана: Университет Иллинойса Press; 1957. , Роза М.М. и др.Нейронные корреляты обработки глагола и существительного Исследование ПЭТ. Головной мозг. 1999 г., 12 января; 122 (12): 2337–44.
, Роза М.М. и др.Нейронные корреляты обработки глагола и существительного Исследование ПЭТ. Головной мозг. 1999 г., 12 января; 122 (12): 2337–44.
 Уолтер Г. Бонньерс синонимордбок. Стокгольм: Боннье; 2000.
Уолтер Г. Бонньерс синонимордбок. Стокгольм: Боннье; 2000. Нью-Йорк, штат Нью-Йорк: Springer New York; 2001 [цитировано 16 февраля 2015 г.]. Доступно: http://dx.doi.org/10.1007/978-1-4757-3462-1
Нью-Йорк, штат Нью-Йорк: Springer New York; 2001 [цитировано 16 февраля 2015 г.]. Доступно: http://dx.doi.org/10.1007/978-1-4757-3462-1Word2Vec для фраз — изучение встраивания более чем одного слова | by Moshe Hazoom
Мы можем легко создавать биграммы с нашим неконтролируемым корпусом и использовать их в качестве входных данных для Word2Vec. Например, предложение «Я шел сегодня в парк» будет преобразовано в «Я_шел_шел_сегодня_сегодня_в_парк», и каждая биграмма будет рассматриваться как униграмма в обучающей фразе Word2Vec.Он будет работать, но есть некоторые проблемы с этим подходом:
- Он выучит эмбеддинги только для биграмм, при этом многие из этих биграмм не имеют особого смысла (например, «walked_today») и мы пропустите вложения для uni-gram, такие как «гулял» и «сегодня».
- Работа только с биграммами создает очень разреженный корпус. Подумайте, например, о приведенном выше предложении «Сегодня я ходил в парк». Допустим, целевое слово — «walked_today», этот термин не очень распространен в корпусе, и у нас не будет много контекстных примеров, чтобы изучить репрезентативный вектор для этого термина.

Итак, как решить эту проблему? как мы извлекаем только значимые термины, сохраняя слова как униграммы, если их взаимная информация достаточно сильна? Как всегда ответ внутри вопроса — взаимная информация .
Взаимная информация (МИ)
Взаимная информация между двумя случайными величинами X и Y является мерой зависимости между X и Y. Формально:
Взаимная информация (МИ) случайных величин X и Y.В нашем случае , X и Y представляют все биграммы в корпусе, такие что y идет сразу после x.
Точечная взаимная информация (PMI)
PMI является мерой зависимости между конкретными вхождениями x и y. Например: x=прошел, y=сегодня. Формально:
Например: x=прошел, y=сегодня. Формально:
Легко видеть, что когда два слова x и y встречаются вместе много раз, но не поодиночке, PMI(x;y) будет иметь высокое значение, а значение 0, если x и y полностью независимы.
Нормализованная поточечная взаимная информация (NPMI)
Хотя PMI является мерой зависимости появления x и y, у нас нет верхней границы его значений [3].Нам нужна мера, которую можно сравнивать между всеми биграммами, поэтому мы можем выбирать только биграммы выше определенного порога. Мы хотим, чтобы показатель PMI имел максимальное значение 1 для идеально коррелированных слов x и y. Формально:
Нормализованная поточечная взаимная информация x и y.Подход на основе данных
Другой способ извлечения фраз из текста — использование следующей формулы [4], которая учитывает количество униграмм и биграмм и коэффициент дисконтирования для предотвращения создания биграмм слишком редких слов.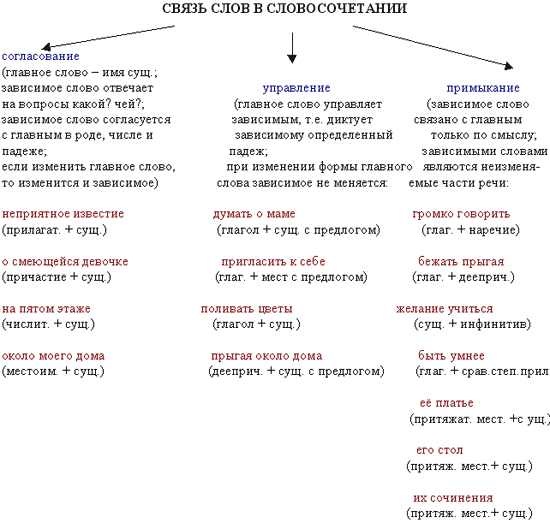 Формально:
Формально:
Теперь, когда у нас есть способ извлекать значимые биграммы из большого неконтролируемого корпуса, мы можем заменить биграммы с NPMI выше определенного порога на одну униграмму, например: «точка перегиба» будет преобразована в « точка_перегиба». Легко создать триграммы, используя преобразованный корпус с биграммами и снова запустив процесс (с более низким порогом) для триграмм форм. Точно так же мы можем продолжить этот процесс до n-грамм с уменьшающимся порогом.
Наш корпус состоит примерно из 60 миллионов предложений, содержащих в общей сложности 1,6 миллиарда слов. Нам потребовался 1 час, чтобы построить биграммы с использованием подхода, управляемого данными. Наилучшие результаты достигаются при пороговом значении 7 и минимальном количестве сроков 5.
Мы измерили результаты с помощью набора оценок, который содержит важные биграммы, которые мы хотим идентифицировать, например, финансовые термины, имена людей (в основном генеральные и финансовые директора).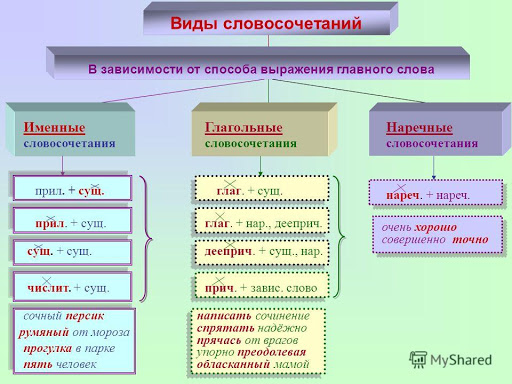 города, страны и т. д. Используемая нами метрика — это простой отзыв: из наших извлеченных биграмм, каково покрытие в оценочном тесте.В этой конкретной задаче нас больше заботит отзыв, а не точность, поэтому мы позволили себе использовать относительно небольшой порог при извлечении биграмм. Мы принимаем во внимание, что наша точность может ухудшиться при снижении порога, и, в свою очередь, мы можем извлечь биграммы, которые не очень ценны, но это предпочтительнее, чем пропустить важные биграммы, при выполнении задачи расширения запроса.
города, страны и т. д. Используемая нами метрика — это простой отзыв: из наших извлеченных биграмм, каково покрытие в оценочном тесте.В этой конкретной задаче нас больше заботит отзыв, а не точность, поэтому мы позволили себе использовать относительно небольшой порог при извлечении биграмм. Мы принимаем во внимание, что наша точность может ухудшиться при снижении порога, и, в свою очередь, мы можем извлечь биграммы, которые не очень ценны, но это предпочтительнее, чем пропустить важные биграммы, при выполнении задачи расширения запроса.
Пример кода
Чтение корпуса строка за строкой (мы предполагаем, что каждая строка содержит одно предложение) с эффективным использованием памяти:
def get_sentences(input_file_pointer):
while True:
строка = input_file_pointer.a-z0-9\s]', '', предложение)
return re.sub(r'\s{2,}', ' ', предложение)
Маркировать каждую строку простым разделителем пробелов (более продвинутые методы для токенизации существуют, но токенизация с помощью простого пробела дала нам хорошие результаты и хорошо работает на практике), а также удалить стоп-слова. Удаление стоп-слов зависит от задачи, и в некоторых задачах НЛП сохранение стоп-слов дает лучшие результаты. Следует оценивать оба подхода. Для этой задачи мы использовали набор стоп-слов Spacy.
Удаление стоп-слов зависит от задачи, и в некоторых задачах НЛП сохранение стоп-слов дает лучшие результаты. Следует оценивать оба подхода. Для этой задачи мы использовали набор стоп-слов Spacy.
с сайта spacy.lang.en.stop_words import STOP_WORDSdef tokenize(sentence):
return [токен для токена в предложении.split(), если токен не в STOP_WORDS]
Теперь, когда у нас есть представления наших предложений в виде двумерной матрицы очищенных токенов, мы можем построить биграммы. Мы будем использовать библиотеку Gensim, которая действительно рекомендуется для семантических задач НЛП. К счастью, в Genim есть реализация для извлечения фраз, как с NPMI, так и с описанным выше подходом Миколова и др. на основе данных. Можно легко управлять гиперпараметрами, такими как определение минимального количества терминов, порога и оценки («по умолчанию» для подхода, основанного на данных, и «npmi» для NPMI).Обратите внимание, что значения различаются между двумя подходами, и это необходимо учитывать.
из gensim.models.phrases import Phrases, Phraserdef build_phrases(sentences):
фразы = фразы(предложения,
min_count=5,
threshold=7,
progress_per=1000)
return Phraser(phrases)
После завершения создав модель фраз, мы можем легко сохранить ее и загрузить позже:txt’)
Теперь, когда у нас есть модель фраз, мы можем использовать ее для извлечения биграмм для заданного предложения:
Мы хотим создать на основе нашего корпуса новый корпус со значимыми биграммами, объединенными вместе для последующего использования:
с open(output_file_name, 'w+') as out_file:
для предложения в get_sentences(input_file_pointer):
clean_sentence = clean_sentence(sentence)
tokenized_sentence = tokenize(cleaned_sentence)
parsed_sentence = Offering_to_bi_grams(n_grams, to_grams, to_grams, to)write(parsed_sentence + '\n')
Руководство по картированию понятий и учебное пособие
Карты понятий основаны на теории ассимиляции Аусубеля и теории обучения Новака, в которых обсуждается, как люди изучают новую информацию, объединяя новые знания со знаниями, которыми они уже обладают. Новак заявил,
Новак заявил,
«Значащее обучение включает в себя ассимиляцию новых концепций и предложений в существующие когнитивные структуры».
Благодаря осмысленному обучению, подробнее обсуждаемому ниже, интеграция новых понятий в структуру наших когнитивных знаний происходит путем связывания новых знаний с уже понятыми понятиями.Карта понятий обеспечивает визуальную демонстрацию этих отношений между понятиями в нашей когнитивной структуре. Происхождение основ концептуальных карт основано на конструктивизме, в котором обсуждается, как учащиеся активно конструируют знания.
Физиологическая основа
Дети приобретают понятия в возрасте от рождения до трех лет, когда они начинают идентифицировать ярлыки или символы для закономерностей, которые они наблюдают в окружающем их мире. Это раннее и автономное обучение известно как процесс обучения открытиями.После трехлетнего возраста начинается процесс обучения приемам, когда новые значения формируются путем постановки вопросов и понимания отношений между старыми и новыми понятиями — понятия больше не определяются учащимся, а описываются другими и передаются учащемуся.
В дополнение к изучению этих двух процессов обучения Ausubel также различает механическое и осмысленное обучение. Заучивание наизусть происходит, когда для представляемой новой информации мало или совсем нет соответствующих знаний, а также нет внутренней приверженности включению новых и существующих знаний.В результате информация легко забывается. Когнитивная структура не улучшается, чтобы прояснить ошибочные идеи.
Осмысленное обучение возможно только при следующих трех обстоятельствах:
Представляемый новый материал должен быть четким и соотноситься с предыдущими знаниями учащегося. Здесь полезны концептуальные карты, так как они определяют общие понятия, которыми владеет учащийся, на которые затем можно опираться.
Учащийся должен обладать соответствующими предварительными знаниями, особенно при попытке понять подробные и конкретные знания в какой-либо области.
Первые два условия могут контролироваться непосредственно инструктором.
Однако третий не может, поскольку требует, чтобы учащийся решил учиться осмысленно. Другими словами, они стараются усваивать новую и старую информацию, а не просто запоминать.
 Однако третий не может, поскольку требует, чтобы учащийся решил учиться осмысленно. Другими словами, они стараются усваивать новую и старую информацию, а не просто запоминать.
Однако третий не может, поскольку требует, чтобы учащийся решил учиться осмысленно. Другими словами, они стараются усваивать новую и старую информацию, а не просто запоминать.Различие между зубрежкой и осмысленным обучением является континуумом, поскольку люди обладают разным объемом соответствующих знаний и разным уровнем мотивации для усвоения знаний.Творчество — это очень высокий уровень осмысленного обучения в этом континууме.
Рабочая и кратковременная память являются наиболее важными для сохранения знаний в долговременной памяти. Информация обрабатывается в рабочей памяти посредством взаимодействия со знаниями в долговременной памяти; однако рабочая память может обрабатывать только небольшое количество единиц за раз. Однако, если эти единицы можно сгруппировать вместе, их гораздо легче вспомнить. Организация больших объемов информации требует повторения между рабочей памятью и долговременной памятью.Картирование понятий эффективно для осмысленного обучения, потому что оно действует как шаблон, помогающий организовать и структурировать знания, даже если структура должна строиться по частям с небольшими единицами взаимодействующих понятий и предложений.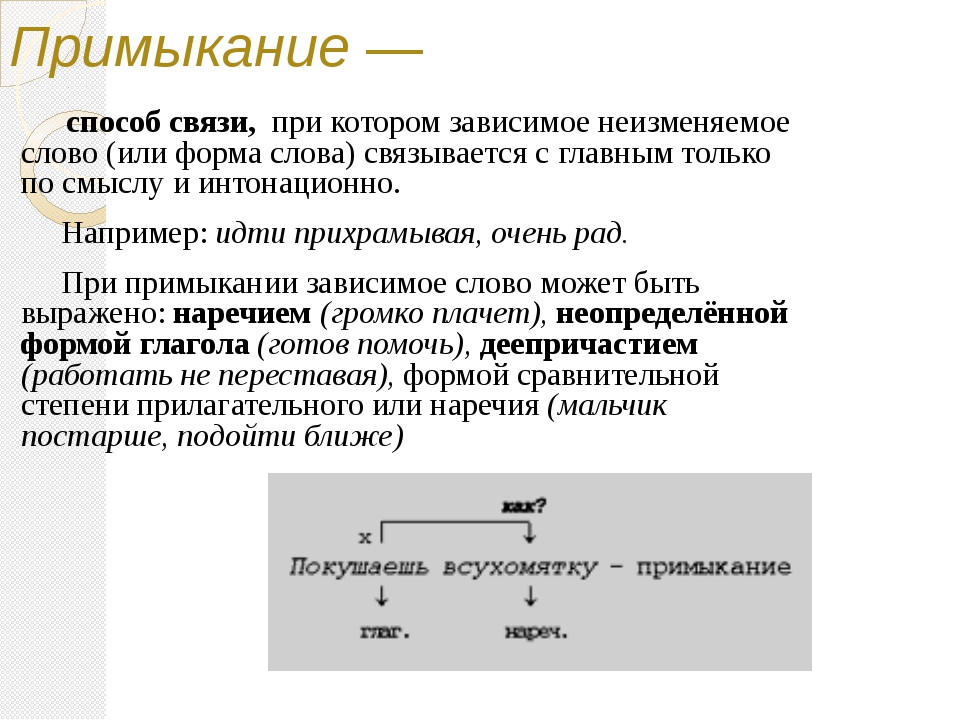 Этот процесс позволяет использовать знания в новых контекстах и увеличивать их запоминание. Кроме того, исследования показывают, что наш мозг предпочитает организовывать информацию в иерархической структуре, характерной для отображения понятий.
Этот процесс позволяет использовать знания в новых контекстах и увеличивать их запоминание. Кроме того, исследования показывают, что наш мозг предпочитает организовывать информацию в иерархической структуре, характерной для отображения понятий.
Эпистемологические основы
Эпистемология – это раздел философии, занимающийся знанием и созданием нового знания.Существует растущий консенсус в отношении того, что создание новых знаний — это конструктивный процесс, в котором участвуют наши знания и наши эмоции. Новак считает, что создание новых знаний — это высокоосмысленное обучение тех, у кого есть организованная структура знаний по определенной теме и сильная мотивация к поиску нового смысла.
Концептуальные карты связаны с конструктивистскими теориями обучения, в которых учащиеся являются активными участниками, а не пассивными получателями знаний. Учащиеся должны приложить усилия, чтобы придать новый смысл информации, которую они уже знают.Создание концептуальных карт — это творческий процесс, поскольку концепции и предложения являются основой знаний в любой области.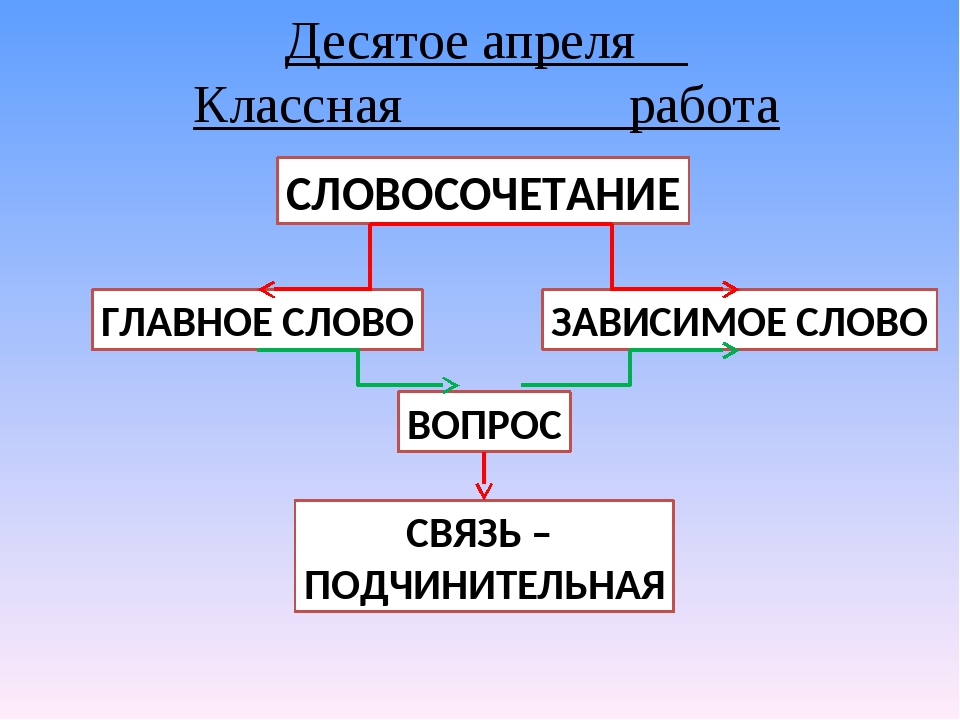
Восемнадцатимесячные младенцы представляют нелокальные синтаксические зависимости
Значение
Будучи зрелыми носителями языка, мы способны производить и понимать неопределенное количество предложений. Эта способность исходит из мощной когнитивной системы — синтаксиса, чьи свойства раскрывают типы вычислений, в которых может участвовать человеческий разум. Одним из основных свойств является способность кодировать абстрактные грамматические зависимости, которые могут сохраняться на расстоянии.Когда это свойство проявляется в развитии? Мы идентифицируем нелокальную зависимость, которую синтаксически представляют 18-месячные младенцы, но не младенцы младшего возраста. Эти данные свидетельствуют о том, что второй год жизни является периодом активного синтаксического развития и что даже до того, как они регулярно произносят собственные полные предложения, младенцы демонстрируют некоторые из основных вычислительных способностей, на которые опирается синтаксис.
Abstract
Способность человека создавать и понимать неопределенное количество предложений определяется синтаксисом, когнитивной системой, которая может комбинировать конечное число примитивных лингвистических элементов для построения произвольно сложных выражений. Выразительная сила синтаксиса частично обусловлена его способностью кодировать потенциально неограниченные зависимости в абстрактных структурных конфигурациях. Как такая система развивается в сознании человека? Мы показываем, что 18-месячные младенцы способны представлять абстрактные нелокальные зависимости, предполагая, что ключевое свойство синтаксиса проявляется на раннем этапе развития. Наш тестовый пример — английский wh -questions, в котором фронтальная wh -фраза может выступать в качестве аргумента глагола на расстоянии (т.г., Что спалил повар? ). В то время как предыдущая работа была сосредоточена на интерпретациях этих вопросов младенцами, мы вводим тест, чтобы исследовать лежащие в их основе синтаксические представления, не зависящие от значения. Мы спрашиваем, когда младенцы знают, что объект wh -фраза и локальный объект глагола не могут встречаться вместе, потому что они оба выражают одно и то же отношение аргумента (например, * Что повар сжег пиццу ).
Выразительная сила синтаксиса частично обусловлена его способностью кодировать потенциально неограниченные зависимости в абстрактных структурных конфигурациях. Как такая система развивается в сознании человека? Мы показываем, что 18-месячные младенцы способны представлять абстрактные нелокальные зависимости, предполагая, что ключевое свойство синтаксиса проявляется на раннем этапе развития. Наш тестовый пример — английский wh -questions, в котором фронтальная wh -фраза может выступать в качестве аргумента глагола на расстоянии (т.г., Что спалил повар? ). В то время как предыдущая работа была сосредоточена на интерпретациях этих вопросов младенцами, мы вводим тест, чтобы исследовать лежащие в их основе синтаксические представления, не зависящие от значения. Мы спрашиваем, когда младенцы знают, что объект wh -фраза и локальный объект глагола не могут встречаться вместе, потому что они оба выражают одно и то же отношение аргумента (например, * Что повар сжег пиццу ). Мы обнаруживаем, что 1) 18-месячные дети демонстрируют осведомленность об этой модели комплементарного распределения и, таким образом, представляют собой нелокальную грамматическую зависимость между wh -фразой и глаголом, а 2) младенцы младшего возраста этого не делают.Эти результаты позволяют предположить, что второй год жизни является периодом активного синтаксического развития, в течение которого проявляются вычислительные способности для представления нелокальных синтаксических зависимостей.
Мы обнаруживаем, что 1) 18-месячные дети демонстрируют осведомленность об этой модели комплементарного распределения и, таким образом, представляют собой нелокальную грамматическую зависимость между wh -фразой и глаголом, а 2) младенцы младшего возраста этого не делают.Эти результаты позволяют предположить, что второй год жизни является периодом активного синтаксического развития, в течение которого проявляются вычислительные способности для представления нелокальных синтаксических зависимостей.
Человеческая способность к языку поддерживается мысленно представленной формальной системой, которая позволяет нам производить и понимать неопределенное количество предложений. Изучение этой формальной системы дает нам представление о видах вычислений, которыми может заниматься человеческий разум, и, следовательно, о том, какие виды структур присущи разуму (1⇓⇓–4).
Вычислительным центром языковых способностей человека является синтаксис. Именно синтаксис дает нам возможность комбинировать конечное число языковых форм для выражения бесконечного числа значений. Синтаксис естественного языка делает это особым образом: он объединяет лингвистические элементы в иерархические, потенциально рекурсивные структуры и кодирует абстрактные зависимости над этими структурами. Например, зависимость между глаголом и его прямым объектом сохраняется независимо от конкретного глагола или конкретного объекта (подчеркнуто):
Синтаксис естественного языка делает это особым образом: он объединяет лингвистические элементы в иерархические, потенциально рекурсивные структуры и кодирует абстрактные зависимости над этими структурами. Например, зависимость между глаголом и его прямым объектом сохраняется независимо от конкретного глагола или конкретного объекта (подчеркнуто):
i. а. Шеф-повар сжег пиццу.
б. Бегун пнул банку.
в. Сотрудник покрасил в синий цвет забор вокруг магазина.
В этих предложениях структурная связь между глаголом сжечь и его дополнением пиццей такая же, как связь между ударом и банкой или между краской и синим забором. магазин .
В то время как в основном декларативном предложении это отношение требует смежности в английском языке ( ii ), в некоторых конструкциях эти отношения могут быть установлены на расстоянии ( iii ).
ii. а. Шеф-повар сжег (*полностью) пиццу.
б. Бегун пнул (*очень сильно) банку.
в. Сотрудник покрасил (*неаккуратно) синий забор, окружающий магазин.
iii. а. Что сжег повар?
б. Что менеджер сказал, что повар сгорел?
в. Что менеджер, которому позвонил заказчик, сказал, что повар сгорел?
Несмотря на то, что фронтальная wh -фраза ( what ) может встречаться довольно далеко от burn в iii , она имеет такое же объектное отношение к глаголу, как и соответствующая фраза ( the pizza ) ) в я .Объект wh -phrase и прямое объектное именное словосочетание (NP) никогда не могут встречаться одновременно ( iv ), что позволяет предположить, что они оба являются выражениями одного и того же отношения аргумента.
Этот тип грамматического действия на расстоянии раскрывает в высшей степени абстрактную природу синтаксиса. Две фразы, которые имеют очень разные поверхностные формы и систематически появляются в разных местах предложения, тем не менее, каждая удовлетворяет зависимости глагол-объект. И эти зависимости могут сохраняться на сколь угодно больших расстояниях и в определенных внутренне сложных структурах ( iii ) — два свойства, свидетельствующие о высокой степени вычислительной мощности человеческой лингвистической системы (5⇓⇓⇓⇓⇓–11).
Две фразы, которые имеют очень разные поверхностные формы и систематически появляются в разных местах предложения, тем не менее, каждая удовлетворяет зависимости глагол-объект. И эти зависимости могут сохраняться на сколь угодно больших расстояниях и в определенных внутренне сложных структурах ( iii ) — два свойства, свидетельствующие о высокой степени вычислительной мощности человеческой лингвистической системы (5⇓⇓⇓⇓⇓–11).
Здесь мы исследуем некоторые из первых этапов разработки этой системы. В то время как иерархическая и рекурсивная структура была в центре внимания многих предшествующих работ в этой области (12⇓⇓⇓⇓–17), мы обращаем наше внимание на абстрактные синтаксические зависимости — центральную область синтаксиса, которая была менее изучена на ранних стадиях разработки. В частности, мы спрашиваем, разделяют ли младенцы нашу способность представлять грамматические действия на расстоянии, даже до того, как они регулярно объединяют слова в предложения в своей собственной речи.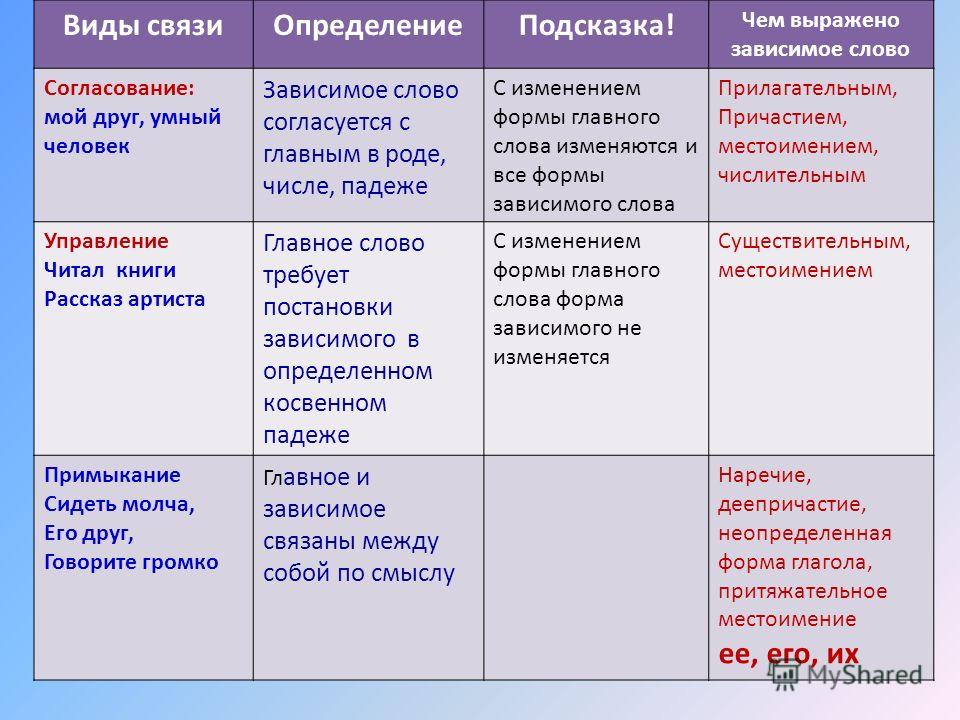 Это помогает понять, присутствуют ли некоторые из основных вычислительных свойств, характеризующих синтаксис, на ранних этапах когнитивного развития, что создает основу для дальнейших вопросов, касающихся происхождения этих вычислительных способностей.
Это помогает понять, присутствуют ли некоторые из основных вычислительных свойств, характеризующих синтаксис, на ранних этапах когнитивного развития, что создает основу для дальнейших вопросов, касающихся происхождения этих вычислительных способностей.
Для ответа на этот вопрос требуется метод выявления синтаксических репрезентаций у младенцев, которые еще не произносят много собственных предложений. Мы часто проверяем синтаксис, спрашивая, как дети понимают предложения (18⇓⇓–21), но это сопряжено с риском того, что кажущееся понимание младенцем предложения в контексте может зависеть от незрелых синтаксических представлений, имитирующих правильные интерпретации.Другой подход изучался, когда младенцы обнаруживают зависимости в предложениях, которые они слышат, не полагаясь на интерпретацию (22⇓⇓⇓⇓⇓–28). Однако в этих случаях поверхностные и синтаксические зависимости часто смешиваются. Ключом к выделению синтаксических зависимостей, не зависящих от значения, является демонстрация того, что младенцы осведомлены о схемах комплементарного распределения, таких как i — iv . Например, нам нужно проверить, когда младенцы знают, что локальный объект и объект wh -phrase не могут встречаться вместе, потому что они оба входят в одну и ту же абстрактную зависимость с глаголом.Мы предоставляем этот тест здесь.
Нелокальные зависимости в младенчестве
Языки различаются по способу выражения синтаксических зависимостей, поэтому дети должны научиться распознавать их на конкретном языке, с которым они сталкиваются. Предыдущая работа показала, что младенцы на втором году жизни обладают способностью распознавать зависимости между несмежными звуками или морфемами как в естественном, так и в искусственном языке (22⇓⇓⇓⇓⇓–28). Например, 18-месячные изучающие английский язык демонстрируют зависимость между is и — ing в таких предложениях, как Археолог копает сокровища (26, 27).Однако трудно определить, как младенцы представляют эти зависимости. В этих исследованиях младенцы могли отслеживать одновременное появление определенных звуков, таких как «is» и «ing», или они могли представлять более абстрактное основное отношение, например, между вспомогательным и глаголом в прогрессивной форме. аспект (26, 27) (см. также ссылки 24 и 25).
Мы обратимся к другому исследованию, которое позволяет лучше разделить эти возможности: нелокальные зависимости предикат-аргумент, обнаруженные в wh -вопросах.В английском языке wh -фразы (например, what ) имеют разные поверхностные формы, чем субъекты и объекты, которые являются локальными для глагола (например, the pizza ). Они также имеют различные дистрибутивы. Например, wh -phrases в подавляющем большинстве встречаются в начале предложения, тогда как локальные объекты канонически появляются после глагола. Таким образом, чтобы младенцы осознали, что одна и та же зависимость глагол-объект присутствует локально в простом переходном предложении ( i ) и на расстоянии в объекте wh -вопрос ( iii ), им необходимо абстрагироваться от эти отличительные свойства поверхности.Недостаточно представлять совпадения определенных звуков или даже знать, что за словом, начинающимся с предложения, например , что , в конце концов последует глагол. Вместо этого младенцы должны представлять нелокальную зависимость абстрактно, как пример того же самого отношения, установленного локально между глаголом и его прямым дополнением.
На сегодняшний день данные о репрезентации wh -вопросов младенцев поступают из двух основных источников. Во-первых, это данные о высказываниях, которые производят младенцы.Второе — это свидетельство того, какие интерпретации они приписывают произнесению предложений, которые слышат. Обе эти меры лишь косвенно касаются вопроса о том, как младенцы представляют структуры предложений, которые они произносят или понимают. Аргумент wh — вопросы начинают появляться в телеграфной речи младенцев примерно в возрасте 20 месяцев (29, 30), но поскольку понимание обычно предшествует воспроизведению (19), это свидетельство не говорит нам, когда младенцы впервые задают эти вопросы в речи. по-взрослому.Что касается понимания, то иногда было показано, что младенцы в возрасте около 15 месяцев адекватно реагируют на wh -вопрос (18, 20, 21). Однако такие ответы могут зависеть от идентификации локальных субъектов и объектов в сочетании с прагматическими рассуждениями, а не от самих нелокальных синтаксических зависимостей.
Например, в предыдущих исследованиях понимания использовались задания на предпочтительное восприятие с младенцами в возрасте от 13 до 20 месяцев, в которых младенцы видели событие или серию событий (например,г., коричневая собака натыкается на кошку, которая затем натыкается на черную собаку), а затем им задают вопрос об этих событиях (например, На какую собаку натолкнулась кошка? ). На экране показывались два возможных ответа (например, две собаки); если бы младенцы больше смотрели на изображение, соответствующее правильному ответу, можно было бы заключить, что младенцы поняли вопрос и, следовательно, представили его синтаксически, как взрослые. Однако реф. 7 и 20 утверждали, что успех в таких задачах не зависит от правильного синтаксического представления зависимостей в этих вопросах.Если младенцы распознали вопрос и поняли, что кошка была подлежащим, а ударить глаголом, они могли бы быть склонны смотреть на собаку, которую кошка ударила, даже не представляя wh -фразу. какая собака как объект глагола. Чтобы определить, представляют ли младенцы нелокальные зависимости сказуемого-аргумента в этих предложениях, необходимо показать, что они осознают комплементарность между wh -фразой и локальным дополнением глагола, как показано в iii. и iv .
Текущее исследование вводит тест, который напрямую исследует эту комплементарность (рис. 1). Используя время слушания младенцев в отсутствие референциального контекста в качестве пробы, мы спрашиваем, отличает ли поведение младенцев wh -вопросы без локального объекта от тех, которые содержат локальный объект, по сути обеспечивая сравнительную меру приемлемости. В нашем задании младенцы слушали блоки слуховых предложений, либо wh -вопросов ( v ), либо описательных ( vi ).Младенцы в обоих условиях слышали предложения с прямым дополнением и без него после глагола, представленные в чередующихся пробах. Все предложения содержали переходные глаголы, которые чаще всего известны детям в возрасте 16 месяцев (31). Пока они слушали, мы показывали видео с абстрактными фигурами, движущимися по экрану, и записывали время взгляда на экран как меру интереса младенцев к этим предложениям (32, 33). Если младенцы отводили взгляд более чем на 2 с, текущее испытание заканчивалось.Когда они переориентировались на экран, было начато новое судебное разбирательство.
v. а. Какую собаку должен обнять кот?
б. * Какую собаку должен обнять кот?
vi. а. *Собака! Кошка должна обниматься.
б. Собака! Кошка должна обнять его.
Схематическое изображение тестовых испытаний в экспериментах с 1 по 4, иллюстрирующее условие wh -вопрос. ( A ) Младенец смотрит абстрактное видео вращающихся фигур на широкоэкранном телевизоре.Во время воспроизведения видео младенец слышит до шести wh -вопросов; младенцы, отнесенные к повествовательному состоянию, слышат до шести повествовательных предложений. Экспериментатор в отдельной комнате в реальном времени кодирует фиксацию глаз младенцев, наблюдая за видеопотоком с камеры, расположенной над телевизором. Когда проиграны все шесть тестовых предложений или младенец отводит взгляд от экрана более чем на две секунды ( B ), проба завершается и отображается стимул, привлекающий внимание. Когда младенец поворачивается к экрану ( C ), начинается следующее испытание.Младенцы слышат чередующиеся пробы предложений без дополнений ( А ) и с дополнениями ( С ).
В этой схеме приемлемость локального объекта переворачивается между двумя критическими парами. Глагол обнять нуждается в прямом дополнении, а какая собака может служить этим дополнением нелокально в wh -вопросе. Это делает локальный объект и неприемлемым в wh -вопросах в v : слишком много объектов.Однако локальный объект требуется в декларативах в vi . Если младенцы знают эти факты, то их предпочтения в отношении предложений (а) и (б) также должны быть перевернуты между этими парами предложений: их относительное предпочтение предложений с локальными объектами должно быть противоположным в wh -вопросительных и декларативных. С другой стороны, предположим, что младенцы знают только, что глаголы в нашем исследовании требуют объектов, но не представляют wh -фраз как удовлетворяющие этому требованию нелокально.Согласно этой гипотезе, их паттерны предпочтений должны быть одинаковыми во всех этих парах предложений. То есть, если они предпочитают предложения с локальными дополнениями в декларативах, то они должны также предпочесть их и в wh -вопросах. †
Результаты
В нашем первом эксперименте мы протестировали 18-месячных младенцев, изучающих английский язык. Этот возраст был выбран по двум причинам. Во-первых, учитывая общую тенденцию к тому, чтобы понимание предшествовало восприятию речи при овладении языком, мы подозревали, что младенцы могут представлять wh -вопросов как таковые в месяцы, предшествовавшие их первой постановке этих вопросов, примерно в 20-месячном возрасте (29, 30 лет). ).Во-вторых, процедура предпочтения прослушивания успешно применялась к младенцам в широком возрастном диапазоне, от 8 до 30 месяцев, и хорошо подходит для поведенческих способностей младенцев в возрасте 18 месяцев и младше (28, 32, 38). Одна группа младенцев ( n = 16) слышала предложения типа v , а другая группа ( n = 16) слышала предложения типа vi .
На рис. 2 мы наносим предпочтения младенцев в отношении времени прослушивания в виде разницы в секундах между общим временем, затрачиваемым на прослушивание предложений с локальными объектами, и общим временем, затрачиваемым на прослушивание предложений без них.Необработанное общее время прослушивания младенцами каждого типа предложений представлено в приложении SI , рис. S1.
Рис. 2.Предпочтения времени поиска 18-летних в эксперименте 1, которые слышали повествовательные предложения ( n = 16), показанные синим цветом, и wh -вопросы ( n = 16) — оранжевым цветом. Точками показаны индивидуальные предпочтения участников, представленные как разница общего времени поиска в секундах в ходе эксперимента для испытаний с локальными объектами минус общее время поиска для испытаний без местных объектов.Положительные числа указывают на предпочтение испытаний с локальными объектами, а отрицательные числа указывают на предпочтение испытаний без местных объектов. Ноль, показанный пунктирной линией, означает отсутствие предпочтения. Сплошные черные линии на каждой прямоугольной диаграмме показывают медианные оценки предпочтений, при этом усы простираются до оценок предпочтений не более чем в 1,5 раза по сравнению с межквартильным диапазоном выше третьего квартиля или ниже первого квартиля.
Мы проанализировали эти данные, сначала сравнив предпочтения младенцев по типам предложений (повествовательные против wh — вопрос).В соответствии с нашими прогнозами мы обнаружили, что предпочтения младенцев в отношении wh -вопросов ( M = -9,35, SE = 4,29) и декларативных вопросов ( M = 17,23, SE = 5,82) значительно отличались друг от друга. (Уэлча t (27,26) = 3,70, P < 0,001, d = 1,31). Затем мы спросили, демонстрируют ли младенцы предпочтения, которые значительно отличаются от нуля для каждого типа предложения. Мы обнаружили, что предпочтения младенцев были надежными в обоих условиях.Младенцы, слышавшие декларативы, отдавали значительное предпочтение предложениям с локальными дополнениями ( t (15) = 2,96, P < 0,01, d = 0,74). Младенцы, которые слышали wh -вопросов, отдавали предпочтение предложениям с локальными дополнениями ( t (15) = -2,23, P < 0,04, d = -0,56), вместо этого предпочитая предложения без локальных дополнений. То есть в обоих условиях младенцы предпочитали слушать грамматические предложения. ‡
Эта схема результатов показывает, что 18-летние осознают взаимодополняемость между wh -фразой и локальным дополнением глагола, что согласуется с гипотезой о том, что младенцы в этом возрасте представляют собой абстрактную зависимость между wh -фраза и глагол, расположенные несколькими словами ниже по течению. Поскольку они предпочитают предложения, в которых глагол встречается без прямого объекта только тогда, когда wh -phrase встречается в начале предложения, мы можем заключить, что младенцы рассматривают wh -phrase как удовлетворяющую потребность глагола в прямом дополнении.
Этот результат дает нам возможность задаться вопросом, сохраняется ли такая же закономерность у детей младшего возраста. Предыдущая литература предполагала, что, хотя младенцы в возрасте 15 месяцев ведут себя так, как будто они понимают wh -вопросы, они не отражают грамматической зависимости между wh -фразой и глаголом (18, 20). Во втором, третьем и четвертом экспериментах мы исследовали это предложение, протестировав группы 14-месячных (Эксперимент 2), 15-месячных (Эксперимент 3) и 17-месячных (Эксперимент 4).Процедуры были идентичны тем, что использовались в эксперименте 1.
Предпочтения прослушивания для экспериментов 2–4 показаны на рис. 3, а необработанное время прослушивания для каждого типа предложения нанесено на график в приложении SI , рис. S2. Наш анализ не выявил значительных предпочтений в отношении декларативных форм или wh -вопросов в каждом эксперименте, а также не обнаружил различий в предпочтениях слушателей по типам предложений. В частности, младенцы не демонстрировали существенных различий в предпочтениях к декларативным и wh -вопросам в возрасте 14 месяцев ( M D = 7.26, SE
9 D = 6.09, м 4 WH 5 = 5,78, SE 4 WH 5 = 8,71, Welch’s T (27.69) = 0,72, P <0,48 , D = 0,05), 15 МО ( м 4 D = -7,84, SE D 5 = 8,57, м 4 WH = -2.26, SE WH = 7,16, Welch’s t (29.08) = -0.50, p <0.62, d = -0,18), или 17 mo ( м d 3 = -3.18, SE D = 5.38, м WH = -4.10, SE SE 4 WH 55 = 5,58, Welch’s T (29,96) = 0,12, P <0,91, D = 0,04). Затем для каждого эксперимента мы сравнили оценки предпочтений младенцев с нулем в обоих условиях. Младенцы, которые слышали декларативы, не демонстрировали значимого предпочтения в пользу или против местных объектов в возрасте 14 месяцев ( t (15) = 1.19, P < 0,25, d = 0,30), 15 мес. 15) = -0,59, P < 0,56, d = -0,15). Точно так же мы не обнаружили значительного предпочтения в пользу или против местных объектов в ответах на вопросы wh в возрасте 14 мес. (15) = -0,32, P < 0,76, d = -0.08), или 17 мес. Рис. 3.Общее время поиска проб с локальными объектами за вычетом проб без локальных объектов для 14 мес (Опыт 2), 15 мес (Опыт 3) и 17 мес (Опыт 4). Для каждого эксперимента предпочтения младенцев, услышавших повествовательные предложения ( n = 16), показаны синим цветом, а младенцы, услышавшие wh -вопросов ( n = 16), показаны оранжевым цветом.
Таким образом, дети в возрасте от 14 до 17 лет в экспериментах 2–4 не демонстрируют той же модели поведения, что и дети в возрасте 18 лет в эксперименте 1. Чтобы выяснить, существенно ли различаются слуховые предпочтения младенцев в этом возрастном диапазоне, мы объединили данные во всех четырех экспериментах. Мы проанализировали время прослушивания младенцами во время каждого испытания, используя линейную модель смешанных эффектов с фиксированными эффектами возраста в днях, состояния (декларативный по сравнению с wh -вопрос), местного объекта и экспериментального блока (подробности в Материалы и методы ). .Для этого и последующих анализов коэффициенты и полные результаты регрессии можно найти в SI, Приложение , таблицы S1–S3. В соответствии с нашими прогнозами наша линейная регрессия смешанных эффектов выявила значительное взаимодействие возраста, состояния и местного объекта ( t (1140) = -1,98, P <0,05) без каких-либо других значительных эффектов. Чтобы визуализировать это взаимодействие, мы построили прогнозы модели в приложении
SI , рис. S3.Чтобы определить, присутствует ли это взаимодействие во всем возрастном диапазоне, мы затем провели линейный анализ модели смешанных эффектов для детей младшего возраста (от 14 до 15 месяцев) и детей старшего возраста (от 17 до 18 месяцев) в отдельных группах. группы.Для младшей группы не было обнаружено значительных основных эффектов или взаимодействий. Для старшей группы мы обнаружили достоверное взаимодействие состояния и местного объекта ( t (564) = 2,03, P < 0,05) и значимое взаимодействие возраста, состояния и местного объекта ( t (564)). = -2,10, P < 0,04), без каких-либо других значительных эффектов. Прогнозы модели для обеих возрастных групп представлены в приложении
SI , рис. S4. Эти результаты показывают, что различные модели слушания младенцами wh -вопросов и декларативных форм проявляются в верхней части нашего возрастного диапазона, развиваясь между 17 и 18 месяцами.Эти результаты согласуются с гипотезой о том, что 14- и 15-летние дети не осознают, что wh -фраза может функционировать как объект глагола на расстоянии, и что это осознание появляется в возрасте от 17 до 18 месяцев. В целом, только 18-летние протестированные нами подростки отличали предложения, в которых отсутствовали объекты из-за более ранней wh -фразы, от тех, в которых просто отсутствовали объекты. Поэтому мы не находим свидетельств того, что дети младшего возраста представляют грамматическую зависимость между wh -фразой и глаголом. §
Обсуждение
Центральным свойством синтаксиса является его способность кодировать абстрактные грамматические зависимости, которые могут сохраняться на расстоянии. Когда это свойство проявляется в когнитивном развитии? Эта работа вносит два вывода для решения этого вопроса. Во-первых, мы показываем, что младенцы обладают способностью представлять нелокальную синтаксическую зависимость в 18 месяцев, прежде чем они начнут регулярно произносить собственные полные предложения. Мы находим, что 18 mo olds представляют нелокальную зависимость предиката-аргумента, присущую wh -вопросу абстрактно, как эквивалент грамматической связи между глаголом и его локальным прямым дополнением.Это говорит о том, что эти абстрактные представления лежат в основе первой постановки младенцами 90 055 wh 90 056 -вопросов, а также их успеха в выполнении задач на понимание после этого возраста (18, 21, 29, 30). Поскольку предыдущая работа по изучению wh вопросов зависела от интерпретации, она лишь косвенно касалась синтаксических репрезентаций этих предложений младенцами. Здесь, сняв вопрос интерпретации, мы получаем более четкий сигнал о синтаксических знаниях младенцев.
Во-вторых, мы показываем, что младенцы младшего возраста по-разному представляют зависимости в этих предложениях.Младенцы в возрасте 15 месяцев могут демонстрировать способность адекватно отвечать на wh -вопросы (18, 20, 21), но мы не находим доказательств того, что они распознают комплементарность между wh -фразой и локальным объектом исследования. глагол. Хотя для изучения этого нулевого результата необходима дальнейшая работа, правдоподобным объяснением является развитие синтаксических знаний: дети младше 18 месяцев могут не представлять эти вопросы как имеющие нелокальную грамматическую зависимость. Этот паттерн, таким образом, согласуется с гипотезой из предыдущей работы, согласно которой разбор только локальных отношений аргументов может привести к пониманию wh -вопросов.
Однако необходима дальнейшая работа, чтобы изолировать синтаксические знания от других факторов, которые могли способствовать поведению детей младшего возраста. Например, младенцы были ознакомлены с существительными и глаголами в нашем исследовании до того, как услышали наши тестовые предложения (см. Материалы и методы ), и возможно, что эта фаза ознакомления могла по-разному повлиять на обработку младенцами тестовых предложений в разные возрасты. ¶ Также возможно, что фраз, которые — фраз в наших wh — вопросах, включенных для прямого сравнения с предложениями, протестированными в предыдущих исследованиях с предпочтительным поиском (18, 20), могли внести синтаксическую или семантическую сложность, чем более молодые младенцы с трудом поддаются обработке.Будущая работа с различными материалами, включая простые фразы wh , такие как who или what , направлена на то, чтобы дифференцировать эти возможности.
Какие механизмы обучения могут быть ответственны за изменение, которое мы наблюдаем между 14 и 18 месяцами? Одна возможность, согласующаяся с более широкой литературой о роли нарушения ожиданий в когнитивном развитии (39⇓⇓–42), заключается в том, что овладение локальными аргументативными отношениями может быть необходимым предшественником идентификации нелокальных зависимостей в целевом языке.В языке со стабильным порядком слов способность учащегося распознавать аргументы в их канонических позициях и распознавать, когда они неожиданно отсутствуют в этих позициях, может заставить учащегося искать в другом месте предложения, чтобы найти недостающий аргумент. Идентификация конкретных поверхностных форм, которые встречаются вместе с отсутствующими аргументами глаголов, может позволить учащемуся распознать, например, что что и что заглавные фразы, которые реализуют отсутствующий аргумент нелокально (18, 20, 30, 43).Ссылка 43 вычислительно показывает, что этот механизм осуществим, но требуется дальнейшая работа, чтобы определить, является ли этот механизм тем механизмом, который учащиеся используют для овладения таким языком, как английский. Таким образом, важным направлением будущей работы является более пристальное изучение развития знаний о структуре аргументов и их взаимодействия с приобретением wh вопросов до 18 мес. В то время как в некоторых работах предлагается знание структуры аргументов, возникающее в начале второго года жизни (44, 45), уточнение того, как это знание взаимодействует с приобретением wh -вопросов, остается важной целью.
Наше тематическое исследование вносит свой вклад в более широкую литературу о развитии синтаксиса как особого типа вычислительной системы: той, которая способна вычислять потенциально неограниченные зависимости над абстрактными структурными конфигурациями и рекурсивно вкладывать эти зависимости (1, 2, 5⇓⇓ ⇓⇓⇓–11). Большая часть этой литературы была сосредоточена на втором из этих свойств, рекурсии, как характерной черте этой системы (12⇓⇓⇓⇓–17). Текущая работа показывает, как первое свойство, сами зависимости, обеспечивает многообещающий путь для изучения синтаксиса.Тот факт, что младенцы раннего возраста способны представлять нелокальную зависимость как структурно эквивалентную локальной зависимости, говорит нам о том, что ключевое вычислительное свойство синтаксиса проявляется очень рано в развитии, когда речь младенцев еще очень телеграфична.
Важным направлением для будущей работы является исследование более тонких деталей того, как 18 лет представляют эту зависимость: являются ли они потенциально неограниченными и определенными для определенных структурных конфигураций, но не для других (9, 10).В частности, текущие данные не касаются вопроса о том, включают ли представления младенцев об этой зависимости иерархическую структуру. Хотя наши результаты показывают, что младенцы распознают, что переходные глаголы могут встречаться без своих объектов только тогда, когда wh -фраза встречается в начале предложения, необходима дальнейшая работа, чтобы продемонстрировать, что они представляют wh -фразу и глагол в конкретном структурные конфигурации, в которых они появляются во взрослой грамматике.Один из способов ответить на этот вопрос — спросить, постепенно ли младенцы анализируют и интерпретируют wh -фразу в позиции прямого объекта во время онлайн-обработки предложений.
Наконец, тот факт, что абстрактные синтаксические репрезентации появляются на втором году жизни, указывает на важную роль обучения на основе опыта и приводит к дискуссии о том, как обучение взаимодействует с ресурсами учащегося для представления лингвистического ввода. С одной точки зрения, репрезентативная способность к вычислению абстрактных синтаксических зависимостей постепенно развивается в детстве; В самых ранних репрезентациях предложений младенцев отсутствуют эти зависимости, потому что их разум приобретает способность представлять их в процессе обучения на их входных данных (29, 46⇓⇓–49).С другой точки зрения, человеческое познание включает в себя эту основную репрезентативную способность абстрактных синтаксических зависимостей, но ее выражение в поведении зависит от механизма определения того, как такие зависимости реализуются в локальной языковой среде (1, 50⇓⇓⇓–54). В то время как текущая работа не различает эти альтернативы, результаты этой статьи устанавливают важный ориентир на временной шкале синтаксического развития, тем самым ограничивая любую теорию о том, когда и как приобретается синтаксическое знание.
Материалы и методы
Все эксперименты с младенцами были одобрены Институциональным наблюдательным советом Университета Мэриленда. Информированное письменное согласие было получено лицом, осуществляющим уход за участником, до начала эксперимента. Нормирующий эксперимент со взрослыми участниками был сертифицирован Институциональным наблюдательным советом Калифорнийского университета в Лос-Анджелесе. Участники дали информированное согласие перед просмотром любых материалов исследования.
Участники.
Участники были набраны из местного населения с условием, что они слышали английский язык не менее 80% времени бодрствования.Участниками Эксперимента 1 были 32 младенца (15 мальчиков) в возрасте от 18,0 до 18,31 года (в среднем = 18,12). Еще девять младенцев были протестированы, но не были включены в выборку из-за того, что они не прошли полный этап ознакомления, как описано в процедуре (два), не прошли полный этап тестирования (пять), суетливость или невнимательность (один) или вмешательство родителей во время исследования (один). Участниками эксперимента 2 были 32 младенца (19 мальчиков) в возрасте от 14,0 до 14,29 лет (в среднем = 14,13).Еще 18 младенцев были протестированы, но не были включены в выборку из-за того, что они не прошли этап полного ознакомления (трое), не прошли этап полного тестирования (семь) или из-за суетливости или невнимательности (восемь). Участниками эксперимента 3 были 32 младенца (16 мальчиков) в возрасте от 15,0 до 15,28 лет (в среднем = 15,14). Были протестированы еще 10 младенцев, но они не были включены в выборку из-за того, что они не прошли полный этап тестирования (три) или из-за беспокойства или невнимательности (семь). Участниками Эксперимента 4 были 32 младенца (17 мальчиков) в возрасте от 17,1 до 17,28 лет (в среднем = 17,14).Еще 18 младенцев были протестированы, но не были включены в выборку из-за того, что они не завершили этап полного ознакомления (четыре), не завершили полный этап тестирования (пять), беспокойства или невнимательности (семь) или вмешательства родителей во время исследования ( два). Критерии исключения беспокойства или невнимательности были консервативными и применялись во время тестирования. Экспериментатор отмечал, если младенец плакал или двигался до такой степени, что взгляд не мог быть надежно закодирован, и данные этого младенца затем исключались из анализа.
Материалы.
Младенцы прослушали 25-секундные пробы, содержащие шесть предложений, по одному на каждый из шести протестированных глаголов ( поцеловать , обнять , пощекотать , ударить , ударить и покрыть ). Эти глаголы были выбраны как высокопереходные, знакомые младенцам в возрасте 16 месяцев (31) и как можно более похожие на глаголы, проверенные в предыдущих экспериментах с предпочтительным видом (18, 20). Глаголы были представлены в псевдослучайном порядке с разными животными в качестве аргументов NP.Эти существительные были 24 животными, описанными в исх. 31 с самыми высокими темпами производства и понимания в 16 мес. Согласно исх. 31,9% американских 16-ти месячных детей произносят и (приблизительно) 70% понимают в среднем # проверенных глаголов; В среднем 21% 16-месячных детей произносят и 55% понимают тестируемые существительные.
Wh- вопросы использовали , где использовалось как wh -слово, чтобы обеспечить как можно более точное сравнение с предыдущими экспериментами (18, 20).Количество и порядок лексических НИ в wh -вопросе и декларативных условиях согласовывались с использованием местоименных дополнений ( him и her ) вместо лексических NP объектов. Фрагменты NP (например, Тигр! ) предшествовали повествовательным предложениям и вводили референт для этих местоимений. Просодический разрыв указывал на границу высказывания между каждым фрагментом и последующим предложением.
Все предложения были записаны женщиной-носителем американского английского языка с использованием детской речи.Чтобы сохранить естественно звучащую просодию, все неграмматические условия были созданы путем соединения двух грамматических предложений. Неграмматические wh -вопросы были созданы путем соединения грамматического wh -вопроса с каузативным предложением ( Какого тигра должен обнять лев + Я заставил льва обнять его = Какого тигра должен обнять лев ). Неграмматические декларативы были созданы путем соединения грамматического декларатива со встроенным вопросом ( Лев должен обнять его + Я знаю, кого лев должен обнять = Лев должен обнять ).Модальное выражение вместо использовалось, чтобы избежать различий в словесной морфологии в разных типах предложений. Полный набор предложений-стимулов указан в SI, Приложение , Таблицы S4–S6.
Звуковые стимулы были отредактированы с помощью Adobe Audition и Praat и объединены с переменной паузой от 750 до 1000 мс между предложениями. Чтобы гарантировать, что соединения в неграмматических предложениях не будут обнаружены, мы собрали суждения выборки из 30 взрослых участников с помощью Amazon Mechanical Turk.Участники прослушали короткие аудиоклипы из наших грамматических и неграмматических предложений, и их попросили указать, какие клипы, по их мнению, были отредактированы (подробности в Приложение SI , Материалы и методы SI ). Участники случайно смогли отличить отредактированные клипы от неотредактированных (среднее d ‘ = -0,07, SE = 0,05; сравнение с нулем: t (29) = -1,28, P <0,21).
Звук для каждого испытания был объединен с одним из двух видеороликов с анимированными медленно вращающимися фигурами в Adobe Premiere.Одно из этих видео использовалось на этапе ознакомления с экспериментом, а другое — на этапе тестирования. Незаметное видео бабочки на листе было отдельно отредактировано для использования в качестве стимула для привлечения внимания.
Процедура.
Во время эксперимента младенцы сидели на коленях у родителей или на стульчике для кормления, расположенном на расстоянии 6 футов от 51-дюймового широкоэкранного телевизора. Родители слушали музыку в наушниках с шумоподавлением, и им было приказано не разговаривать со своими детьми и не направлять их внимание.Стимулы воспроизводились с использованием программы Habit (55). Камера, расположенная над телевизором, использовалась для видеозаписи эксперимента. Поток камеры был подключен к видеомонитору в отдельной комнате, чтобы экспериментатор в отдельной комнате мог в реальном времени кодировать фиксацию глаз младенцев. Экспериментатор не мог слышать звук эксперимента и, следовательно, был слеп к конкретному типу эксперимента, который слышал младенец.
Каждый эксперимент начинался с демонстрации привлекающего внимание стимула.Как только младенец зафиксировался на объекте, привлекающем внимание, экспериментатор начал первое испытание. Во время каждого испытания экспериментатор нажимал клавишу на компьютере, чтобы записать, когда младенец смотрит на экран, и отпускал клавишу, как только младенец отводил взгляд. Испытание заканчивалось после полной 25-секундной продолжительности звукового стимула или после того, как компьютерная программа регистрировала, что младенец непрерывно отводил взгляд от экрана более 2 с. В конце пробы демонстрировался привлекающий внимание стимул.Следующее испытание было начато, как только младенец переориентировался обратно на экран.
Эксперимент состоял из двух этапов. На этапе ознакомления младенцы были ознакомлены как минимум с 72 с из шести тестовых глаголов в основных переходных предложениях с прямым дополнением ( Приложение SI , Таблица S1). Поскольку предшествующий опыт маленьких детей с экспериментальными глаголами может различаться, эта фаза была предназначена для облегчения лексической обработки во время нашего задания, облегчая извлечение этих лексических элементов и структуры их аргументов из памяти.Ознакомительные предложения имели ту же структуру, что и предложения с локальными объектами, представленные в условиях декларативного теста, но не включали ни одно из тех же предложений, представленных в тесте. Чтобы гарантировать, что младенцы в декларативном состоянии подвергались воздействию достаточно новых стимулов во время теста, для ознакомительной и тестовой фаз эксперимента для обоих условий использовались разные видеоролики с вращающимися фигурами.
Были подготовлены четыре ознакомительных пробы продолжительностью 25 секунд, каждая из которых содержала шесть предложений с проверочными глаголами, представленными в псевдослучайном порядке.Порядок ознакомительных испытаний был рандомизирован среди участников. Фаза ознакомления закончилась после пробы, во время которой младенец достиг 72-секундного порога времени взгляда. Если этот порог не был достигнут во время первого представления ознакомительных испытаний, они повторялись в случайном порядке, всего до 12 испытаний. Младенцы, которые не достигли 72-секундного времени взгляда в течение 12 ознакомительных испытаний, были исключены из окончательной выборки.
После этапа ознакомления эксперимент перешел к этапу тестирования.При тестировании младенцы слышали 12 проб повествовательных предложений или wh -предметных вопросов (межиспытуемый фактор), чередуя пробы с локальными предметами и пробы без них (внутрисубъектный фактор) ( SI Приложение , Таблицы S2– С3). Младенцы в каждом состоянии были случайным образом отнесены к одному из четырех списков, уравновешивая два фактора среди участников. Грамматичность первой тестовой пробы была уравновешена за счет того, что половине участников была представлена грамматическая первая тестовая проба, а половине — неграмматическая тестовая проба в их состоянии, а порядок тестовой пробы был уравновешен путем изменения порядка демонстрации пробы для половины участников.Младенцы, которые не завершили все 12 тестовых испытаний или стали чрезмерно беспокойными в ходе эксперимента, были исключены из окончательной выборки.
Линейные модели со смешанными эффектами.
Для анализа нескольких возрастных групп мы построили линейные модели смешанных эффектов, используя пакет lme4 в R (56). Нашей зависимой мерой было общее время поиска в секундах для каждого испытания. Фиксированные эффекты включали возраст в днях, состояние (декларативное по сравнению с wh -вопрос), тип испытания (местный объект или отсутствие локального объекта) и экспериментальный блок (относилось ли испытание к первому, второму или третьему блоку из четырех испытаний в пределах этап тестирования), а также все условия взаимодействия.Факторные контрасты кодировались суммой. Чтобы учесть индивидуальные различия во времени прослушивания в ходе эксперимента, наша полная модель включала случайный отрезок для субъекта и случайный наклон для блока. Поскольку эта подгонка модели была единственной для нашего анализа возрастной группы от 14 до 15 месяцев, эта модель включала только случайную выборку для субъекта. Тесты значимости были проведены с использованием аппроксимации Саттертуэйта для степеней свободы, реализованной с помощью lmerTest (57), который, как было показано, минимизирует ошибку первого рода (58).
Доступность данных
Обезличенные данные размещены в базе данных Open Science Framework (https://osf.io/4sz9w/) (59). Все другие данные исследования представлены в основном тексте и в приложении
SI .Благодарности
Мы благодарим Лизу Фейгенсон, Джастина Халберду, Норберта Хорнштейна, Тима Хантера, Тайлера Ноултона, Эллен Лау, Александра Уильямса и трех анонимных рецензентов за полезные комментарии к предыдущим версиям этой статьи, а также Мину Хирзель, Энни Гальярди. , Тайлеру Ноултону, Таре Миз и Лилианне Райтер за полезные обсуждения и помощь в проведении этих экспериментов.Эта работа была поддержана NSF (BCS-1551629, грант на улучшение докторской диссертации BCS-1827709 и награда NSF за стажировку в области исследований DGE-1449815).
Сноски
- Принято 18 августа 2021 г.
Вклад авторов: Л.П. и Дж.Л. разработали исследование; LP провел исследование; LP и JL проанализировали данные; а LP и JL написали статью.
Авторы заявляют об отсутствии конкурирующих интересов.
Эта статья является прямой отправкой PNAS.Т.Х.М. является приглашенным редактором по приглашению редколлегии.
↵*Обозначает неприемлемость.
↵ † Используя этот метод, сложно предсказать абсолютную направленность предпочтений во времени прослушивания или просмотра в данной задаче, и известно, что направленность предпочтений зависит от возраста (34⇓⇓–37). По этой причине в нашем исследовании важна не абсолютная направленность предпочтений младенцев в отношении предложений с локальными объектами или без них, а то, одинаковы или различны их относительные предпочтения в декларативных вопросах по сравнению с wh -вопросами в любом конкретном возрасте.
↵ ‡ Основные результаты этих тестов t и тестов t , представленных для экспериментов 2–4, совпадают, если они проводятся на основе оценок предпочтения, рассчитанных на основе логарифмически преобразованного времени поиска.
↵ § Хотя 17 плесеней в совокупности не показали признаков приобретения этих репрезентаций, значительное двустороннее взаимодействие состояния и локального объекта, обнаруженное для 17–18 плесеней, оставляет открытой возможность того, что это приобретение происходит позже 17 мес, но раньше 18 мес.Мы оставляем эту возможность для будущих исследований.
↵ ¶ В частности, разумное беспокойство вызывает то, что сходство между нашими предложениями ознакомления и предложениями декларативного теста могло привести к различиям в сложности задачи для младенцев в декларативных условиях по сравнению с wh -вопросными условиями. Тем не менее, общее необработанное время прослушивания младенцами было одинаковым для обоих типов предложений при тестировании: наш линейный анализ модели смешанных эффектов не обнаружил ни основного влияния состояния, ни взаимодействия состояния и возраста ни в возрастном диапазоне от 14 до 18 месяцев, ни в пределах возрастные группы 14 и 15 мес или 17 и 18 мес проанализированы отдельно ( Приложение SI , таблицы S1–S3).Это говорит о том, что требования к задачам существенно не различались в зависимости от условий.
↵ # Реф. 31 не сообщает данные о понимании глагола покрывать , поэтому эта средняя скорость понимания включает данные только для целовать , обнимать , щекотать , ударять и ударять .
Эта статья содержит вспомогательную информацию в Интернете по адресу https://www.pnas.org/lookup/suppl/doi:10.1073/pnas.2026469118/-/DCSupplemental.
- Copyright © 2021 Автор(ы). Опубликовано ПНАС.
Уровни обработки | Просто психология
- Память
- Уровни обработки
Уровни обработки
участвует в памяти и предсказывает, что чем глубже обрабатывается информация, тем дольше сохраняется след памяти.
Крейк определил глубину как:
«осмысленность, извлекаемую из стимула, а не с точки зрения количества проведенных над ним анализов». (1973, стр. 48)
В отличие от модели с несколькими магазинами это неструктурированный подход Основная идея состоит в том, что память — это просто то, что происходит в результате обработки информации
Память — это просто побочный эффект. продукт глубины обработки информации, и нет четкого различия между кратковременной и долговременной памятью.
Таким образом, вместо того, чтобы концентрироваться на задействованных хранилищах/структурах (т. е. кратковременной памяти и долговременной памяти), эта теория концентрируется на процессах, связанных с памятью.
Мы можем обрабатывать информацию тремя способами:
Поверхностная обработка Поверхностная обработка— принимает две формы
1 . Структурная обработка (внешний вид), когда мы кодируем только физические качества чего-либо.Например. шрифт слова или как выглядят буквы.
2 . Фонематическая обработка — когда мы кодируем его звук.
Поверхностная обработка включает только репетицию обслуживания (повторение, чтобы помочь нам удержать что-то в STM) и приводит к довольно кратковременному сохранению информации.
Это единственный тип репетиции в рамках модели с несколькими магазинами.
Глубокая обработка Глубокая обработка— принимает две формы
3 . Семантическая обработка , которая происходит, когда мы кодируем значение слова и связываем его с похожими словами с похожим значением.
Глубокая обработка включает в себя повторную проработку , которая включает более осмысленный анализ (например, образы, размышления, ассоциации и т. д.) информации и приводит к лучшему воспроизведению.
Например, придание словам значения или связывание их с предыдущими знаниями.
Сводка СводкаУровни обработки: идея о том, что способ кодирования информации влияет на то, насколько хорошо она запоминается.Чем глубже уровень обработки, тем легче вспомнить информацию.
Ключевое исследование: Craik and Tulving (1975)
Key Study: Craik and Tulving (1975)
Цель
Исследовать, как глубокая и поверхностная обработка влияет на память.Метод
Участникам была представлена серия из 60 слов, по которым они должны были ответить на один из трех вопросов. Некоторые вопросы требовали от участников глубокой обработки слова (например,г. семантические) и другие неглубокие (например, структурные и фонематические). Например: Затем участникам дали длинный список из 180 слов, в который были смешаны исходные слова. Им было предложено выбрать исходные слова.
Результаты
Участники вспомнили больше слов, которые были обработаны семантически, по сравнению со словами, обработанными фонематически и визуально.Заключение
Семантически обработанные слова включают повторную проработку и глубокую обработку, что приводит к более точному воспроизведению.Слова, обработанные фонематически и визуально, требуют неглубокой обработки и менее точного припоминания.Применение в реальной жизни
Применение в реальной жизни
Это объяснение памяти полезно в повседневной жизни, поскольку оно показывает, каким образом обработка, требующая более глубокой обработки информации, может помочь памяти. Три примера тому.
• Переработка – изложение информации своими словами или обсуждение ее с кем-либо.
• Метод локусов – при попытке вспомнить список предметов, связывая каждый со знакомым местом или маршрутом.
• Образы – создавая образ чего-то, что вы хотите запомнить, вы уточняете его и кодируете визуально (т. е. ментальную карту).
Все вышеприведенные примеры можно использовать для пересмотра психологии с использованием семантической обработки (например, объяснение моделей памяти маме, использование ментальных карт и т. д.) и должны привести к более глубокой обработке с использованием репетиции проработки .
Следовательно, будет запомнено (и вызвано) больше информации, и должны быть достигнуты лучшие результаты экзамена.
Критическая оценка
Критическая оценка
Сильные стороны Сильные стороныНапример, репетиция уточнения приводит к воспроизведению информации, а не просто репетиция обслуживания.
Модель уровней обработки изменила направление исследования памяти.Это показало, что кодирование не было простым и прямым процессом. Это расширило фокус внимания с рассмотрения долговременной памяти как простой единицы хранения на сложную систему обработки.
Идеи Крейка и Локхарта привели к сотням экспериментов, большинство из которых подтвердили превосходство «глубокой» семантической обработки для запоминания информации. Это объясняет, почему одни вещи мы помним намного лучше и дольше, чем другие.
Это объяснение памяти полезно в повседневной жизни, потому что оно показывает, каким образом обработка, требующая более глубокой обработки информации, может помочь памяти.
Несмотря на эти сильные стороны, существует ряд критических замечаний по поводу уровней теории обработки:
• Это не объясняет, как более глубокая обработка приводит к лучшей памяти.
• Более глубокая обработка требует больше усилий, чем неглубокая обработка, и, возможно, именно поэтому, а не глубина обработки повышает вероятность того, что люди что-то запомнят.
• Понятие глубины расплывчато и не поддается наблюдению.Поэтому его нельзя объективно измерить.
Айзенк (1990) утверждает, что уровни теории обработки скорее описывают, чем объясняют. Крейк и Локхарт (1972) утверждали, что глубокая обработка приводит к лучшей долговременной памяти, чем неглубокая обработка. Однако они не смогли подробно объяснить, почему глубокая обработка настолько эффективна.
Однако недавние исследования прояснили этот момент: кажется, что более глубокое кодирование обеспечивает лучшее запоминание, потому что оно более сложное.Детализирующее кодирование обогащает представление объекта в памяти, активируя многие аспекты его значения и связывая его с существовавшей ранее сетью семантических ассоциаций.
Более поздние исследования показали, что процессинг является более сложным и разнообразным, чем предполагают уровни теории процессинга. Другими словами, обработка — это нечто большее, чем глубина и проработка.
Например, исследование Bransford et al. (1979) указали, что такое предложение, как «Комар подобен доктору, потому что оба пускают кровь» с большей вероятностью запомнятся, чем более подробное предложение «Комар похож на енота, потому что у них обоих есть голова, ноги и челюсти». ‘.Оказывается, именно своеобразие первого предложения облегчает его запоминание — необычно сравнивать врача с комаром. В результате предложение выделяется и легче запоминается.
Еще одна проблема заключается в том, что участники обычно тратят больше времени на решение более глубоких и сложных задач. Таким образом, возможно, результаты частично связаны с тем, что на материал было потрачено больше времени. Тип обработки, количество усилий и продолжительность времени, затрачиваемого на обработку, часто путают.Более глубокая обработка требует больше усилий и времени, поэтому трудно понять, какой фактор влияет на результаты.
Идеи «глубины» и «разработки» расплывчаты и плохо определены (Eysenck, 1978). В результате их трудно измерить. Действительно, не существует независимого способа измерения глубины обработки. Это может привести к круговому аргументу: предполагается, что глубоко обработанная информация будет запоминаться лучше, но мерой глубины обработки является то, насколько хорошо информация запоминается.
Уровни теории обработки фокусируются на процессах, связанных с памятью, и поэтому игнорируют структуры. Имеются данные, подтверждающие идею структур памяти, таких как STM и LTM, в качестве предложенной модели с несколькими хранилищами (например, HM, эффект последовательного положения и т. Д.). Следовательно, память сложнее, чем описывается теорией ЯОП.
McLeod, S.А. (2007, 14 декабря). Уровни обработки . Просто психология. www.simplypsychology.org/levelsofprocessing.html
Справочные материалы по стилю APABransford, JD, Franks, JJ, Morris, C.D., & Stein, B.S. (1979). Некоторые общие ограничения на обучение и исследования памяти. В Л.С. Чермак и Ф.И.М. Крейк (ред.), Уровни обработки в памяти человека (стр. 331–354). Хиллсдейл, Нью-Джерси: Lawrence Erlbaum AssociatesInc.
Крейк, Ф.И. М. и Локхарт, Р. С. (1972). Уровни обработки: основа для исследования памяти. Журнал вербального обучения и вербального поведения, 11, 671-684.