Корпуса звучащей речи
О дискурсивной транскрипции
Для графического представления устных данных в проекте используются три вида дискурсивной транскрипции: полная, упрощенная и минимальная. Под дискурсивной транскрипцией понимается такая запись устной речи, при которой, в отличие от фонетической или фонологической транскрипции, основной целью становится не учет звукового состава отдельных словоформ, а фиксация явлений, связанных с организацией локальной дискурсивной структуры. По этой причине, в частности, во всех трех вариантах транскрипции слова за редкими исключениями записываются в стандартной орфографической форме. Все явления, фиксируемые в минимальной транскрипции, также отмечаются и в упрощенной версии, в которой, однако, добавлены некоторые дополнительные компоненты. Полная версия транскрипции включает в себя всю информацию, содержащуюся в упрощенной версии, а также ряд других обозначений, не используемых в упрощенной и минимальной транскрипциях.
Далее будут даны краткие описания трех типов транскрипции, а также приведен список всех
используемых в проекте транскрипционных обозначений.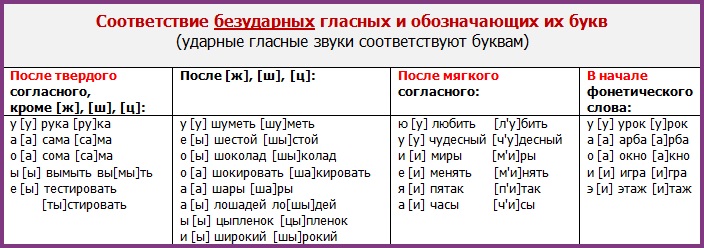
Минимальная транскрипция
Главная задача при выполнении дискурсивной транскрипции — определить, какие именно явления должны в ней отражаться. На наш взгляд, существует два центральных феномена, без отображения которых дискурсивная транскрипция не может считаться таковой. Во-первых, это сегментация речевого потока на минимальные кванты — мы называем их элементарными дискурсивными единицами (ЭДЕ). Во-вторых, это роли, которые ЭДЕ выполняют при построении локальной дискурсивной структуры, объединяясь в более крупные комплексы. Именно эти два явления и отмечаются в минимальной транскрипции. Ниже представлен скриншот минимальной транскрипции начального отрывка одного из рассказов корпуса.
Каждая ЭДЕ выделена в отдельную пронумерованную строку (в крайнем левом столбце
содержится информация о времени начала произнесения ЭДЕ относительно абсолютного
начала звукового файла). Строки 1, 3 и 4 представляют собой простые клаузы, и это
самый частый тип ЭДЕ с точки зрения синтаксического наполнения.

Упрощенная транскрипция
Помимо всей информации, содержащейся в минимальной транскрипции, в упрощенной версии содержатся также указания на важнейшие просодические характеристики речевого потока, непосредственным образом влияющие на его сегментацию и определяющие тип иллокутивно-фазового значения. Ниже приведен скриншот упрощенной транскрипции того же отрывка, минимальная транскрипция которого рассматривалась ранее.
В строках 2, 3 и 5 приведенного примера наличествуют абсолютные паузы — перерывы в
вокализации между произносимыми словами. Абсолютные паузы обозначаются при помощи
поднятых точек, количество которых зависит от продолжительности паузы: паузы от 0.1
до 0.4 секунды оформляются двумя точками, от 0.5 до 0.9 секунды — тремя, начиная с 1.0
секунды — четырьмя. Кроме того, в упрощенной транскрипции при помощи иконических
значков (слэшей) отмечаются движения тона в словах, несущих на себе главный акцент в
ЭДЕ (ударные гласные этих слов дополнительно подчеркнуты). В частности, именно наличие
ощутимого нисходящего акцента в слове вот оправдывает его выделение в отдельную ЭДЕ
(строка 5). В целом, главные акценты (мы их также называем «несущими») выполняют
три важные функции: выступают в качестве интонационного центра, поддерживающего
целостность ЭДЕ; выделяют наиболее значимую для данного дискурсивного шага порцию
информации; посредством связанного с акцентом направления движения тона определяют
роль ЭДЕ в иллокутивной цепочке. Так, восходящее движение тона в строке 1 связано со
значением иллокутивной незавершенности, кодируемым при помощи запятой; нисходящий
акцент в строке 4 коррелирует со значением завершения иллокуции сообщения (точка).
Однако соответствие между пунктуационными знаками и направлением движения тона
не полное: в строках 3 и 5 наблюдается нисходящий тон в несущем акценте, но падение
происходит в недостаточно глубокий уровень и поэтому на конце этих ЭДЕ стоят запятые.
В частности, именно наличие
ощутимого нисходящего акцента в слове вот оправдывает его выделение в отдельную ЭДЕ
(строка 5). В целом, главные акценты (мы их также называем «несущими») выполняют
три важные функции: выступают в качестве интонационного центра, поддерживающего
целостность ЭДЕ; выделяют наиболее значимую для данного дискурсивного шага порцию
информации; посредством связанного с акцентом направления движения тона определяют
роль ЭДЕ в иллокутивной цепочке. Так, восходящее движение тона в строке 1 связано со
значением иллокутивной незавершенности, кодируемым при помощи запятой; нисходящий
акцент в строке 4 коррелирует со значением завершения иллокуции сообщения (точка).
Однако соответствие между пунктуационными знаками и направлением движения тона
не полное: в строках 3 и 5 наблюдается нисходящий тон в несущем акценте, но падение
происходит в недостаточно глубокий уровень и поэтому на конце этих ЭДЕ стоят запятые.
Полная транскрипция
В полной транскрипции отображаются все явления, отмечаемые в минимальной и упрощенной
нотациях, а также некоторые другие феномены, существенные при анализе локальной дискурсивной
структуры. Ниже приведен скриншот уже рассмотренного выше отрывка транскрипции — на этот
раз в полной нотации.
Ниже приведен скриншот уже рассмотренного выше отрывка транскрипции — на этот
раз в полной нотации.
В полной транскрипции продолжительность пауз, определяющая количество точек, используемых для их обозначения, указывается в явном виде в скобках. Кроме того, в транскрипте отмечаются направления тона не только в несущих (главных) акцентах ЭДЕ, но и в прочих словах, произносимых с акцентным выделением — см. знаки перед словами ночью и портфель в строке 3 и словом очень в строке 4. Такие акценты мы называем вторичными, ударные гласные соответствующих слов, в отличие от ударных гласных слов с несущим акцентом, не выделяются подчеркиванием.
В полной транскрипции также отмечаются такие явления, как губные смычки (литера «w»
в конце слова я в строке 2), придыхание, ускоренное произнесение, сниженный регистр и
т. д. Список всех обозначений можно найти в книге «Рассказы о сновидениях: Корпусное
исследование устного русского дискурса» (М.: ЯСК, 2009) под редакцией А. А. Кибрика
и В.
Список транскрипционных обозначений
Ниже представлен список всех обозначений, используемых в полной версии транскрипции. Для каждого обозначения дается описание связанного с ним явления, а также указывается, сохранено ли оно в упрощенной и минимальной нотациях.
| Обозначение | Явление | Отмечается ли в упрощенной транскрипции | Отмечается ли в минимальной транскрипции |
|---|---|---|---|
| Деление на строки | Деление на элементарные дискурсивные единицы (ЭДЕ) | да | да |
| Выделение строки синим цветом | Реплика не принадлежит основному рассказчику | да | да |
| [ ] | Наложение реплик разных участников записи | да | да |
| #СВИСТ# #джжжи# | Идеофоны | да | да |
| ∙∙∙ ээ ’’’’ мм | Абсолютные (∙∙) и заполненные паузы: число символов зависит от длительности паузы | да | нет |
| {ЦОКАНЬЕ} {ЧМОКАНЬЕ} | Неречевые звуки говорящего | да | нет |
(0. 1), (0.5), (1.0) — после обозначения паузы или неречевого звука говорящего 1), (0.5), (1.0) — после обозначения паузы или неречевого звука говорящего | Точная длительность паузы или неречевого звука говорящего | нет | нет |
| / \ – /\ и т. д. (перед словом) | Движения тона в акцентированных словах | только для несущих акцентов | нет |
| Подчеркивание ударной гласной акцентированного слова | Несущий (главный) акцент ЭДЕ | да | нет |
| ↑ | Значимое повышение тона после нисходящего несущего акцента нефинальной ЭДЕ | нет | нет |
| Заглавная бука в начале строки | Начало нового предложения | да | да |
. | Завершение иллокуции сообщения | да | да |
| ? | Завершение иллокуции вопроса | да | да |
| ¡ | Завершение иллокуции директива | да | да |
| @ | Завершение иллокуции обращения | да | да |
| ! | Восклицательность | да | да |
. .. .. | Значение неполноты информации, совмещенное с завершением иллокуции | да | да |
| , | Стандартная незавершенность иллокуции | да | да |
| ,,, | Значение неполноты информации, совмещенное с иллокутивной незавершенностью | да | да |
| : | Незавершенность, восполняемая последующим контекстом | да | да |
| Нуль знака на конце строки | Слитное произнесение двух ЭДЕ (с одним несущим) | да | да |
| « » | Начало и конец прямой цитации | да | да |
| — | Начало и конец сплита (разрыва ЭДЕ) | да | да |
| ( ) | Начало и конец парентезы (вставки предложения внутрь другого предложения) | да | да |
| (* | «Односторонняя парентеза» (начатая, но не завершенная вставка предложения внутрь другого предложения) | да | да |
| = | Обрыв слова | да | да |
| ‖ | Слабый фальстарт (точка прерывания при самоисправлении внутри ЭДЕ) | да | да |
| == | Сильный фальстарт (точка прерывания при самоисправлении на границе ЭДЕ) | да | да |
| ~ | Обрыв ЭДЕ, которая расценивается говорящим как уместная и не подлежащая исправлению | да | да |
| ’ | Гортанная смычка | да | нет |
| w | Губная смычка | нет | нет |
| h | Придыхание | нет | нет |
| ə | Гласный призвук в начале или конце слова | нет | нет |
| а-а с-с й-я я-а | Удлиненная реализация фонем | да | нет |
| Полужирный шрифт | Эмфатическое выделение | да | нет |
| Выделение серым цветом | Редуцированное произнесение | да | нет |
| Курсив | Ускоренный темп | нет | нет |
| Уменьшенный кегль | Сниженный тональный регистр | нет | нет |
| » » | Названия фильмов, машин и т. д. д. | да | да |
| < > | Предположительная транскрипция неразборчивого фрагмента | да | да |
| < | > | Варианты транскрипции неразборчивого фрагмента | да | да |
| <НРЗБ2> | Неразборчивый фрагмент с указанием числа слогов | да | да |
| > < | Разборчивый, но неидентифицируемый фрагмент | да | да |
| >> | Технический обрыв в начале рассказа | да | да |
| << | Технический обрыв в конце рассказа | да | да |
%d1%82%d1%80%d0%b0%d0%bd%d1%81%d0%ba%d1%80%d0%b8%d0%bf%d1%86%d0%b8%d1%8f%20%d0%b8%d0%bd%d0%be%d1%81%d1%82%d1%80%d0%b0%d0%bd%d0%bd%d1%8b%d1%85%20%d1%81%d0%bb%d0%be%d0%b2 — с русского на все языки
Все языкиРусскийАнглийскийИспанский────────Айнский языкАканАлбанскийАлтайскийАрабскийАрагонскийАрмянскийАрумынскийАстурийскийАфрикаансБагобоБаскскийБашкирскийБелорусскийБолгарскийБурятскийВаллийскийВарайскийВенгерскийВепсскийВерхнелужицкийВьетнамскийГаитянскийГреческийГрузинскийГуараниГэльскийДатскийДолганскийДревнерусский языкИвритИдишИнгушскийИндонезийскийИнупиакИрландскийИсландскийИтальянскийЙорубаКазахскийКарачаевскийКаталанскийКвеньяКечуаКиргизскийКитайскийКлингонскийКомиКомиКорейскийКриКрымскотатарскийКумыкскийКурдскийКхмерскийЛатинскийЛатышскийЛингалаЛитовскийЛюксембургскийМайяМакедонскийМалайскийМаньчжурскийМаориМарийскийМикенскийМокшанскийМонгольскийНауатльНемецкийНидерландскийНогайскийНорвежскийОрокскийОсетинскийОсманскийПалиПапьяментоПенджабскийПерсидскийПольскийПортугальскийРумынский, МолдавскийСанскритСеверносаамскийСербскийСефардскийСилезскийСловацкийСловенскийСуахилиТагальскийТаджикскийТайскийТатарскийТвиТибетскийТофаларскийТувинскийТурецкийТуркменскийУдмуртскийУзбекскийУйгурскийУкраинскийУрдуУрумскийФарерскийФинскийФранцузскийХиндиХорватскийЦерковнославянский (Старославянский)ЧеркесскийЧерокиЧеченскийЧешскийЧувашскийШайенскогоШведскийШорскийШумерскийЭвенкийскийЭльзасскийЭрзянскийЭсперантоЭстонскийЮпийскийЯкутскийЯпонский
Все языкиРусскийАнглийскийИспанский────────АлтайскийАрабскийАрмянскийБаскскийБашкирскийБелорусскийВенгерскийВепсскийВодскийГреческийДатскийИвритИдишИжорскийИнгушскийИндонезийскийИсландскийИтальянскийКазахскийКарачаевскийКитайскийКорейскийКрымскотатарскийКумыкскийЛатинскийЛатышскийЛитовскийМарийскийМокшанскийМонгольскийНемецкийНидерландскийНорвежскийОсетинскийПерсидскийПольскийПортугальскийСловацкийСловенскийСуахилиТаджикскийТайскийТатарскийТурецкийТуркменскийУдмуртскийУзбекскийУйгурскийУкраинскийУрумскийФинскийФранцузскийЦерковнославянский (Старославянский)ЧеченскийЧешскийЧувашскийШведскийШорскийЭвенкийскийЭрзянскийЭсперантоЭстонскийЯкутскийЯпонский
правила чтения французского языка | Французский язык изучение
Таблица соответствия французских букв звукам:
| Aa [a] | Jj [Ʒ] | Ss [s], см. 10 10 |
| Bb [b] | Kk [k] | Tt [t], см.35 |
| Cc см.12 | Ll [l] см.6 | Uu [y] |
| Dd [d] | Mm [m] | Vv [v] |
| Ee см.24-26, 36 (беглое е) | Nn [n] | Ww [v] |
| Ff [f] | Oo [o] | Xx см.11 |
| Gg см.13 | Pp [p] | Yy [i], см.28 |
| Hh не читается | Qq см.17 | Zz [z] |
| Ii [i], см.18 | Rr [r] |
Кроме букв из алфавита, используется еще ряд букв с различными надстрочными и подстрочными значками:
| ç [s] в любой позиции | ï [i], не входит в буквосочетания | œ [œ] |
| é [e] | î [i] | û, ù [y] |
| è, ê [ɛ] | ô [o] | и др. |
Правила чтения
1. Ударение в слове всегда падает на последний слог.
2. На конце слов не читаются: “е, t, d, s, x, z, p, g” (кроме некоторых искл.), а также буквосочетания “es, ts, ds, ps”: rose, nez, climat, trop, heureux, nid, sang; roses, nids, cadets.
3. Не читается окончание глаголов “-ent”: ils parlent.
4. На конце слова не читается “r” после “e” (-er): parler.
Исключения: в некоторых существительных и прилагательных, например: hiver [ivɛ:r], cher [ʃɛ:r], mer [mɛ:r], hier [jɛ:r], fer [fɛ:r], ver [vɛ:r].
5. На конце слова не читается “c” после носовых гласных: banc [bɑ̃].
6. Буква “l” всегда читается мягко.
7. Звонкие согласные всегда произносятся четко и не оглушаются на конце слова (о фонетической ассимиляции во французском языке). Безударные гласные произносятся четко и не редуцируются.
8. Перед согласными звуками [r], [z], [Ʒ], [v], [vr] ударные гласные звуки приобретают долготу: base [ba:z].
9. Двойные согласные буквы читаются как один звук: pomme [pom].
10. Буква “s” между гласными дает звук [ z ]: rose [ro:z].
- В остальных случаях – [ s ]: veste [vɛst].
- Два «s» (ss) всегда читаются как [ s ]: classe [klas].
11. Буква “x” в начале слова между гласными читается как [gz]: exotique [ɛgzotik].
- Не в начале слова буква “x” произносится как [ ks ]: taxi [taksi].

- В количественных числительных произносится как [s]: Six, dix [sis, dis].
- В порядковых числительных произносится как [z]: Sixième, dixième [sizjɛm].

12. Буква “c” читается как [ s ] перед “i, e, y”: cirque [sirk].
- В остальных случаях она дает звук [ k ]: cage [ka:Ʒ].
- “ç” всегда читается как звук [ s ]: garçon [garsɔ̃].
На конце слова буква “c”
- В большинстве случаев произносится как [ k ]: parc [park].
- Не произносится после носовых гласных — banc [bɑ̃] и в некоторых словах (porc [po:r], estomac [ɛstoma], tabac [taba]).
13. Буква “g” читается как [Ʒ] перед “i, e, y”: cage [ka:Ʒ].
- В остальных случаях буква дает звук [ g ]: galop [galo].
- Сочетание “gu ”перед гласным читается как 1 звук [ g ]: guerre [gɛ:r].
- Сочетание “gn” читается как звук [ɲ] (похож на русский [ нь ]): ligne [liɲ].
Исключительные случаи чтения буквосочетания gn.
14. Буква “h” никогда не читается: homme [om], но подразделяется на h немое и h придыхательное.
15. Буквосочетание “ch” дает звук [ʃ] = русское [ш]: chat [ʃa].
16. Буквосочетание “ph” дает звук [ f ]: photo [foto].
17. Буквосочетание “qu” дает 1 звук [ k ]: qui [ki].
18. Буква “i” перед гласной буквой и сочетание “il” после гласной на конце слова читаются как [ j ]: miel [mjɛl], ail [aj].
Буква «i» перед гласной читается как 2 звука [ij] в следующих случаях:
1) i + гласный после двух согласных, из которых второй l или r: ouvrier [uvrije], oublier [ublije];
2) i в глаголах rire, lier: il riait [il rijɛ], il liait [il lijɛ].
19. Буквосочетание “ill” читается как [j] (после гласной) или [ij ] (после согласной): famille [famij].
Исключения: ville, mille, tranquille, Lille и их производные.
20. Буквосочетание “oi” дает звук полугласный [ wа ]: trois [trwа].
21. Буквосочетание “ui” дает полугласный звук [ʮi]: huit [ʮit].
22. Буквосочетание “ou” дает звук [ u ]: cour [ku:r].
Если после буквосочетания “ou” стоит произносимая гласная буква, то читается как [w]: jouer [Ʒwe].
23. Буквосочетания “eau”, “au” дают звук [ o ]: beaucoup [boku], auto [oto].
24. Буквосочетания “eu”, “œu” читаются как [œ] перед произносимым согласным, кроме [z] или как [ø] на конце слова или перед непроизносимым конечным согласным, а также перед [z]: neuf [nœf], pneu [pnø], soeur [sœ:r], sérieuse [serjø:z], voeu [vø].
25. Буква “è” и буква “ê” дают звук [ɛ]: crème [krɛm], tête [tɛt].
Буква “é” читается как [e]: télé [tele].
26. Буква «е» (без значков сверху) читается по-разному в зависимости от позиции в слове:
- как звук [e] в
- 1) окончаниях -er, -ez (причем r и z не произносятся): répéter [repete], répétez [repete];
- 2) односложных служебных словах, оканчивающихся на согласный (чаще всего на -s): les [le], mes [me], tes [te], ses [se], ces [se], des [de], et [e];
- как звук [ɛ]
- 1) в закрытом слоге (заканчивающемся на согласный): perte [pɛrt];
- 2) перед двойными согласными, кроме окончаний наречий -emment, в которых произносится [amɑ̃]: renne [rɛn], pelle [pɛl], но évidemment [evidamɑ̃];
- 3) в окончании -et (t не читается): cadet [kadɛ];
- как звук [ǝ]
- 1) в открытом неударном слоге (заканчивающемся на гласный): regarder [rǝgarde];
- 2) в односложных служебных словах, оканчивающихся на -e: je [Ʒǝ], me [mǝ], te [tǝ], se [sǝ], ce [sǝ], que [kǝ], le [lǝ], de [dǝ]. + см. Правило 36.
 + см. Правило 36.
+ см. Правило 36.27. Буквосочетания “ai” и “ei” читаются как [ɛ]: mais [mɛ], beige [bɛ:Ʒ].
Исключение: окончание -ai в 1 л. ед.ч. будущего времени (futur simple), которое читается как [e] (je lirai [Ʒǝ lire]).
28. Буква “y” между гласными буквами “раскладывается” на 2 “i”: royal (roi – ial = [rwa—jal]).
- Между согласными читается как [i]: stylo [stilo].
29. Буквосочетания “an, am, en, em” дают носовой звук [ɑ̃]: enfant [ɑ̃fɑ̃], ensemble [ɑ̃sɑ̃bl].
30. Буквосочетания “on, оm” дают носовой звук [ɔ̃]: bon [bɔ̃], nom [nɔ̃].
31. Буквосочетания “in, im, ein, aim, ain, yn, ym ” дают носовой звук [ɛ̃]: jardin [Ʒardɛ̃], important [ɛ̃portɑ̃], symphonie [sɛ̃foni], copain [kopɛ̃].
32. Буквосочетания “un, um” дают носовой звук [œ̃]: brun [brœ̃], parfum [parfœ̃].
33. Буквосочетание “oin” читается [ wɛ̃ ]: coin [kwɛ̃].
34. Буквосочетание “ien” читается [ jɛ̃ ]: bien [bjɛ̃].
Подробнее о носовых звуках
35. Буквa “t” даeт звук [ s ] перед “i ” + гласный: national [nasjonal].
Исключение: amitié [amitje], pitié [pitje].
- Но, если перед буквой «t» стоит буква «s», «t» читается как [t]: question [kɛstjɔ̃].
36. Беглое [ǝ] в потоке речи может выпадать из произношения или, наоборот, появиться там, где в изолированном слове не произносится:
Acheter [aʃte], les cheveux [leʃvø].
37. В речевом потоке французские слова теряют свое ударение, объединяясь в группы с общим смысловым значением и общим ударением на последней гласной (ритмические группы).
Чтение внутри ритмической группы требует обязательного соблюдения двух правил: сцепления (enchainement) и связывания (liaison).
а) Сцепление: конечная произносимая согласная одного слова образует с начальной гласной следующего слова один слог: elle aime, la salle est claire.
б) Явление связывания состоит в том, что конечная непроизносимая согласная начинает звучать, связываясь с начальной гласной следующего слова: c’est elle, à neuf heures.
38. Короткие служебные слова (и некоторые другие) теряют конечную гласную e, a, i перед словами, которые начинаются на гласную букву или h немую. Вместо конечной гласной ставится апостроф. Элизия и апостроф.
Правила чтения французского языка — видео
Цвета в английском языке с транскрипцией и переводом
Тему “цвета” на английском языке вы с ребенком можете начинать учить одной из первых. Ведь вам в этом помогут даже обычные бытовые вещи. У каждой свой цвет или оттенок. Предлагаем вам погрузиться в яркую палитру и сделать “цветной” словарик. Он поможет вашему ребенку быстро выучить слова и использовать их, описывая тот или другой предмет.
Ведь вам в этом помогут даже обычные бытовые вещи. У каждой свой цвет или оттенок. Предлагаем вам погрузиться в яркую палитру и сделать “цветной” словарик. Он поможет вашему ребенку быстро выучить слова и использовать их, описывая тот или другой предмет.
Вы можете играть в игру “Назови цвет”, когда готовите что-то вкусненькое из фруктов или овощей, собираете ягоды, рисуете, складываете игрушки или вещи в шкафу.
Приступим к изучению десяти основных цветов, которые используются в английском чаще всего.
Yellow — жёлтый (елоу) [ ˈjeləʊ ]
Red — красный (ред) [ red ]
Green — зелёный (грин) [ ɡriːn ]
Orange — оранжевый (орэндж) [ ˈɒrɪndʒ ]
Blue — голубой, синий (блю) [ bluː ]
Pink — розовый (пинк) [ pɪŋk ]
Brown — коричневый (браун) [ braʊn ]
Рurple — фиолетовый (перпл) [ pɜːpl ]
White — белый (уайт) [ waɪt ]
Black — чёрный (блэк) [ blæk ]
Когда ваш маленький ученик доберется до большой упаковки карандашей, точно возникнут вопросы: “Мама, а это какой цвет? А это, как red, только темнее?”
Чтобы у вас была подстраховка на такой случай, приводим примеры еще цветов-оттенков на английском.
Оттенки цветов в английском языке
gray [ greɪ ] серый (грей)
silver [ ˈsɪlvə ] серебряный (силвер)
beige [ beɪʒ ] бежевый (бейж)
scarlet [ ˈskɑːlɪt ] алый (скарлет)
golden [ ˈgəʊldən ] золотой (голден)
turquoise [ ˈtɜːkwɑːz ] бирюзовый (тюкойз)
emerald [ ˈemərəld ] изумрудный (эмералд)
coral [ ˈkɔrəl ] коралловый (корал)
olive [ ˈɔlɪv ] оливковый (Олив)
lilac [ ˈlaɪlək ] сиреневый (лайлак)
amber [ ˈæmbə ] янтарный (эмбер)
sand [ sænd ] песочный (санд)
vinous [ ˈvaɪnəs ] бордовый (винос)
сhocolate [ ˈʧɔkəlɪt ] шоколадный (чоколэт)
ivory [ ˈaɪvərɪ ] цвет слоновой кости (айвори)
salmon [ ˈsæmən ] оранжево-розовый (салмон)
lavender [ ˈlævɪndə ] бледно-лиловый (лавендер)
plum [ plʌm ] сливовый (плам)
maroon [ məˈruːn ] темно-бордовый (марун)
crimson [ krɪmzn ] малиновый (кримзон)
Если вы хотите придать описанию предмета оттенков, насыщенности или другой окраски, используйте следующее 5 слов.
Light — светлый (лайт) [ laɪt ]
Dark — темный (дак) [ dɑːk ]
Bright — яркий (брайт) [ braɪt ]
Dull — тусклый (дал) [ dʌl ]
Pale — бледный (пэйл) [ peɪl ]
Чтобы закрепить все слова из нашего цветного словаря, предлагаем поиграть в игру «What color?».
Вы прячете предмет, а ребенок пытается угадать, какого он цвета.
– What color is it?
– Is it … ( цвет)?
– Yes, it is. (No, it isn’t) – Да. (Нет)
Когда разберетесь с основными цветами и оттенками, можете рассмотреть с ребенком эту картинку. Она поможет визуально запомнить цвета.
Желаем вдохновения вашему ребенку!
У него все получится! Особенно с вашей поддержкой 🙂
Медицинские слова на английском, которые нужно знать
Сегодня я не буду грузить вас сложными и заумными медицинскими терминами на английском, а лишь познакомлю с основными медицинскими словами на английском, которые нужно знать на случай если вы не дай бог попадете в больницу заграницей.
Выучите данные английские слова, и вы сможете не только понимать, о чем говорят врачи, но и более свободно смотреть медицинские сериалы на английском.
Места
- Hospital – больница
- Emergency Room (ER) – приемный покой
- Intensive Care Unit (ICU) – отделение интенсивной терапии
- Operating Room (OR) – операционная
- Ward – палата
Медицинские аббревиатуры на английском
- CBC – общий анализ крови
- MRI – магнитно-резонансная томография (МРТ)
- EKG = echocardiogram – электрокардиограмма (ЭКГ)
- X-ray – рентген
- B.I.D. = (from Latin «bis in die») – дважды в день (обычно пишут в рецепте о приеме препарата)
Поговорим о фитнесе на английском языке
Общеизвестные слова, связанные с медициной
- Exam – обследование
- Diagnosis – диагноз
- Prescription – рецепт (на лекарство)
- Urine sample – анализ мочи
- Blood sample – анализ крови
- Hypertension – гипертензия, повышенное артериальное давление
- Cast – гипс
- Vein – вена
- Syringe – шприц
- Pain killer / pain reliever – болеутоляющее, обезболивающее
- Numb – онемевший
- Dosage – дозировка, доза
Устойчивые выражения с английскими глаголами PAY и KEEP
Внесем ясность в следующие понятия:
- Injury – это травма, повреждение внешней поверхности тела
- Illness – это временное заболевание
- Disease – это серьезное заболевание, болезнь
А теперь перейдем к словам, соответствующим каждому из этих понятий.
Injury:
- Wound – рана
- Burn – ожог
- Break / bone fracture – перелом
- Heal – заживать, излечивать
6 английских идиом для выражения состояния печали
Illness:
- Sickness – немочь, заболевание
- Cold – боль в горле и насморк, простуда
- Flu – грипп
- Bug = virus – вирус
- Remedy – лекарство, вылечивать
Disease:
- Chronic – хронический
- Benign – доброкачественный, неопасный (опухоль, образование)
- Terminal – смертельный
- Treat – лечить
- Cure – лечение, лекарство, исцеление, лечить
10 названий фобий на английском + фразы для выражения страха
Названия медперсонала по-английски
- Surgeon – хирург
- Anesthesiologist – анестезиолог
- Cardiologist – кардиолог
- Traumatologist – травматолог
- Orthopedist – ортопед
- Gastroenterologist – гастроэнтеролог
- Dermatologist – дерматолог
- Gynecologist – гинеколог
- Urologist – уролог
- Ophthalmologist – окулист, офтальмолог
- Therapist – физиотерапевт
- Nurse – медсестра
- Pediatrician – педиатр
- Physician – врач, медик
- Doctor = MD – доктор, врач
- Family doctor – семейный / лечащий врач /терапевт
Не болейте и учите английский с удовольствием!
До скорых встреч!
accident перевод и транскрипция, произношение, фразы и предложения
[ˈæksɪdənt]
Добавить в закладки Удалить из закладок
существительное
- авария (несчастный случай, катастрофа, случай, случайность, крушение, происшествие)
- техника безопасности
Множ. число: accidents.
число: accidents.
Синонимы: safety.
прилагательное
- несчастный
- аварийный (случайный)
Синонимы: disconsolate, wretch.
Фразы
car accident
автомобильная авария
automobile accident
автомобильная катастрофа
unfortunate accident
несчастный случай
simple accident
простая случайность
terrible accident
жуткое происшествие
numerous accidents
многочисленные инциденты
accident case
несчастный случай
accident conditions
аварийные условия
Предложения
If he had been careful then, the terrible accident would not have happened.
Был бы он тогда осторожнее, и не произошло бы этого ужасного случая.
The news of the accident caused public alarm.
Известие о катастрофе вызвало публичный резонанс.
He wishes the accident hadn’t happened.
Он хотел бы, чтобы этой катастрофы не произошло.
He had an accident at work.
С ним произошел несчастный случай на работе.
This lady witnessed an accident at three o’clock this afternoon.
Эта женщина была свидетельницей происшествия в три часа дня.
There was an accident at the intersection.
На перекрёстке произошла авария.
The scene of the car accident was a horrifying sight.
Сцена автомобильной аварии была ужасным зрелищем.
The cause of the accident is a complete mystery.
Причина происшествия — полная загадка.
He had an accident while working.
С ним произошел несчастный случай на работе.
I had a slight accident while trekking in Nepal.
Со мной случилось небольшое происшествие во время переселения в Непал.
He had an accident and broke his leg.
У него был несчастный случай, и он сломал ногу.
The accident left him permanently paralyzed.
После этого происшествия он оказался парализованным навсегда.
The accident was caused by a fault in the refrigeration system of the appliance.
Авария была вызвана неисправностью в системе охлаждения устройства.
The accident happened at that intersection.
Несчастный случай произошёл на этом перекрёстке.
Did you see the accident with your own eyes?
Ты видел аварию своими глазами?
Even though the accident was six months ago, my neck still hurts.
Несмотря на то, что авария произошла полгода тому назад, моя шея всё ещё болит.
The accident occurred on Friday.
Авария произошла в пятницу.
The accident wasn’t your fault.
Несчастный случай произошел не по твоей вине.
In aftermath of the accident he lost his sight.
После аварии он потерял зрение.
Yesterday, there was a terrible accident on the highway.
Вчера была страшная авария на шоссе.
The accident took place on the evening of last Sunday.
Авария произошла вечером в минувшее воскресенье.
I heard about the accident for the first time yesterday.
Вчера я впервые услышал об аварии.
An awful accident happened yesterday.
Вчера произошёл ужасный несчастный случай.
We waited at the scene of the accident till the police came.
Мы ждали на месте происшествия, пока не подъехала полиция.
The accident shows that he is careless about driving.
Авария показала, что он был невнимателен за рулём.
When did the accident take place?
Где произошел этот несчастный случай?
The accident took place the day before yesterday.
Авария произошла позавчера.
He told me about the accident as if he had seen it with his own eyes.
Он рассказал о происшествии так, будто видел его своими собственными глазами.
He explained how the accident came about.
Он объяснил, как произошел этот несчастный случай.
The accident happened two hours ago.
Авария произошла два часа назад.
определение, произношение, транскрипция, словоформы, примеры
существительное
- происшествие чего-либо (синоним: пример, случай) это был случай неправильного суждения
может пойти дождь, и в этом случае пикник будет быть аннулированным
- фактическое положение вещей
которое не имело места
музыканты оставили свои футляры для инструментов за кулисами
типичным случаем была домохозяйка из пригорода, описанная консультантом по вопросам брака
дела, которые мы изучали, были взяты из двух разных сообществ
Перри Мейсон раскрыл дело о пропавшем наследнике
он четко изложил свое дело
- существительные, местоимения или прилагательные (часто отмеченные флексией), связанные каким-либо образом с другими словами в предложении
- конкретное состояние временное сознание
случай дрожи
 : характер, эксцентричный, тип)
: характер, эксцентричный, тип) психический случай
- обволакивающая структура или покрытие, заключающее в себе орган или часть животного или растения (син.: оболочка)
- корпус или наружное покрытие чего-либо (син. кожух, скорлупа)
часы имеют ореховый корпус
- (печать) сосуд, в котором находится наборщик имеет свой тип, который разделен на отсеки для различных букв, пробелов или цифр
для английского языка наборщик обычно имеет два таких корпуса, верхний регистр содержит заглавные буквы, а нижний регистр содержит строчные буквы
грабитель нес свою добычу в наволочке
 : витрина)
: витрина) глагол
- осматривать, обычно с намерением ограбить Они обложили жильё
Дополнительные примеры
Все знали, что у них ужасное дело друг на друга.
Защита настаивает на своем.
Суд не будет рассматривать это дело.
Адвокат умело аргументировал дело.
Она подготовила хорошее дело для своего клиента.
Они урегулировали дело во внесудебном порядке.
Охотники убили двух оленей и сняли шкуры.
Он искал поле для карьеры.
В районе зафиксировано 16 случаев повреждения автомобилей.
Количество фруктов во фруктовых соках должно составлять 6% для ягод и 10% для других фруктов.
Во многих случаях стандарты улучшились.
Карьера Тома тому пример (= яркий пример того, что вы обсуждаете или объясняете).
Как и другие, он представил письменное объяснение, но в случае Скотта это был 30-страничный печатный буклет.
Изменить традиционные роли мужчин и женщин непросто, но в нашем случае это помогло.
Может случиться так, что схема потребует больше денег.
Словоформы
глагол
я/ты/мы/они: падеж
он/она/оно: падежи
причастие настоящего времени: корпус
прошедшее время: корпус
причастие прошедшего времени: корпус
существительное
единственное число: падеж
множественное число: падеж
Что такое дословная транскрипция? Определение дословной транскрипции
Что такое дословная транскрипция?
Дословная расшифровка записывает каждое слово из аудиофайла в виде текста, точно так же, как эти слова были произнесены изначально. Когда кто-то запрашивает дословную транскрипцию, он ищет расшифровку, которая включает в себя слова-заполнители, фальстарты, грамматические ошибки и другие словесные подсказки, которые обеспечивают полезный контекст и устанавливают сцену записанного сценария.
Когда кто-то запрашивает дословную транскрипцию, он ищет расшифровку, которая включает в себя слова-заполнители, фальстарты, грамматические ошибки и другие словесные подсказки, которые обеспечивают полезный контекст и устанавливают сцену записанного сценария.
Дословная транскрипция включает в себя абсолютно все. Он дословно соответствует аудиофайлу, который загружает клиент.
Заказать 99% точные стенограммыВ чем разница между дословной и не дословной транскрипцией?
Существует два основных типа транскрипции: дословная и не дословная.Verbatim — это когда транскрипционист печатает все слова, которые он слышит, включая определенные неречевые звуки, междометия или признаки активного слушания, слова-паразиты, фальстарты, самоисправления и заикания. Этот тип стенограммы требует массу дополнительного времени и внимания к деталям, и по этой причине стоит немного больше.
Недословная транскрипция, с другой стороны, очищается, чтобы удалить слова-заполнители, запинки и все, что отвлекает от основного смысла того, что говорится. Этот тип стенограммы является наиболее распространенным и должен быть слегка отредактирован транскрипционистом для удобства чтения.
Этот тип стенограммы является наиболее распространенным и должен быть слегка отредактирован транскрипционистом для удобства чтения.
Вот пример двух реальных предложений, расшифрованных не дословно и дословно и сравненных рядом:
Пример 1
Не дословно: Я думаю, мы должны пойти в кино сегодня вечером из-за скидки.
Дословно: Итак, эм, я думаю… Я думаю, нам стоит пойти сегодня вечером в м-м-кино из-за скидки (смеется).
Пример 2
Не дословно: Я звонил ей вчера, и она спала.Наверное, она просто очень устала.
Дословно: Я типа, знаешь, звонил ей, типа, вчера и, гм, типа, она вроде как спала. Наверное, она просто очень устала.
Когда удобна дословная транскрипция?
Стенограммы Verbatim предоставляют полезный контекст, который не может предложить очищенная стенограмма. Поскольку настоящие стенограммы включают неречевые звуки, такие как «мм-хмм (утвердительно)» или «мм-мм (отрицательно)», они особенно полезны при проведении фокус-группы, цитировании источника или запросе юридической транскрипции.
В большинстве случаев эти слова не нужны, но во многих случаях они служат полезными словесными подсказками, например, в аудиофайлах полицейских допросов, где такие словесные паузы могут дать представление о поведении человека.
Дословные транскрипции следует использовать, когда:
- Прямое цитирование источника
- Проведение фокус-группы
- Перевод интервью из научного исследования
- Подготовка юридических документов
- Подача юридического заявления
Какую службу расшифровки следует использовать?
Можно подумать, что стенограмма — это, ну, стенограмма — письменная запись записанного аудио.Но это немного упрощает. В зависимости от типа расшифровки, которую заказывает клиент, могут быть некоторые различия в формате и уровне детализации, предоставляемые специалистом по расшифровке. Временные метки, мгновенный первый черновик, срочная доставка и дословная транскрипция — все это среди дополнений, которые может запросить клиент. Стенограммы поддерживают множество различных проектов, и в зависимости от сложности этого проекта вам нужно убедиться, что вы заказываете правильные надстройки. Узнайте больше о наших услугах транскрипции и определите, какое предложение подходит именно вам.
Стенограммы поддерживают множество различных проектов, и в зависимости от сложности этого проекта вам нужно убедиться, что вы заказываете правильные надстройки. Узнайте больше о наших услугах транскрипции и определите, какое предложение подходит именно вам.
Участвовать в проекте >> Получение
НачалосьИндексирование и расшифровка ваших интервьюИндексирование и расшифровка — чрезвычайно полезные способы определения основных темы в интервью и примерный момент, когда они происходят в записи. Это снижает износ ленты за счет значительно уменьшая количество перемоток вперед и назад до «сканирования» контент; кроме того, оба позволяют исследователю быстро определить затрагивает ли запись конкретную проблему или нет. В указателе перечислены основные темы, обсуждаемые в ходе интервью, и приблизительная
места в записи они встречаются; стенограмма представляет собой дословный документ
что позволяет «читать» интервью. Хотя стенограммы чрезвычайно полезны и всегда приветствуются интервью, они занимают очень много времени и поэтому не обязательный. Если ресурсы не позволяют транскрибировать записи, пожалуйста потратьте время на создание указателя каждого интервью, которое вы отправляете. Как я могу проиндексировать свои записи?Внимательно прослушайте запись и запишите основные моменты в ней. порядке, в котором они обсуждаются, обращая особое внимание на минуты и секунды или показания счетчика на самописце (минуты и вторые примечания обычно более надежны для разных регистраторов). В целом,
исследователи и слушатели больше заинтересованы в ответах
чем вопросы (поскольку ответы обычно
более разнообразны, чем вопросы, и могут относиться к смежным темам
прямо не упоминается в
вопрос).Хорошее эмпирическое правило заключается в том, что чем более подробным и описательным
индексации, тем лучше исследователи могут получить доступ к
содержание ленты.
Что такое стенограмма? Стенограмма или транскрипция представляет собой дословную письменную копию
записанного интервью. Если позволяют время и ресурсы, ветераны
History Project настоятельно рекомендует вам или вашей организации
создавать стенограммы ваших интервью. Зачем делать стенограммы?Стенограммы предлагают несколько важных преимуществ, таких как:
Какая связь между стенограммой и записью? Стенограммы когда-то рассматривались некоторыми устными историками как замена
за оригинальные аудио- и видеозаписи.Это не было редкостью
лет назад для больших программ устной истории, чтобы избавиться от или повторно использовать
аудиозаписи после того, как были сделаны стенограммы записей. Совсем недавно архивисты и устные историки начали сохранять
как оригинальная запись, так и сопровождающая ее расшифровка, как
дополнительная документация того же события. Как бы тщательно
и точные расшифровки могут быть, они никогда не смогут зафиксировать
все детали аудиозаписи, такие как тон голоса
и эмоции, выраженные в устной речи, они также не могут передать
мимика и манеры, которые появляются в видео
запись.Однако они являются отличными инструментами доступа. Они предоставляют
легкодоступный эталонный заменитель записей,
и они не требуют специального оборудования для воспроизведения или кабины для прослушивания. Сколько времени нужно, чтобы сделать расшифровку?Создание стенограммы занимает много времени, но чрезвычайно ценно. Программное обеспечение для обработки текстов и другие компьютерные программы сделали задача легче, чем раньше, но устные историки и фольклористы по оценкам, для расшифровки требуется от шести до двенадцати часов один час интервью плюс дополнительное время, если вы отредактируете расшифровка потом. Насколько тщательной должна быть стенограмма? Цель состоит в том, чтобы создать стенограмму, которая будет одновременно точной и
понятно читателю. Он не должен включать каждое высказывание
или описать каждый фоновый шум, но он должен воспроизводиться как
как можно ближе к словам говорящего. Он также должен быть последовательным
в стилистическом подходе и уровне детализации во всем. Существуют ли альтернативы созданию полной стенограммы?Да.Вместо того, чтобы создавать формальную транскрипцию, вы можете рассмотреть сделать более короткое резюме или аннотацию, в которой излагаются основные лица и основные темы, обсуждаемые на ленте в порядке в котором они упоминаются. Вы можете использовать аудио- и видеозапись Журнал предоставляется в этом комплекте (с формами проекта). Другая альтернатива заключается в создании алфавитного списка имен и предметов, упомянутых в записи с соответствующими показаниями счетчика на Лента. Какие советы по созданию и редактированию расшифровок?
Должен ли интервьюер просматривать и редактировать стенограмму?Степень редактирования стенограмм, включая количество изменений, сделанных интервьюером и интервьюируемым лицом (т. е. рассказчик), являются предметом серьезных споров среди устных историки. Проект истории ветеранов рекомендует, когда возможно, интервьюер должен отредактировать стенограммы, чтобы:
Должен ли рассказчик просматривать и редактировать стенограмму? Проект истории ветеранов предлагает вам
здравый смысл при принятии решения о том, является ли участие рассказчика в
процесс обзора повысит полезность и исследовательскую ценность
транскриптов, не отталкивая тех, кто уже пожертвовал
свое время и воспоминания проекту. Иногда рассказчикам предоставляется возможность просмотреть стенограммы. Обычно они могут заполнить любые пробелы и обнаружить их легче, чем кто-либо другой. иначе ошибки в расшифровке. Также читаем стенограмму пробуждает дополнительные воспоминания, которые они хотели бы включить, которые могут быть вставлены в скобки в документе. Недостатки заключаются в том, что рассказчики могут обнаружить, просматривая стенограммы обременительны и могут возмущаться, когда их спрашивают.Они также могут склонны «очищать» свои сленговые выражения и разговорную речь до такой степени, что они жертвуют тоном и ритмом интервью и сделать менее убедительным то, что они сказали. Как насчет профессиональных услуг транскрипции? Если у вас есть финансовые ресурсы, вы можете нанять профессионала
служба расшифровки, желательно с опытом расшифровки
записи устной истории. Если вам нужно расшифровать группу интервью, лучше
нанять одну и ту же услугу, чтобы сделать все из них, чтобы обеспечить согласованность
в общем подходе и в написании личных и географических
имена, аббревиатуры и технические термины.Предоставить транскрибатор
со списком этих имен и терминов вместе с хорошо помеченными
копии кассет. Не посылайте расшифровщику свою мастер-ленту. Какие есть хорошие источники дополнительной информации?Для получения дополнительной информации о расшифровке и индексировании устных исторические интервью, пожалуйста, обратитесь к следующим книгам и веб-сайтам. места.
Принять участие в проекте >> Получение Началось |

 Например, письмо «описывает опасения по поводу того, что не выживет».
и молитвы, которые он записал в свой дневник», полезнее, чем «страхи в бою».
примеры некоторых отличных журналов Veterans History Project
получил от участников, см. образец
Журналы аудио- и видеозаписи перечислены на нашей странице форм.
Например, письмо «описывает опасения по поводу того, что не выживет».
и молитвы, которые он записал в свой дневник», полезнее, чем «страхи в бою».
примеры некоторых отличных журналов Veterans History Project
получил от участников, см. образец
Журналы аудио- и видеозаписи перечислены на нашей странице форм.
 Этот
решение продиктовано опасениями по поводу ухудшения звучания кассет.
качество, затраты на хранение и консервацию лент неизвестных
долговечность, потенциальное устаревание воспроизводящего оборудования,
и убеждение, что большинство исследователей предпочитало читать стенограмму
а не слушать запись.
Этот
решение продиктовано опасениями по поводу ухудшения звучания кассет.
качество, затраты на хранение и консервацию лент неизвестных
долговечность, потенциальное устаревание воспроизводящего оборудования,
и убеждение, что большинство исследователей предпочитало читать стенограмму
а не слушать запись.


 Включите такие выражения, как «умхум» или «ха-ха».
когда используется для обозначения «да» или «нет» в ответ на конкретные вопросы.
Включите такие выражения, как «умхум» или «ха-ха».
когда используется для обозначения «да» или «нет» в ответ на конкретные вопросы.

 Эти компании взимают плату в диапазоне
100-125 долларов за час записи, но убедитесь, что стоимость покрывает изготовление
исправления к первому варианту и включает доставку окончательного
выписка как в бумажном, так и в электронном виде. Иногда это
можно получить финансирование от государственных советов по гуманитарным наукам для расшифровки
сборники устных рассказов после того, как они были записаны и
собраны в коллекцию.
Эти компании взимают плату в диапазоне
100-125 долларов за час записи, но убедитесь, что стоимость покрывает изготовление
исправления к первому варианту и включает доставку окончательного
выписка как в бумажном, так и в электронном виде. Иногда это
можно получить финансирование от государственных советов по гуманитарным наукам для расшифровки
сборники устных рассказов после того, как они были записаны и
собраны в коллекцию.
 Методы устной истории
и Процедуры . Вашингтон, округ Колумбия: Центр военной истории,
Армия США, 1992 г. Доступно на сайте http://www.army.mil/cmh-pg/books/oral.htm
Методы устной истории
и Процедуры . Вашингтон, округ Колумбия: Центр военной истории,
Армия США, 1992 г. Доступно на сайте http://www.army.mil/cmh-pg/books/oral.htm Вашингтон, округ Колумбия: Музей,
1998. Доступно онлайн в формате PDF по адресу http://www.ushmm.org/archives/oralhist.pdf
Вашингтон, округ Колумбия: Музей,
1998. Доступно онлайн в формате PDF по адресу http://www.ushmm.org/archives/oralhist.pdfЧАСТЬ 108.
 Формат судебных выписок и ставки их оплаты
Формат судебных выписок и ставки их оплаты 108.1 Общее
108.2 Оплата стенограммы
108.3 Стандартные спецификации стенограммы
108.4 Письменное соглашение
108.5 Приложение: Форма протокола судебного репортера
Раздел 108.1 Общие положения.
(a) Если иное не предусмотрено в настоящем документе, эта Часть регулирует формат каждой страницы протокола судебного заседания, который должен быть предоставлен судебным секретарем, который является сотрудником Единой судебной системы или независимым подрядчиком, ставка оплата, на которую он или она имеет право, и требования к соглашению между судебным секретарем и запрашивающей стороной.
(b) Для целей настоящей Части термин «стенограмма» означает расшифровку стенографических протоколов, сделанных одним или несколькими судебными репортерами, представляющих собой полный протокол всех судебных разбирательств по делу.
Историческая справка
сек. подан 18 сентября 1984 г. ; амд. подан 5 января 1998 г., эф. 1 февраля 1998 г. Изменено (а).
; амд. подан 5 января 1998 г., эф. 1 февраля 1998 г. Изменено (а).
Раздел 108.2 Оплата стенограммы.
(a) Если иное не предусмотрено законом, настоящий раздел применяется в тех случаях, когда Единая судебная система или лица или стороны, отличные от Единой судебной системы, несут ответственность за оплату судебному секретарю за предоставленный протокол или его часть.
(б)
(1) За предоставление протокола судебного заседания или его части судебный секретарь получает вознаграждение по следующим ставкам:
(i) Если Единая судебная система по закону несет ответственность за выплату судебному секретарю — 2,50 доллара США за страницу за оригинал плюс 1 доллар США за страницу за каждую копию, за исключением: доставки в соответствии с требованиями статьи 460.70 Уголовно-процессуального закона. —3,50 доллара США за страницу за оригинал плюс бесплатная первая копия; и за регулярную доставку судье в соответствии со статьей 299 Закона о судопроизводстве — бесплатно.
(ii) За исключением случаев, предусмотренных в подпункте (i) настоящего параграфа, если оплата судебному секретарю должна поступать из государственных средств: для обычной доставки — от 2,50 до 3,15 долларов за страницу за оригинал плюс 1 доллар за страницу. за каждую копию; для ускоренной доставки — от 3,15 долл. США за страницу до 4,25 долл. США за страницу за оригинал плюс 1,10 долл. США за страницу за каждую копию; а для ежедневной доставки — от 3,75 долл. США за страницу до 5,25 долл. США за страницу за оригинал плюс 1,25 долл. США за страницу за каждую копию.
(iii) Во всех случаях, не предусмотренных подпунктами (i) и (ii) настоящего параграфа: для регулярной доставки — от 3,30 долл. США за страницу до 4,30 долл. США за страницу за оригинал плюс 1,00 долл. США за страницу за каждую копию; для ускоренной доставки — от 4,40 долл. США за страницу до 5,40 долл. США за страницу за оригинал плюс 1,10 долл. США за страницу за каждую копию; и для ежедневной доставки — от 5,50 долларов США за страницу до 6,50 долларов США за страницу за оригинал плюс 1,25 доллара США за страницу за каждую копию.
(2) Для целей данного подраздела и подраздела (e) данного раздела:
(i) «обычная доставка» означает подготовку и доставку стенограммы в обычных обстоятельствах после завершения разбирательства, включая любые сроки подготовки и доставки, которые превышают сроки ускоренной или ежедневной доставки;
(ii) «ускоренная доставка» означает составление и доставку стенограммы в течение пяти рабочих дней за каждый день или неполный день разбирательства;
(iii) «ежедневная доставка» означает составление и доставку стенограммы утром следующего рабочего дня;
(iv) копия выписки или ее часть должны быть заказаны в течение 30 дней с даты заказа оригинала выписки или ее части;
(v) сроки доставки измеряются с момента получения судебным секретарем приказа о стенограмме или ее части;
(vi), если заказана доставка стенограммы, и в этом разделе указан диапазон ставок для категории такой доставки (т.e., регулярная доставка, ускоренная доставка или ежедневная доставка), судебный секретарь получает оплату по такой ставке, в таком диапазоне, который он или она и заказчик могут согласовать, исходя из региональной и рыночной стоимости стенограмм и составление стенограммы, сложность предмета судебного разбирательства и объем стенограммы судебного секретаря. Если судебный секретарь и заказчик не могут договориться о ставке, судебный секретарь не обязан предъявлять и доставлять стенограмму, за исключением случаев, когда была заказана регулярная доставка, и в этом случае ставка платежа за нее должна быть самой низкой ставкой в пределах диапазон тарифов, указанный в данном разделе, для регулярной доставки; и
Если судебный секретарь и заказчик не могут договориться о ставке, судебный секретарь не обязан предъявлять и доставлять стенограмму, за исключением случаев, когда была заказана регулярная доставка, и в этом случае ставка платежа за нее должна быть самой низкой ставкой в пределах диапазон тарифов, указанный в данном разделе, для регулярной доставки; и
(vii) судебный секретарь может, по согласованию с заказчиком, представить стенограмму в виде файла (в формате ASCII или другом согласованном формате) на компьютерной дискете.В таком случае такой файл должен быть обозначен как оригинал или копия по согласованию между судебным секретарем и заказчиком, и судебный секретарь имеет право на оплату по ставке, применимой в иных случаях за страницу, установленной в настоящем документе, за каждую страницу такой стенограммы. включены в такой файл, если стенограмма не сжата, и в этом случае каждый квадрант такой стенограммы (т. е. одна из четырех страниц стенограммы, сжатых электронным способом в одну страницу) должен представлять собой отдельную страницу, за которую судебный секретарь имеет право на оплату в ином случае. применяется в расчете на одну страницу, установленную в соответствии с настоящим документом.
применяется в расчете на одну страницу, установленную в соответствии с настоящим документом.
(c)
(1) Несмотря на положения подпункта (b) настоящего раздела, ни один судебный секретарь не имеет права на получение оплаты за стенограмму или ее часть по ставке, указанной в подпункте (b), за исключением случаев, когда суд отчет или его или ее руководитель получает санкционированный запрос на это на или после даты вступления в силу такой ставки. Для целей настоящего подраздела санкционированный запрос означает запрос, который (i) сделан в письменной форме апелляционным судом или судьей или сотрудником внесудебного суда, действующим по указанию судьи, (ii) датирован и (iii) процитирован установленный законом орган, на основании которого оно совершено.
(2) Положения пункта (1) настоящего подраздела не применяются, если подготовка стенограммы или какой-либо ее части не запрошена апелляционным судом, судьей или несудебным служащим, действующим по указанию судьи, но запрашивается стороной судебного разбирательства или иным лицом, имеющим право по закону на получение его копии, либо требуется в силу закона. В таком случае судебный секретарь, подготовивший стенограмму или ее часть, имеет право на получение оплаты за нее по ставке, указанной в подпункте (b) настоящего раздела, действующей на дату возникновения потребности в ее подготовке.
В таком случае судебный секретарь, подготовивший стенограмму или ее часть, имеет право на получение оплаты за нее по ставке, указанной в подпункте (b) настоящего раздела, действующей на дату возникновения потребности в ее подготовке.
(d) Для целей настоящего раздела судебный секретарь не имеет права на получение оплаты за страницу стенограммы, если только эта страница не соответствует стандартным спецификациям стенограммы, изложенным в разделе 108.3 настоящей Части, и содержит не менее 13 строк материала. . Если судебный секретарь должен предоставить только часть стенограммы, слово стенограмма, используемое в этом подразделе, означает эту часть.
(e) Невзирая на положения подпункта (b) настоящего раздела, судебный секретарь, который расшифровал стенографический протокол судебного разбирательства до даты вступления в силу этого пункта и который в день вступления в силу или после такой даты вступления в силу получает приказ о расшифровка таких протоколов оплачивается по следующему тарифу, если оплата судебному секретарю производится из государственных средств:
(1) Если Единая судебная система по закону несет ответственность за выплату судебному секретарю по применимой ставке, указанной в подпункте (b)(1)(i) настоящего раздела, за вычетом 10 процентов от нее.
(2) Во всех случаях, когда пункт (1) настоящего подраздела не применяется:
Для обычной доставки — от 2,25 до 2,75 долларов за страницу за оригинал плюс 1 доллар за страницу за каждую копию.
Для ускоренной доставки — от 2,75 долл. США за страницу до 3,85 долл. США за страницу за оригинал плюс 1,10 долл. США за страницу за каждую копию.
Ежедневная доставка: от 3,40 долл. США за страницу до 4,75 долл. США за страницу за оригинал плюс 1,25 долл. США за страницу за каждую копию.
Историческая справка
сек.подан 18 сентября 1984 г.; амдс. подано: 25 марта 1987 г.; 5 января 1998 г.; 5 июня 2000 г., эфф. 1 июня 2000 г. Изменено (b), добавлено (e).
Раздел 108.3 Стандартные спецификации стенограммы.
(a) Стенограммы должны быть на бумаге размером 8 1/2 x 11 дюймов.
(b) Каждая страница стенограммы должна соответствовать следующим спецификациям:
(1) Каждая страница, кроме перечисленных в подпунктах (i) — (iii) настоящего параграфа, должна иметь 25 пронумерованных строк материала, исключая строку, посвященную заголовку и номеру страницы:
(i) страница, на которую включен заголовок, или, если транскрипция заголовка требует более одной страницы, последняя из таких страниц;
(ii) страница, на которую включен указатель, или, если транскрипция указателя требует более одной страницы, последняя из таких страниц; и
(iii) за каждый день, когда судебный секретарь составляет протокол судебного заседания по делу, последняя страница его расшифровки или, если более одного судебного секретаря составляют протокол судебного заседания по делу, последняя такая страница каждая часть стенограммы, представленная каждым судебным секретарем.
(2) На дюйм должно приходиться 10 символов.
(3) Левое поле должно иметь отступ на 1 3/4 дюйма от левого края страницы и должно быть отмечено двумя линиями, отстоящими друг от друга на 1/16 дюйма, идущими от верха до низа страницы. каждая страница. Правое поле должно иметь отступ 3/8 дюйма от правого края и должно быть отмечено одной линией, идущей сверху вниз на каждой странице. Каждая строка расшифрованного материала должна доходить как можно ближе к правому полю.
(4) Размер горизонтального блока для письма должен составлять 6 5/16 дюймов. Вертикальный блок для письма должен быть 9 дюймов.
(c) Часть стенограммы свидетельских показаний и беседы должна быть в следующем формате:
(1) В части свидетельских показаний первая строка каждого вопроса и каждого ответа должна иметь отступ в пять пробелов от левого поля и должна начинаться с «Q» или «A», в зависимости от обстоятельств. Текст каждой такой строки должен начинаться с 10 пробелов от левого поля. Каждая последующая строка вопроса или ответа должна начинаться с левого поля.
Каждая последующая строка вопроса или ответа должна начинаться с левого поля.
(2) [Для применения этого подразделения см. примечание ниже. См. также подраздел (2) ниже.] В части, посвященной разговору, первая строка замечаний каждого выступающего должна иметь отступ в 15 пробелов от левого поля и должна начинаться с обозначения имени выступающего, за которым следует двоеточие. , два пробела и начало его или ее примечаний. Каждая последующая строка таких примечаний имеет отступ 5 знаков от левого поля, за исключением того, что первая строка каждого последующего абзаца таких примечаний имеет отступ 15 знаков от левого поля.
(2) [Для применения этого подразделения см. примечание ниже. См. также подраздел (2) ниже.] В части, посвященной разговору, первая строка замечаний каждого выступающего должна иметь отступ в 15 пробелов от левого поля и должна начинаться с обозначения имени выступающего, за которым следует двоеточие. , два пробела и начало его или ее примечаний. Каждая последующая строка таких примечаний имеет отступ 10 знаков от левого поля, за исключением того, что первая строка каждого последующего абзаца таких примечаний имеет отступ 15 знаков от левого поля.
(d) На первой странице каждой стенограммы должен быть заголовок, содержащий только следующее:
(1) суд, округ или город места проведения и часть, в которой проходило разбирательство;
(2) название дела;
(3) номер обвинительного акта(ов) или номер(а) дела, обвинение и характер разбирательства;
(4) адрес здания суда;
(5) дата (даты) судебного разбирательства;
(6) председательствующий;
(7) было ли разбирательство перед присяжными;
(8) выступления адвокатов сторон; и
(9) имя каждого судебного секретаря и каждого судебного переводчика, если таковые имеются.
Расшифровка протоколов каждого последующего дня должна включать сокращенное название, излагающее только вопрос, указанный в пунктах (1)–(7) настоящего подраздела. Такое сокращенное название должно также включать заявление о том, что внешний вид адвоката является таким же, как указано выше, за исключением того, что в случае изменения внешнего вида такие изменения должны быть изложены.
(e) Каждая стенограмма должна включать один указатель; за исключением случаев, когда более одного судебного секретаря составляют протокол судебного разбирательства по делу, может существовать отдельный указатель для каждой части протокола судебного разбирательства, представленного каждым таким судебным секретарем.В индексе указывается следующее:
(1) сторона, вызвавшая свидетеля, имя каждого свидетеля, давшего показания в ходе судебного разбирательства, записанного в нем, вместе с страницей или страницами, на которых даются его или ее показания, и были ли такие показания даны в рамках прямого допроса, перекрестный допрос или иная форма допроса; и
(2) сторона, предложившая каждое доказательство, описание каждого из представленных доказательств, представленных каждой стороной, вместе со страницей или страницами, на которых оно было предложено для опознания и представлено в качестве доказательства.
(f) Образцы страниц стенограммы, отражающие требуемые здесь спецификации, приведены в Приложении к этой Части. 1
1
[«Настоящий приказ вступает в силу в тот же день, когда глава законов 2000 г. (L.2000, c. 279, eff. 16 августа 2000 г.), упомянутая выше, становится законом и, если поправки не предусматривают иное , применяются ко всем стенограммам, заказанным на эту дату или после этой даты, при условии, однако, что положения Части 108, действовавшие непосредственно перед датой вступления в силу настоящего приказа, остаются в полной силе и действуют в отношении внесудебных должностных лиц и сотрудников коллективного переговорная единица, не указанная в разделе первом такой главы.»]
1. Такие образцы здесь не приводятся. См. 22 NYCRR.
Раздел 108.4 Письменное соглашение.
(a) [Для применения этого подраздела см. примечание ниже. См. также подраздел (а) ниже.] Каждый судебный секретарь, который представляет стенограмму судебного разбирательства, должен в момент запроса стенограммы заключить письменное соглашение о ее подготовке с лицом или стороной, запрашивающей стенограмму. Договор заключается по форме, указанной в приложении к настоящей части.
Договор заключается по форме, указанной в приложении к настоящей части.
(a) [Для применения этого подраздела см. примечание ниже. См. также подраздел (а) выше.] Каждый судебный секретарь, который представляет стенограмму судебного разбирательства, должен в момент запроса стенограммы заключить письменное соглашение о ее подготовке с лицом или стороной, запрашивающей стенограмму. Соглашение составляется по форме, установленной главным администратором судов, и в нем указывается ставка за страницу, предполагаемое количество страниц и дата, к которой должна быть подготовлена стенограмма.
(b) Если иное не предусмотрено в меморандуме о взаимопонимании с Единой судебной системой, каждый судебный секретарь, который заключает такое письменное соглашение, должен подать копию этого соглашения в офис соответствующего административного судьи или его или ее назначенному лицу не позднее чем через семь дней после заключения договора.
(c) [Для применения этого подраздела см. примечание ниже. См. также подраздел (с) ниже.] Этот раздел не применяется, если оплата судебному секретарю за стенограмму должна поступать из государственных средств.
примечание ниже. См. также подраздел (с) ниже.] Этот раздел не применяется, если оплата судебному секретарю за стенограмму должна поступать из государственных средств.
(c) [Для применения этого подраздела см. примечание ниже. См. также подраздел (c) выше.] Этот подраздел не применяется, если единая судебная система несет ответственность за оплату судебного секретаря за стенограмму.
[«Настоящий приказ вступает в силу в тот же день, когда глава законов 2000 г. (L.2000, c. 279, eff. 16 августа 2000 г.), упомянутая выше, становится законом и, если поправки не предусматривают иное , применяются ко всем стенограммам, заказанным на эту дату или после этой даты, при условии, однако, что положения Части 108, действовавшие непосредственно перед датой вступления в силу настоящего приказа, остаются в полной силе и действуют в отношении внесудебных должностных лиц и сотрудников коллективного переговорная единица, не указанная в разделе первом такой главы.»]
Изменено (b) 18 ноября 2008 г.
Раздел 108.5 Приложение: Форма протокола судебного протокола.
ПРИЛОЖЕНИЕ
ФОРМА ПРОТОКОЛА СОГЛАШЕНИЯ С СУДЕБНЫМ РЕПОРТЕРОМ
(согласно статье 108.4(а) Правил Главного администратора
судов)
Пожалуйста, печатайте или пишите разборчиво
1. _____ Суд, округ _____,
Деталь № _____
Имя судьи/судьи ____________________________
2.Наименование дела ________________________________
3. Номер судебного дела/файла/индекса _____
4. Дата запроса протокола _____
5. Тип разбирательства (отметьте один или несколько):
_____Расстановка
_____Приложение
_____Слух
_____Просьба
_____Пробная
_____Предложение
_____Другое (указать)
6. В соответствии с разделом 108 Правил Главного администратора судов расценки за страницу протоколов судебных заседаний в судах штата Нью-Йорк следующие:
Обычная доставка: 3 доллара. 30 – 4,30 доллара (оригинал)
30 – 4,30 доллара (оригинал)
1,00 долл. США (каждая копия)
Ускоренная доставка: 4,40–5,40 долл. США (оригинал)
1,10 долл. США (каждая копия)
Ежедневная доставка: 5,50–6,50 долл. США (оригинал)
1,25 долл. США (каждая копия)
7. Плата за страницу:
Обычный _____ Ускоренный _____ Ежедневный _____Другой _____
Количество заказанных экземпляров _____
8. Расчетное количество страниц: _____
9. Предполагаемая дата поставки _____
10. Согласовано:_________________
_____________________ __________________
Судебный секретарь Адвокат/сторона Дата соглашения
(подпись)
Имя судебного секретаря__________
Имя поверенного/стороны _____________
Адрес__________________
Фирма/Адрес________________________________________________
______________________________________________
Номер телефона ______________
Номер телефона ______________
Номер факса ____________________
Номер факса ____________________
Копия этого соглашения должна быть подана судебным секретарем своему руководителю, назначенному административным судьей, в течение 7 календарных дней после даты соглашения.
ИНСТРУКЦИЯ ПО ЗАПОЛНЕНИЮ ФОРМЫ ПРОТОКОЛА СУДЕБНОГО ДОКЛАДЧИКА
Письменное соглашение должно быть оформлено независимо от того, размещен ли первоначальный заказ по телефону, почте, факсу, электронной почте или лично. Если приказ включает расшифровку протокола по одному и тому же делу, но от более чем одного судебного секретаря, каждый секретарь должен заполнить отдельную форму приказа .
1. Введите конкретное название суда, например. , Верховный суд, окружной суд и т. д.; округ, в котором находится суд; название или номер Части, в которой слушался вопрос; и имя судьи, рассматривавшего дело.
2. Введите название дела.
3. Введите номер дела, дела или индекса, или любой другой идентификационный номер, присвоенный судом этому делу. Если номер не назначен, введите «Нет».
4. Введите дату или даты протокола судебного разбирательства или его части, подлежащей расшифровке.
5. Укажите один или несколько видов протоколов.
6. Данный раздел носит информационный характер и не требует ответа.
7. Введите размер взимаемой постраничной ставки и проверьте запрошенное время доставки.
8. Судебный секретарь должен оценить количество страниц, за которые будет взиматься плата. Фактическое количество страниц не может быть известно, пока стенограмма не будет завершена.
9. Введите предполагаемую дату доставки. Ожидается, что судебные репортеры будут придерживаться предполагаемой даты доставки, указанной в соглашении.Обычно судебные репортеры обязаны расшифровывать запросы о стенограммах в порядке их поступления. Однако, если законодательные или иные положения, изложенные в Руководстве судебного докладчика, требующие немедленного предоставления стенограмм, влияют на дату доставки ранее заказанных стенограмм, судебный секретарь приложит все усилия, чтобы уведомить лицо, заказывающее стенограмму. Уведомление должно быть сделано своевременно до предполагаемой даты доставки, информируя запрашивающую сторону о причине задержки и договариваясь о новой дате доставки.
10. Судебный секретарь и адвокат или сторона, заказывающая стенограмму, должны подписать соглашение и указать свои адреса, номера телефонов и факсов. Соглашение должно быть датировано.
Определения:
. «Ежедневно» означает произведено и доставлено утром следующего рабочего дня UCS.
. «Ускоренный» означает изготовление и доставку в течение пяти рабочих дней UCS за каждый день или неполный день.
. «Обычный» означает изготовление и доставку в обычных условиях после завершения разбирательства, включая любые сроки изготовления и доставки, превышающие сроки для ежедневной или ускоренной копии.
. Сроки доставки измеряются с момента, когда репортер получает заказ на стенограмму или ее часть.
. Чтобы получить право на «копирование», расшифровка или ее часть должны быть заказаны в течение 30 дней с даты, когда расшифровка или ее часть были ранее заказаны.
Если у вас есть какие-либо вопросы относительно этой формы или ее содержания, пожалуйста, обращайтесь к репортеру Надзорного суда или главному секретарю, в зависимости от ситуации.
Часто задаваемые вопросы по Amazon Transcribe — Amazon Web Services (AWS)
В: Как разработчики получат доступ к Transcribe?
Самый простой способ начать работу с Amazon Transcribe — отправить задание на расшифровку аудиофайла с помощью консоли.Вы также можете вызвать сервис непосредственно из интерфейса командной строки AWS или использовать один из поддерживаемых SDK по вашему выбору для интеграции с вашими приложениями. В любом случае вы можете начать использовать Amazon Transcribe для автоматического создания расшифровок аудиофайлов, написав всего несколько строк кода.
В. Поддерживает ли Amazon Transcribe расшифровку в реальном времени?
Да. Amazon Transcribe позволяет пользователям открывать двунаправленный поток через HTTP2. Пользователи могут отправлять аудиопоток в сервис, получая взамен текстовый поток в режиме реального времени.
В: Какую кодировку поддерживает транскрипция в реальном времени?
Потоковая транскрипция в настоящее время поддерживает 16-битное кодирование Linear PCM.
Вопрос. Какие языки поддерживает Amazon Transcribe?
Информацию о языковой поддержке см. на этой странице документации.
Вопрос. С какими устройствами работает Amazon Transcribe?
Amazon Transcribe по большей части не зависит от устройства.Как правило, Amazon Transcribe работает с любым устройством со встроенным микрофоном, таким как телефоны, ПК, планшеты и устройства IoT (например, автомобильные аудиосистемы). Amazon Transcribe API сможет определять качество аудиопотока, поступающего на устройство (8 кГц против 16 кГц), и соответствующим образом выбирать акустические модели для преобразования речи в текст. Кроме того, разработчики могут вызывать Transcribe API через свои приложения для доступа к возможностям преобразования речи в текст.
Вопрос. Существуют ли ограничения на размер аудиоконтента, который может обрабатывать Amazon Transcribe?
Вызовы службы Amazon Transcribe ограничены 4 часами (или 2 ГБ) на вызов API для нашего пакетного сервиса.Потоковая служба может поддерживать открытые соединения продолжительностью до 4 часов.
Вопрос. Какие языки программирования поддерживает Amazon Transcribe?
Пакетный сервис Amazon Transcribe поддерживает .NET, Go, Java, Javascript, PHP, Python и Ruby.
Сервис Amazon Transcribe в режиме реального времени поддерживает Java SDK, Ruby SDK и C++ SDK. Ожидается дополнительная поддержка SDK. Для получения более подробной информации посетите страницу Ресурсы.
В: Слова из моего пользовательского словаря не распознаются! Что я могу сделать?
Выходные данные распознавания речи зависят от ряда факторов в дополнение к элементам пользовательского словаря, поэтому нельзя гарантировать, что термин, включенный в пользовательский словарь, будет правильно распознан.
Однако наиболее частой причиной является неправильное произношение пользовательского слова. Если вы не указали произношение для своего пользовательского слова, попробуйте создать его. Если вы уже предоставили его, перепроверьте его правильность или при необходимости включите другие варианты произношения. Это можно сделать, создав несколько записей в пользовательском файле словаря, которые различаются полем произношения.
В: Почему в выходных данных отображается слишком много пользовательских слов?
пользовательских словарей оптимизированы для небольшого списка целевых слов; большие словари могут привести к чрезмерному созданию нестандартных слов, особенно если они содержат слова, которые произносятся сходным образом.Если у вас большой список, попробуйте сократить его до редких слов и слов, которые действительно должны встречаться в ваших аудиофайлах. Если у вас есть большой словарный запас, охватывающий несколько вариантов использования, разделите его на отдельные списки для разных вариантов использования. Короткие слова, похожие по звучанию на многие другие слова, могут привести к перегенерации (в выводе появляется слишком много пользовательских слов). Предпочтительно объединять эти слова с соседними словами и перечислять их как фразы, разделенные дефисом. Например, пользовательское слово «А.Д.” может быть включен как часть такой фразы, как «АЦП-преобразователь».
Короткие слова, похожие по звучанию на многие другие слова, могут привести к перегенерации (в выводе появляется слишком много пользовательских слов). Предпочтительно объединять эти слова с соседними словами и перечислять их как фразы, разделенные дефисом. Например, пользовательское слово «А.Д.” может быть включен как часть такой фразы, как «АЦП-преобразователь».
В: Есть два способа указания произношения: поля IPA или SoundsLike в пользовательской таблице словаря. Какой лучше?
IPA позволяет добиться более точного произношения. Вы должны указать произношение IPA, если вы можете создать IPA (например, из лексикона, в котором есть произношение IPA, или с помощью онлайн-конвертера).
Q: Я хотел бы использовать IPA, но я не лингвист.Есть ли онлайн-инструмент, который я могу использовать?
Некоторые стандартные словари, такие как Оксфордский словарь английского языка или Кембриджский словарь (включая их онлайн-версии), содержат произношение в IPA. Существуют также онлайн-конвертеры (например, easypronunciation.com или tophonetics.com для английского языка) — однако обратите внимание, что в большинстве случаев эти инструменты основаны на базовых словарях и могут не генерировать правильный IPA для некоторых слов, таких как имена собственные. Amazon Transcribe не поддерживает какие-либо сторонние инструменты.
Существуют также онлайн-конвертеры (например, easypronunciation.com или tophonetics.com для английского языка) — однако обратите внимание, что в большинстве случаев эти инструменты основаны на базовых словарях и могут не генерировать правильный IPA для некоторых слов, таких как имена собственные. Amazon Transcribe не поддерживает какие-либо сторонние инструменты.
В: Нужно ли использовать разные стандарты IPA, относящиеся к разным акцентам одного и того же языка? (например, американский английский по сравнению с британским английским)?
Вы должны использовать стандарт IPA, который подходит для аудиофайлов, которые вы будете обрабатывать — например, если вы планируете обрабатывать аудио от носителей британского английского языка, используйте стандарт британского английского произношения. Набор разрешенных символов IPA может различаться для разных языков и диалектов, поддерживаемых Amazon Transcribe; пожалуйста, убедитесь, что ваше произношение содержит только разрешенные символы. Подробности о наборах символов IPA можно найти в документации: https://docs.aws.amazon.com/transcribe/latest/dg/how-vocabulary.html#charsets
Подробности о наборах символов IPA можно найти в документации: https://docs.aws.amazon.com/transcribe/latest/dg/how-vocabulary.html#charsets
В: Как я могу предоставить произношение, используя поле SoundsLike в пользовательской таблице словаря?
Вы можете разбить слово или фразу на более мелкие части и указать произношение для каждой части, используя стандартную орфографию языка, чтобы имитировать звучание слова. Например, на английском языке вы можете предоставить подсказки по произношению для фразы Los-Angeles следующим образом: loss-ann-gel-es .Подсказка для слова Etienne будет выглядеть так: eh-tee-en . Вы отделяете каждую часть подсказки дефисом (-). Вы можете использовать любой из разрешенных символов для языка ввода.
В: Как работают два разных способа предоставления акронимов (с точками и без точек, но с произношением)?
Если вы используете аббревиатуру, содержащую точки, произношение правописания будет сгенерировано внутри. Если вы не используете точки, укажите произношение в поле произношения.Для некоторых аббревиатур не очевидно, имеют ли они правописание или словесное произношение (например, NATO часто произносится как «n eɪ t oʊ» ( nay-toh ), а не как «ɛn eɪ ti oʊ» (NATO )).
Если вы не используете точки, укажите произношение в поле произношения.Для некоторых аббревиатур не очевидно, имеют ли они правописание или словесное произношение (например, NATO часто произносится как «n eɪ t oʊ» ( nay-toh ), а не как «ɛn eɪ ti oʊ» (NATO )).
В: Где я могу найти примеры использования пользовательского произношения?
Образцы входных форматов и примеры можно найти в документации: https://docs.aws.amazon.com/transcribe/latest/dg/how-vocabulary.html.
В: Что произойдет, если я использую неправильный IPA? Если я не уверен, лучше ли мне не вводить IPA?
Система будет использовать предоставленное вами произношение; это должно повысить вероятность правильного распознавания слова, если произношение правильное и соответствует тому, что было сказано.Если вы не уверены, что создаете правильный IPA, запустите сравнение, обработав аудиофайлы со словарем, содержащим ваше произношение IPA, и со словарем, который содержит только слова (и, при желании, формы отображения). Если вы не предоставите какое-либо произношение, служба будет использовать приближение, которое может или не может работать лучше, чем ваш ввод.
Если вы не предоставите какое-либо произношение, служба будет использовать приближение, которое может или не может работать лучше, чем ваш ввод.
Вопрос. Можно ли при использовании форм DisplayAs отображать наборы символов, не связанные с транскрибируемым исходным языком? (т.е.г. вывести «улица» как «街道») .
Да. Хотя фразы могут использовать только ограниченный набор символов для определенного языка, символы UTF-8, кроме \t (TAB), разрешены в столбце DisplayAs.
В: Доступно ли автоматическое редактирование контента или редактирование личной информации (PII) как с пакетным, так и с потоковым API для Transcribe?
Да, Amazon Transcribe поддерживает автоматическое редактирование контента или редактирование персональных данных как для пакетных, так и для потоковых API.
В. Какие языки поддерживаются для автоматического редактирования контента/идентификации и редактирования персональных данных?
См. документацию Amazon Transcribe для получения информации о языковой доступности автоматического редактирования содержимого/редактирования PII.
документацию Amazon Transcribe для получения информации о языковой доступности автоматического редактирования содержимого/редактирования PII.
В: Автоматическое редактирование контента также удаляет конфиденциальную личную информацию из исходного аудио?
Нет, эта функция не удаляет конфиденциальную личную информацию из исходного аудио.Однако вы можете самостоятельно отредактировать личную информацию из исходного аудио, используя временные метки начала и окончания, указанные в отредактированных расшифровках для каждого экземпляра идентифицированного высказывания PII.
В: Могу ли я использовать автоматическое редактирование содержимого для удаления личной информации из существующих текстовых расшифровок?
Нет, автоматическое редактирование контента работает только со звуком в качестве входа.
В: Что еще нужно знать перед использованием автоматического редактирования контента?
Автоматическое редактирование содержимого предназначено для выявления и удаления информации, позволяющей установить личность (PII), но из-за предиктивного характера машинного обучения оно может не идентифицировать и удалить все экземпляры PII в стенограмме, созданной службой. Вы должны проверить все выходные данные, предоставленные автоматическим редактированием контента, чтобы убедиться, что они соответствуют вашим потребностям.
Вы должны проверить все выходные данные, предоставленные автоматическим редактированием контента, чтобы убедиться, что они соответствуют вашим потребностям.
В: Существуют ли различия между автоматическим редактированием содержимого для потоковой передачи и пакетного API?
Да, есть две дополнительные возможности, поддерживаемые автоматическим редактированием контента для потокового API, которые не поддерживаются пакетным API. Вы можете решить только идентифицировать PII, а не редактировать, используя редактирование контента с потоковым API.Также у вас есть возможность идентифицировать или редактировать определенные типы PII с помощью потокового API. Например, вы можете отредактировать только номер социального страхования и информацию о кредитной карте и сохранить другие персональные данные, такие как имена и адреса электронной почты.
Вопрос. В каких регионах AWS доступно автоматическое редактирование контента или редактирование PII?
Информацию о доступности автоматического редактирования контента и редактирования PII для пакетных и потоковых API в регионах AWS см. в документации по Transcribe.
в документации по Transcribe.
В: Какие API поддерживают автоматическую идентификацию языка?
Автоматическая идентификация языка в настоящее время поддерживается для пакетных и потоковых API.
Вопрос. Какие языки Amazon Transcribe определяет автоматически?
Amazon Transcribe может идентифицировать любой из языков, поддерживаемых пакетными и потоковыми API.
Вопрос. Идентифицирует ли Amazon Transcribe несколько языков в одном аудиофайле?
Amazon Transcribe определяет только доминирующий язык в аудиофайле.
В: Можно ли ограничить список языков для автоматического определения языка?
Да, вы можете указать список языков, которые могут присутствовать в вашей медиатеке. Когда вы предоставляете список языков, указанный язык будет выбран из этого списка. Если языки не указаны, система обработает аудиофайл со всеми языками, поддерживаемыми Amazon Transcribe, и выберет наиболее вероятный. Точность идентификации языка лучше, когда предоставляется список выбора языков.
Точность идентификации языка лучше, когда предоставляется список выбора языков.
Основы преобразования речи в текст | Документация по преобразованию речи в текст в облаке | Облако Google
Обзор
Этот документ представляет собой руководство по основам использования преобразования речи в текст. В этом концептуальном руководстве рассматриваются типы запросов, которые вы можете сделать к преобразованию речи в текст, как составить эти запросы и как обрабатывать их ответы.Мы рекомендуем всем пользователям Speech-to-Text прочтите это руководство и одно из связанных руководств, прежде чем погрузиться в сам API.
Примечание: Все пользователи могут отправлять до 60 минут аудио в Speech-to-Text для бесплатно каждый месяц . Если вы превысите эту сумму, понесены расходы. См. страницу с ценами для деталей.Попробуйте сами
Если вы новичок в Google Cloud, создайте учетную запись, чтобы оценить, как
Преобразование речи в текст работает в реальном мире
сценарии. Новые клиенты также получают бесплатные кредиты в размере 300 долларов США для запуска, тестирования и
развертывание рабочих нагрузок.
Новые клиенты также получают бесплатные кредиты в размере 300 долларов США для запуска, тестирования и
развертывание рабочих нагрузок.
Речевые запросы
Speech-to-Text имеет три основных метода распознавания речи.Эти перечисленные ниже:
Синхронное распознавание (REST и gRPC) отправляет аудиоданные в API преобразования речи в текст, выполняет распознавание этих данных и возвращает результаты после всех звуковых обработан.
Запросы синхронного распознавания ограничены звуком
данные длительностью 1 минута или менее.Асинхронное распознавание (REST и gRPC) отправляет аудиоданные в API преобразования речи в текст и инициирует длительную операцию .С помощью этой операции вы можете периодически опрашивать результаты распознавания. Используйте асинхронные запросы для аудиоданные любой продолжительности до 480 минут.
Потоковое распознавание (только gRPC) выполняет распознавание аудиоданных предоставляется в течение Двунаправленный поток gRPC. Потоковые запросы предназначены для целей распознавания в реальном времени, таких как захват живого звука с микрофона. Потоковое распознавание обеспечивает промежуточные результаты во время захвата звука, позволяющие отображать результат, например, пока пользователь все еще говорит.
 Запросы синхронного распознавания ограничены звуком
данные длительностью 1 минута или менее.
Запросы синхронного распознавания ограничены звуком
данные длительностью 1 минута или менее. Запросы содержат параметры конфигурации, а также аудиоданные. Следующее
разделы описывают эти типы запросов на признание, ответы на них
генерировать и как обрабатывать эти ответы более подробно.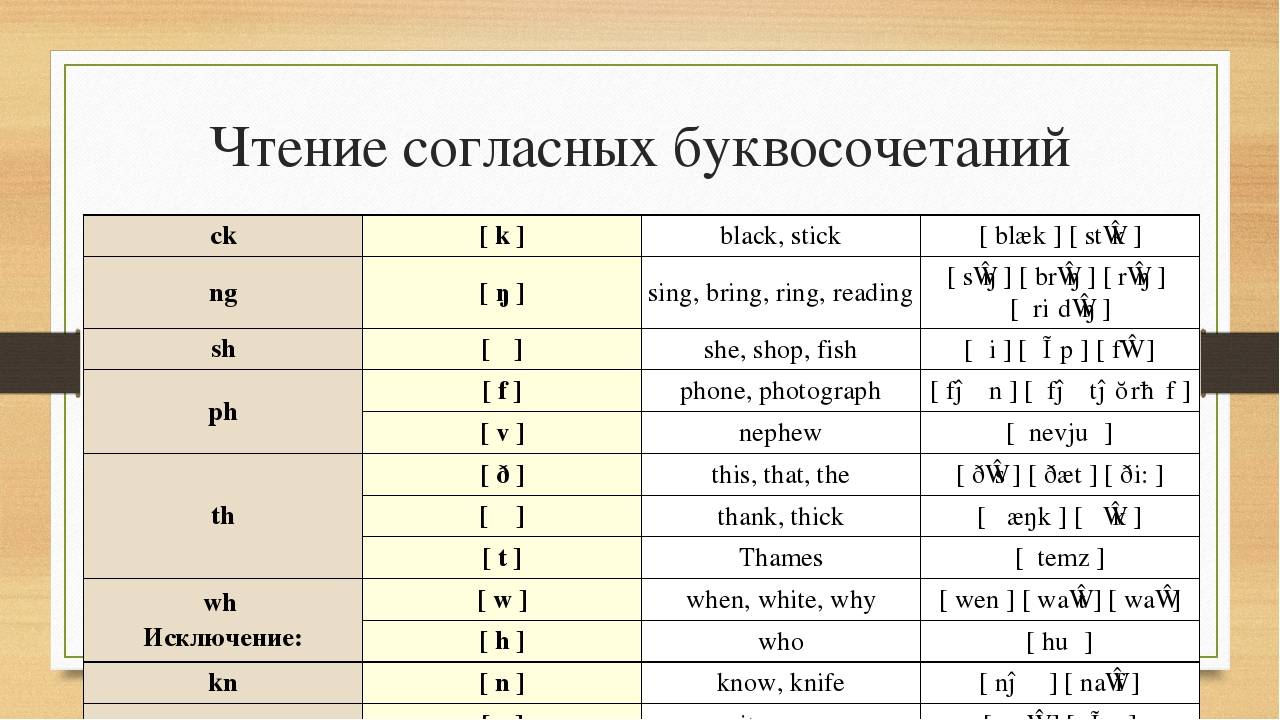
Распознавание API преобразования речи в текст
Запрос на синхронное распознавание Speech-to-Text API — самый простой способ выполнение распознавания речевых аудиоданных. Преобразование речи в текст может обрабатывать до 1 минута речевых аудиоданных, отправленных в синхронном запросе.После преобразования речи в текст обрабатывает и распознает все аудио, возвращает ответ.
Синхронный запрос блокируется, что означает, что преобразование речи в текст должно вернуть ответ перед обработкой следующего запроса. Преобразование речи в текст обычно обрабатывает звук быстрее, чем в реальном времени, обрабатывая 30 секунд звука в среднем за 15 секунд. В случае плохого качества звука ваше признание запрос может занять значительно больше времени.
Преобразование речи в текст имеет методы REST и gRPC для вызова
Синхронные и асинхронные запросы Speech-to-Text API.В этой статье демонстрируется
REST API, потому что так проще показать и объяснить основы использования API. Однако базовая структура запроса REST или gRPC очень похожа.
Запросы на потоковое распознавание
поддерживается gRPC.
Однако базовая структура запроса REST или gRPC очень похожа.
Запросы на потоковое распознавание
поддерживается gRPC.
Запросы на синхронное распознавание речи
Синхронный запрос Speech-to-Text API состоит из конфигурации распознавания речи, и звуковые данные. Пример запроса показан ниже:
{
"конфигурация": {
"кодирование": "LINEAR16",
"sampleRateHertz": 16000,
"languageCode": "en-US",
},
"аудио": {
"uri": "gs:// имя-корзины / путь_к_аудио_файлу "
}
}
Все запросы на синхронное распознавание Speech-to-Text API должны включать распознавание речи. config поле (типа
Конфигурация распознавания).А RecognitionConfig содержит следующие подполя:
-
encoding— (обязательно) указывает схему кодирования поставляемого аудио (типаAudioEncoding). Если у вас есть выбор в кодеке, предпочитайте
кодирование без потерь, такое как FLACилиLINEAR16для лучшей производительности. (Дополнительную информацию см. в разделе Кодирование аудио.) Поле кодировкиFLACиWAV, где кодировка включена в заголовок файла. -
sampleRateHertz— (обязательно) указывает частоту дискретизации (в герцах) поставляемый звук. (Для получения дополнительной информации о частотах дискретизации см. Примерные цены ниже.) ПолеsampleRateHertzявляется необязательным для файловFLACиWAV, где частота дискретизации включена в заголовок файла. -
languageCode— (обязательно) содержит язык + регион/локаль для использования распознавание речи поставляемого аудио. Код языка должен быть
Идентификатор BCP-47.Обратите внимание, что языковые коды обычно
состоят из тегов основного языка и подтегов дополнительного региона для обозначения
диалекты (например, «en» для английского и «US» для Соединенных Штатов в
приведенный выше пример.) (Список поддерживаемых языков см.
Поддерживаемые языки.) -
maxAlternatives— (необязательно, по умолчанию1) указывает количество альтернативные транскрипции предоставить в ответ. По умолчанию API преобразования речи в текст обеспечивает одну первичную транскрипцию.Если вы хотите оценить различные альтернативы, установитеmaxAlternativesна более высокое значение. Обратите внимание, что Преобразование речи в текст будет возвращать альтернативы только в том случае, если распознаватель определит альтернативы должны быть достаточного качества; в общем альтернативы больше подходят для запросов в реальном времени, требующих обратной связи с пользователем (для например, голосовые команды) и поэтому больше подходят для стриминга запросы на признание. -
profanityFilter— (необязательно) указывает, следует ли отфильтровывать ненормативную лексику. слова или фразы.Отфильтрованные слова будут содержать первую букву и звездочки для остальных символов (например, f***). Ненормативная лексика фильтр работает по отдельным словам, он не обнаруживает оскорбительные или оскорбительные речь, представляющая собой фразу или сочетание слов. -
speechContext— (необязательно) содержит дополнительную контекстную информацию для обработки этого звука. Контекст содержит следующее подполе:-
фраз— содержит список слов и фраз, дающих подсказки к задаче распознавания речи.Для получения дополнительной информации см. информация о контекст речи.
-
 Если у вас есть выбор в кодеке, предпочитайте
кодирование без потерь, такое как
Если у вас есть выбор в кодеке, предпочитайте
кодирование без потерь, такое как  Код языка должен быть
Идентификатор BCP-47.Обратите внимание, что языковые коды обычно
состоят из тегов основного языка и подтегов дополнительного региона для обозначения
диалекты (например, «en» для английского и «US» для Соединенных Штатов в
приведенный выше пример.) (Список поддерживаемых языков см.
Поддерживаемые языки.)
Код языка должен быть
Идентификатор BCP-47.Обратите внимание, что языковые коды обычно
состоят из тегов основного языка и подтегов дополнительного региона для обозначения
диалекты (например, «en» для английского и «US» для Соединенных Штатов в
приведенный выше пример.) (Список поддерживаемых языков см.
Поддерживаемые языки.)
Звук подается в преобразование речи в текст через параметр audio типа
Распознавание аудио. То
Поле audio содержит либо из следующих подполей:
-
контентсодержит звук для оценки, встроенный в запрос. Дополнительные сведения см. в разделе «Встраивание аудиоконтента» ниже.
Продолжительность звука, передаваемого непосредственно в этом поле, ограничена 1 минутой. -
uriсодержит URI, указывающий на аудиоконтент. Файл не должен быть сжатый (например, gzip). В настоящее время это Поле должно содержать URI Google Cloud Storage (в форматеgs:// имя_корзины / путь_к_аудио_файлу). Видеть Передача ссылки на аудио по указанному ниже URI.)
 Дополнительные сведения см. в разделе «Встраивание аудиоконтента» ниже.
Продолжительность звука, передаваемого непосредственно в этом поле, ограничена 1 минутой.
Дополнительные сведения см. в разделе «Встраивание аудиоконтента» ниже.
Продолжительность звука, передаваемого непосредственно в этом поле, ограничена 1 минутой.Дополнительные сведения об этих параметрах запроса и ответа приведены ниже.
Частота дискретизации
Вы указываете частоту дискретизации вашего аудио в поле sampleRateHertz конфигурации запроса, и он должен соответствовать частоте дискретизации связанного аудио
контент или поток.Поддерживаются частоты дискретизации от 8000 Гц до 48000 Гц.
в Преобразовании речи в текст. Вы можете указать частоту дискретизации для
Вы можете указать частоту дискретизации для FLAC или WAV в заголовке файла вместо использования поля sampleRateHertz . Файл FLAC должен содержать частоту дискретизации в заголовке FLAC , чтобы быть
переданный в API преобразования речи в текст.
Если у вас есть выбор при кодировании исходного материала, запишите звук с помощью частота дискретизации 16000 Гц.Значения ниже этого могут ухудшить распознавание речи. точность, а более высокие уровни не оказывают заметного влияния на распознавание речи. качество.
Однако, если ваши аудиоданные уже были записаны в существующем семпле
частоту, отличную от 16 000 Гц, не передискретизируйте звук до 16 000 Гц. Самое наследие
телефонный звук, например, использует частоту дискретизации 8000 Гц, что может дать меньше
точные результаты. Если вы должны использовать такое аудио, предоставьте аудио для речи.
API с собственной частотой дискретизации.
Если вы должны использовать такое аудио, предоставьте аудио для речи.
API с собственной частотой дискретизации.
Языки
Механизм распознавания речи в текст поддерживает различные языки и
диалекты.Вы указываете язык (и национальный или региональный диалект) вашего
аудио в поле languageCode конфигурации запроса, используя
Идентификатор BCP-47.
Полный список поддерживаемых языков для каждой функции доступен на странице языковой поддержки.
Смещение времени (метки времени)
Преобразование речи в текст может включать значения смещения времени (метки времени) для начала и конец каждого произнесенного слова, которое распознается в предоставленном аудио. Время значение смещения представляет количество времени, прошедшее с начала звука с шагом 100 мс.
Временные смещения особенно полезны для анализа более длинных аудиофайлов, в которых вы
может потребоваться поиск определенного слова в распознанном тексте и
найти его (искать) в оригинальном аудио. Смещение времени поддерживается для всех
наши методы распознавания:
Смещение времени поддерживается для всех
наши методы распознавания: распознает , потоковое распознавание и долгосрочное распознавание .
Значения смещения времени включаются только для первого варианта, указанного в ответ узнавания.
Чтобы включить временные смещения в результаты вашего запроса, установите Параметр enableWordTimeOffs устанавливается равным true в конфигурации вашего запроса.За
примеры использования REST API или клиентских библиотек см.
Использование временных смещений (временных меток).
Например, вы можете включить параметр enableWordTimeOffsets в
запросить конфигурацию, как показано здесь:
{
"конфигурация": {
"languageCode": "en-US",
"enableWordTimeOffsets": правда
},
"аудио": {
"uri":"gs://gcs-test-data/gettysburg. flac"
}
}
 flac"
}
}
flac"
}
}
Результат, возвращаемый API преобразования речи в текст, будет содержать смещение времени значения для каждого распознанного слова, как показано ниже:
{
"имя": "6212202767953098955",
"метаданные": {
"@тип": "тип.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeMetadata",
"прогрессПроцент": 100,
"startTime": "2017-07-24T10:21:22.013650Z",
"lastUpdateTime": "2017-07-24T10:21:45.278630Z"
},
"сделано": верно,
"отклик": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeResponse",
"Результаты": [
{
"альтернативы": [
{
"транскрипт": "Четыре балла и двадцать...(и т.д.)...",
"уверенность": 0,97186122,
"слова": [
{
"Время начала": "1.300с",
"endTime": "1.400 с",
"слово": "Четыре"
},
{
"startTime": "1.400 с",
"endTime": "1. 600 с",
"слово": "счет"
},
{
"startTime": "1.600 с",
"endTime": "1.600 с",
"слово": "и"
},
{
"startTime": "1.600 с",
"endTime": "1.900 с",
"слово": "двадцать"
},
...
]
}
]
},
{
"альтернативы": [
{
"стенограмма": "за очки и много... (и т. д.)...",
"уверенность": 0,67,
}
]
}
]
}
}
 600 с",
"слово": "счет"
},
{
"startTime": "1.600 с",
"endTime": "1.600 с",
"слово": "и"
},
{
"startTime": "1.600 с",
"endTime": "1.900 с",
"слово": "двадцать"
},
...
]
}
]
},
{
"альтернативы": [
{
"стенограмма": "за очки и много... (и т. д.)...",
"уверенность": 0,
600 с",
"слово": "счет"
},
{
"startTime": "1.600 с",
"endTime": "1.600 с",
"слово": "и"
},
{
"startTime": "1.600 с",
"endTime": "1.900 с",
"слово": "двадцать"
},
...
]
}
]
},
{
"альтернативы": [
{
"стенограмма": "за очки и много... (и т. д.)...",
"уверенность": 0,Выбор модели
Преобразование речи в текст может использовать один из нескольких методов машинного обучения. моделей для расшифровки вашего аудиофайла. Google обучил их модели распознавания речи для определенных типов аудио и источников.
Когда вы отправляете запрос на расшифровку аудио
Speech-to-Text, вы можете улучшить результаты, которые вы получаете
путем указания источника исходного звука. Это позволяет
Speech-to-Text API для обработки ваших аудиофайлов с помощью
модель машинного обучения, обученная распознавать речевой звук из этого
конкретный тип источника.
Это позволяет
Speech-to-Text API для обработки ваших аудиофайлов с помощью
модель машинного обучения, обученная распознавать речевой звук из этого
конкретный тип источника.
Чтобы указать модель для распознавания речи, включите поле модели .
в объекте RecognitionConfig для вашего
запрос, указав модель, которую вы хотите использовать.
Преобразование речи в текст может использовать следующие типы машин обучающие модели для расшифровки ваших аудиофайлов.
Примечание: См. страницу поддерживаемых языков, чтобы узнать, какие модели доступны для вашего языка.| Тип | Константа перечисления | Описание |
|---|---|---|
| Видео | видео | Используйте эту модель для расшифровки звука из видеоклипов или других источников
(например, подкасты) с несколькими динамиками. Примечание: Это модель премиум-класса, которая стоит больше стандартной ставки. |
| Телефон | phone_call | Используйте эту модель для расшифровки аудио из телефонного звонка. Обычно звук телефона записывается с частотой дискретизации 8000 Гц. Примечание: Усовершенствованная модель телефона является премиальной. модель, которая стоит дороже стандартной цены. |
| ASR: команда и поиск | команда_и_поиск | Используйте эту модель для расшифровки коротких аудиоклипов. |
| ASR: по умолчанию | по умолчанию | Используйте эту модель, если ваш звук не подходит ни к одной из других моделей. описано в этой таблице.Например, вы можете использовать это для длинной формы аудиозаписи, в которых присутствует только один динамик. Модель по умолчанию будет производить транскрипцию для любого типа аудио, включая аудио, такие как видеоклипы, которые имеют отдельную модель специально приспособлены к нему. Однако распознавание звука видеоклипа с использованием стандартного модель хотела бы давать результаты более низкого качества, чем при использовании модели видео. В идеале звук должен быть качественным, записанным с частотой 16 000 Гц или выше. частота выборки. |
| Медицинский диктант | медицинский_диктант | Используйте эту модель для расшифровки заметок, продиктованных медицинским работником. |
| Медицинская беседа | медицинский_разговор | Используйте эту модель, чтобы расшифровать разговор между медицинским профессионал и пациент. |
 Эта модель также часто
лучший выбор для аудио, записанного с высоким качеством
микрофон или имеет много фонового шума. Для лучших результатов,
обеспечить звук, записанный с частотой дискретизации 16 000 Гц или выше.
Эта модель также часто
лучший выбор для аудио, записанного с высоким качеством
микрофон или имеет много фонового шума. Для лучших результатов,
обеспечить звук, записанный с частотой дискретизации 16 000 Гц или выше. Немного
примеры включают голосовые команды или голосовой поиск.
Немного
примеры включают голосовые команды или голосовой поиск.
Встроенное звуковое содержимое
Встроенное аудио включается в запрос распознавания речи при передаче параметр содержимого в поле аудио запроса .Для встроенного звука
предоставляется как контент в запросе gRPC, этот звук должен быть совместим для
Прото3
сериализации и предоставляется в виде двоичных данных. Для встроенного звука, предоставляемого как
контент в запросе REST, этот звук должен быть совместим с JSON
сериализации и сначала закодировать в Base64. Видеть
Base64 Encoding Your Audio для получения дополнительной информации.)
При построении запроса с использованием
клиентская библиотека Google Cloud,
обычно вы будете записывать эти двоичные (или закодированные в base-64) данные
непосредственно в поле содержимого .
Передать аудио, на которое ссылается URI
Как правило, вы передаете параметр uri в запросе речи.
Поле audio , указывающее на аудиофайл (в двоичном формате, а не в base64)
находится в Google Cloud Storage следующего вида:
gs:// имя-корзины / путь_к_аудио_файлу
Например, следующая часть речевого запроса ссылается на образец аудио файл, используемый в Quickstart:
...
"аудио": {
"uri":"gs://cloud-samples-tests/speech/brooklyn.flac"
}
...
У вас должны быть соответствующие права доступа для чтения файлов Google Cloud Storage, таких как как одно из следующего:
- Общедоступно (например, наши образцы аудиофайлов)
- Доступно для чтения вашей служебной учетной записи, если используется авторизация служебной учетной записи.
- Доступно для чтения учетной записи пользователя, если для учетной записи пользователя используется трехсторонний протокол OAuth. авторизация.

Дополнительную информацию об управлении доступом к Google Cloud Storage можно найти по адресу Создание и управление списками контроля доступа в документации Google Cloud Storage.
Ответы API преобразования речи в текст
Как указывалось ранее, синхронный ответ Speech-to-Text API может занять некоторое время. для возврата результатов, пропорциональных длине предоставленного аудио. Один раз обработано, API вернет ответ, как показано ниже:
{
"Результаты": [
{
"альтернативы": [
{
"уверенность": 0,98267895,
"стенограмма": "сколько лет Бруклинскому мосту"
}
]
}
]
}
Эти поля поясняются ниже:
-
resultsсодержит список результатов (типаSpeechRecognitionResult) где каждый результат соответствует сегменту аудио (сегменты аудио разделены паузами). Каждый результат будет состоять из одного или нескольких следующих полей:-
альтернативысодержит список возможных транскрипций типаАльтернативы распознавания речи. Наличие более одной альтернативы появляется зависит как от того, запрашивали ли вы более одной альтернативы (путем установкиmaxAlternativesна значение больше1) и от того, Speech-to-Text производил альтернативы достаточно высокого качества. Каждый альтернатива будет состоять из следующих полей:
-
 Каждый результат будет состоять из одного или нескольких следующих полей:
Каждый результат будет состоять из одного или нескольких следующих полей: Если не удалось распознать речь из предоставленного аудиосигнала, то
возвращенный список результатов не будет содержать элементов.Нераспознанная речь обычно является результатом очень плохого качества звука,
или из кода языка, кодировки или значений частоты дискретизации, которые не совпадают
прилагаемый звук.
Компоненты этого ответа объясняются в следующих разделах.
Каждый синхронный ответ Speech-to-Text API возвращает список результатов,
а не один результат, содержащий все распознанные аудио. Список
распознанное аудио (в пределах элементов расшифровки ) появится в
смежный порядок.
Выберите альтернативы
Каждый результат в ответе об успешном синхронном распознавании может содержать
одна или несколько альтернатив (если значение maxAlternatives для запроса
больше, чем 1 ). Если функция преобразования речи в текст определяет, что альтернатива
имеет достаточно
значение достоверности, то эта альтернатива включается в
ответ. Первая альтернатива в ответе всегда лучшая
(скорее всего) альтернатива.
Настройка maxAlternatives на более высокое значение, чем 1 не подразумевает и не гарантирует
что будет возвращено несколько альтернатив. В общем, более одного
альтернатива больше подходит для предоставления пользователям возможностей в реальном времени, получающих
результаты через запрос на потоковое распознавание.
В общем, более одного
альтернатива больше подходит для предоставления пользователям возможностей в реальном времени, получающих
результаты через запрос на потоковое распознавание.
Обработка транскрипций
Каждая альтернатива, указанная в ответе, будет содержать расшифровку содержащий распознанный текст. При наличии последовательных альтернатив,
вы должны объединить эти транскрипции вместе.
Следующий код Python перебирает список результатов и объединяет транскрипции вместе.Обратите внимание, что мы берем первую альтернативу (нулевую) в все случаи.
ответ = service_request.execute()
распознанный_текст = 'Транскрибированный текст: \n'
для i в диапазоне (len (ответ ['результаты'])):
распознанный_текст += ответ['результаты'][i]['альтернативы'][0]['стенограмма']
Значения достоверности
Значение достоверности является оценкой от 0,0 до 1,0. Это рассчитано
путем агрегирования значений «вероятности», присвоенных каждому слову в
аудио. Более высокое число указывает на предполагаемую большую вероятность того, что
отдельные слова были распознаны правильно.Обычно это поле
предоставляется только для верхней гипотезы и только для результатов, где
Это рассчитано
путем агрегирования значений «вероятности», присвоенных каждому слову в
аудио. Более высокое число указывает на предполагаемую большую вероятность того, что
отдельные слова были распознаны правильно.Обычно это поле
предоставляется только для верхней гипотезы и только для результатов, где is_final=истина . Например, вы можете использовать значение достоверности .
решить, показывать ли
альтернативные результаты
пользователю или запросить подтверждение у пользователя.
Однако имейте в виду, что модель определяет «лучший» результат на основе
на большем количестве сигналов, чем только оценка достоверности (например, контекст предложения).
Из-за этого иногда бывают случаи, когда лучший результат не
имеют наивысший показатель достоверности.Если вы не запрашивали несколько альтернатив
результаты, единственный возвращенный «лучший» результат может иметь более низкое значение достоверности
чем предполагалось. Это может произойти, например, в тех случаях, когда редкие слова
использовался. Редко используемому слову можно присвоить низкое значение «вероятности».
даже если он распознан правильно. Если модель определяет редкое слово как
наиболее вероятный вариант, основанный на контексте, этот результат возвращается даже наверху
если значение
Это может произойти, например, в тех случаях, когда редкие слова
использовался. Редко используемому слову можно присвоить низкое значение «вероятности».
даже если он распознан правильно. Если модель определяет редкое слово как
наиболее вероятный вариант, основанный на контексте, этот результат возвращается даже наверху
если значение достоверности результата ниже, чем у альтернативных вариантов.
достоверности в качестве обязательного поля, поскольку это не так.
гарантированно будет точным или даже установленным в любом из результатов.Асинхронные запросы и ответы
Асинхронный запрос API преобразования речи в текст к методу LongRunningRecognize
по форме идентичен синхронному
Запрос API преобразования речи в текст. Тем не мение,
вместо возврата ответа асинхронный запрос инициирует Длительная работа (типа
Эксплуатация) и возврат
эту операцию вызываемому объекту немедленно.
Ниже показан типичный ответ операции:
{
"имя": " имя_операции ",
"метаданные": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeMetadata"
"прогрессПроцент": 34,
"startTime": "2016-08-30T23:26:29.579144Z",
"lastUpdateTime": "2016-08-30T23:26:29.826903Z"
}
}
Обратите внимание, что пока нет результатов. Преобразование речи в текст продолжит
обработайте звук и используйте эту операцию для сохранения результатов.Результаты будут
появляются в поле ответа операция
возвращается, когда LongRunningRecognize запрос завершен.
Полный ответ после завершения запроса отображается ниже:
{
"имя": "1268386125834704889",
"метаданные": {
"lastUpdateTime": "2016-08-31T00:16:32.169Z",
"@type": "type.googleapis.com/google.cloud.speech.v1.LongrunningRecognizeMetadata",
"startTime": "2016-08-31T00:16:29. 539820Z",
"ПрогрессПроцент": 100
}
"отклик": {
"@тип": "тип.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeResponse",
"Результаты": [{
"альтернативы": [{
"уверенность": 0,98267895,
"стенограмма": "сколько лет Бруклинскому мосту"
}]}]
},
"готово": Верно,
}
 539820Z",
"ПрогрессПроцент": 100
}
"отклик": {
"@тип": "тип.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeResponse",
"Результаты": [{
"альтернативы": [{
"уверенность": 0,98267895,
"стенограмма": "сколько лет Бруклинскому мосту"
}]}]
},
"готово": Верно,
}
539820Z",
"ПрогрессПроцент": 100
}
"отклик": {
"@тип": "тип.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeResponse",
"Результаты": [{
"альтернативы": [{
"уверенность": 0,98267895,
"стенограмма": "сколько лет Бруклинскому мосту"
}]}]
},
"готово": Верно,
}
Обратите внимание, что выполнено установлено значение True и что ответ операции содержит набор результатов типа
Результат Распознавания Речи
тот же тип, который возвращается синхронным запросом на распознавание Speech-to-Text API.
По умолчанию асинхронный ответ REST будет установлен выполнено от до False , значение по умолчанию; однако, потому что
JSON не требует наличия значений по умолчанию в поле при тестировании.
завершена ли операция, вы должны проверить, что done Поле присутствует и установлено на True .
Запросы на распознавание потокового API преобразования речи в текст
Вызов распознавания потокового API преобразования речи в текст предназначен для захвата и распознавание аудио в двунаправленном потоке.Ваша заявка может быть отправлена аудио в потоке запроса и получать промежуточное и окончательное распознавание результаты в потоке ответов в режиме реального времени. Промежуточные результаты представляют текущий результат распознавания участка аудио, а окончательный результат распознавания представляет собой последнее, наилучшее предположение для этого фрагмента аудио.
Потоковые запросы
В отличие от синхронных и асинхронных вызовов, при которых вы отправляете
конфигурация и аудио в одном запросе, вызывая потоковую речь
API требует отправки нескольких запросов.Первый StreamingRecognizeRequest должен содержать конфигурацию типа
StreamingRecognitionConfig
без какого-либо сопутствующего звука. Последующие
Последующие StreamingRecognizeRequest отправлены
над одним и тем же потоком будет состоять из последовательных кадров необработанных аудиобайтов.
StreamingRecognitionConfig состоит из следующих полей:
-
config— (обязательно) содержит информацию о конфигурации аудио, типа Конфигурация распознавания и такое же, как показано в синхронных и асинхронных запросах. -
single_utterance— (необязательно, по умолчаниюfalse) указывает, является ли это запрос должен автоматически завершиться после того, как речь больше не будет обнаружена. Если установлено, Преобразование речи в текст обнаружит паузы, тишину или неречевой звук, чтобы определить когда прекратить признание. Если не установлено, поток будет продолжать слушать и обрабатывать звук до тех пор, пока либо поток не будет закрыт напрямую, либо предельная длина превышена. Установка single_utteranceнаtrueполезно для обработки голосовых команд. -
interim_results— (необязательно, по умолчаниюfalse) указывает, что это потоковый запрос должен возвращать временные результаты, которые могут быть уточнены в любое время. позднее время (после обработки большего количества аудио). Промежуточные результаты будут отмечены в ответах через настройкуis_finalдоfalse.
 Установка
Установка Потоковые ответы
Результаты потокового распознавания речи возвращаются в серии ответов типа StreamingRecognitionResponse.Такой ответ состоит из следующих полей:
-
speechEventTypeсодержит события типа SpeechEventType. Значение этих событий укажет, когда было определено, что одно высказывание было завершенный. Речевые события служат маркерами в вашем потоке.
отклик. -
результатовсодержит список результатов, которые могут быть как промежуточными, так и окончательными результаты типа Результат потокового распознавания. Список результатов-
альтернативысодержит список альтернативных транскрипций. -
isFinalуказывает, являются ли результаты, полученные в этой записи списка являются промежуточными или окончательными. Google может вернуть несколькоisFinal=trueрезультаты в одном потоке, но результатisFinal=trueтолько гарантируют после закрытия потока записи (полузакрытие). -
стабильностьуказывает на изменчивость результатов, полученных до сих пор, с0,0указывает на полную нестабильность, а1,0указывает на полную стабильность. Обратите внимание, что в отличие от достоверности, которая оценивает, является ли
транскрипция правильная, стабильностьоценивает, является ли данный частичный результат может измениться. Если дляisFinalустановлено значениеtrue,стабильностьне будет установлено.
-
 Речевые события служат маркерами в вашем потоке.
отклик.
Речевые события служат маркерами в вашем потоке.
отклик. Обратите внимание, что в отличие от достоверности, которая оценивает, является ли
транскрипция правильная,
Обратите внимание, что в отличие от достоверности, которая оценивает, является ли
транскрипция правильная, Общие инструкции по расшифровке и рецензированию
Чтобы обеспечить удобочитаемость и доступность исторических материалов, мы пересмотрели и упростили инструкции Центра расшифровки.Это не означает, что ранее завершенные проекты должны быть отредактированы, чтобы отразить эти изменения. Вместо этого перейдите к новой расшифровке и просмотрите ее, используя приведенные ниже обновленные рекомендации. Как всегда, мы приветствуем ваши комментарии и вопросы. Пишите нам сюда.
Как работает процесс
 На данный момент наша система работает следующим образом:
На данный момент наша система работает следующим образом:1) Любой может начать расшифровку или добавить к расшифровке документа. Расшифруйте часть или весь документ и нажмите «Сохранить», чтобы другие добровольцы могли помочь заполнить страницу.
2) Как только доброволец решит, что он «закончил» и страница готова для проверки, другой доброволец (который должен иметь учетную запись на сайте) может просмотреть расшифровку и либо отправить ее обратно для редактирования, либо завершить расшифровку.
3) Готовая стенограмма отправляется в Смитсоновский институт, где ее можно использовать сразу или подвергнуть дополнительной обработке.
Вернуться к началу
КАК ПЕРЕВОДИТЬ
НАПИШИТЕ ТО, ЧТО ВЫ ВИДИТЕ
Наша главная цель — создать текст, отражающий этот документ. Запишите слова и абзацы, как вы их видите.
Пожалуйста, сохраняйте оригинальные орфографию, грамматику, пунктуацию и порядок слов, даже если они грамматически неверны.
Вы можете указать правильное написание слова в двойных скобках рядом с неправильно написанным словом или в поле примечаний на соответствующей странице транскрипции, но это необязательно.
Пример: Эбигейл Адамс [[Эбигейл Адамс]].
Одно исключение: если слово переносится через дефис из-за того, что оно занимает две строки, печатайте его как одно слово. См. пример страницы.
Будьте проще
Наша цель — улучшить читаемость и удобство поиска, и мы хотим избежать загромождения страниц — не беспокойтесь о форматировании.
Сведите к минимуму использование двойных скобок [[ ]] для описания того, что вы видите, подумайте о читабельности и возможности поиска.Для математического или столбчатого формата по возможности избегайте использования двойных скобок и обязательно ознакомьтесь с конкретными инструкциями, включенными в проект, над которым вы работаете. См. «Дополнительные инструкции», чтобы узнать больше о расшифровке данных в столбцах и другом более сложном содержимом.
См. «Дополнительные инструкции», чтобы узнать больше о расшифровке данных в столбцах и другом более сложном содержимом.
Не указывать стиль шрифта, подчеркивание, полужирный или курсивный текст.
Чтобы еще больше упростить расшифровку, мы просим вас больше не указывать предварительно напечатанный текст или подписи в скобках.символы. Они должны быть просто написаны как McDonald, независимо от любого надстрочного индекса, написанного в исходном тексте.
Вставки в текст — Если вы встретите слово, которое было вставлено в предложение или фразу в исходном тексте, пожалуйста, перенесите его в предложение и напечатайте в том порядке, в котором вы будете читать его вслух. Нет необходимости использовать символы вставки или скобки для обозначения вставленного слова. См. пример страницы.
Удаленные слова или слова, зачеркнутые в исходном тексте —Пожалуйста, напишите «зачеркнуто» или «зачеркнуто» в двойных скобках до и после слова или фразы, которые были зачеркнуты или удалены.
Например: я действительно [[зачеркнутый]] ненавижу [[/зачеркнутый]] не люблю запах тухлых яиц. ИЛИ я действительно [[зачеркнуто]] ненавижу [[/зачеркнуто]] не люблю запах тухлых яиц. См. также пример страницы.
Существуют специальные инструкции для маргиналий (дополнительные примечания и т. д. к документу), таблиц и данных в столбцах, а также расшифровки то же самое , которые вы можете найти в дополнительных инструкциях.
Ничего страшного, если у вас нет времени на выполнение всей транскрипции.Даже добавление одного-двух предложений облегчает работу над ним следующему человеку. Часто два или более добровольцев должны работать вместе, чтобы закончить транскрипцию. Каждый бит помогает.
Каждый проект уникален, пожалуйста, прочтите описание проекта, прежде чем начать. Также обратите внимание на любые заметки, оставленные на странице транскрипции, и, пожалуйста, НЕ УДАЛЯЙТЕ любые предыдущие заметки, оставленные другими добровольцами. Они помогают нам отслеживать изменения, записывать дополнительную информацию о коллекциях и отвечать на вопросы.
Они помогают нам отслеживать изменения, записывать дополнительную информацию о коллекциях и отвечать на вопросы.
ИЗОБРАЖЕНИЯ
Когда вы видите эскиз, рисунок или штамп/печать, используйте слово «изображение» или «штамп» и т. д., заключенное в двойные скобки: [[изображение]] [[штамп]]. Если есть какие-либо подписи или текст, связанный с изображением, расшифруйте их. См. пример страницы.
Если инструкции по проекту не требуют описания изображений, вы можете выбрать описание изображения или изображений в поле примечаний на каждой соответствующей странице.Это необязательно. См. пример страницы.
Имейте в виду, что некоторые изображения содержат описания на обратной стороне фотографии, отображаемые на предыдущем изображении транскрипции. Обязательно проверьте это. Если это так, пожалуйста, укажите, что описание изображения существует на следующей странице. Пример: [[изображение — подпись см. на следующей странице]]. См. пример страницы.
на следующей странице]]. См. пример страницы.
ЧАСТО СОХРАНЯТЬ
Расшифровка может быть тяжелой работой, поэтому убедитесь, что вы часто сохраняете (каждые пару минут).Нажмите кнопку [Сохранить], расположенную под формой транскрипции, чтобы сохранить ваш прогресс. Помните, что никто не может редактировать страницу, пока вы над ней работаете (вы должны увидеть надпись «Заблокировано» желтым цветом в правом верхнем углу экрана). Если вы хотите двигаться дальше, вы можете нажать оранжевую кнопку [Завершить и отметить для проверки] или [Сохранить] и использовать кнопки навигации над полем транскрипции для смены страниц. Система предоставит вашу страницу другим пользователям для редактирования, если вы не нажмете ни одну кнопку ([Сохранить] или [Завершить и отметить для просмотра]) в течение 5-10 минут.Поэтому чаще сохраняйте страницу, чтобы сохранить ее для себя, если вы все еще работаете над ней.
ЕСЛИ ВЫ НАШЛИ СЛОВО, КОТОРОЕ НЕ МОЖЕТЕ ПРОЧИТАТЬ
Пожалуйста, сделайте примечание, используя двойные скобки [[ ]] следующим образом: [[хорошее предположение?]] или просто [[?]]. См. пример страницы ниже. Сохраните свою работу, и вы можете продолжить расшифровку остальной части элемента. Иногда слово почти невозможно расшифровать (даже для лучших из нас!), поэтому 1-2 [[?]] оставшихся на странице приемлемо для того, чтобы оно было помечено как «Завершено».» Если страница была в основном расшифрована, но по-прежнему содержит 2 или более [[?]], пожалуйста, НЕ отправляйте эту страницу со статусом «Завершено», а вместо этого оставьте ее на стадии «транскрипция» или «проверка», чтобы другие волонтеры могут продолжить работу над ним. Не стесняйтесь обращаться к нам и своим коллегам-волонтерам, оставив вопрос в поле заметок на странице транскрипции, через «вкладку обратной связи» сбоку страницы, в социальных сетях или через напишите нам напрямую.
См. пример страницы ниже. Сохраните свою работу, и вы можете продолжить расшифровку остальной части элемента. Иногда слово почти невозможно расшифровать (даже для лучших из нас!), поэтому 1-2 [[?]] оставшихся на странице приемлемо для того, чтобы оно было помечено как «Завершено».» Если страница была в основном расшифрована, но по-прежнему содержит 2 или более [[?]], пожалуйста, НЕ отправляйте эту страницу со статусом «Завершено», а вместо этого оставьте ее на стадии «транскрипция» или «проверка», чтобы другие волонтеры могут продолжить работу над ним. Не стесняйтесь обращаться к нам и своим коллегам-волонтерам, оставив вопрос в поле заметок на странице транскрипции, через «вкладку обратной связи» сбоку страницы, в социальных сетях или через напишите нам напрямую.
СПЕЦИАЛЬНЫЕ СИМВОЛЫ
Вводить специальные символы может быть сложнее, поэтому просто делайте все возможное.Вы всегда можете оставить слово нерасшифрованным и сообщить другим расшифровщикам и рецензентам, что необходимо проделать дополнительную работу, набрав [[?]] вместо слова или части слова, требующей специальных символов. Вот список сочетаний клавиш для некоторых из наиболее часто встречающихся специальных символов (для ПК):
Вот список сочетаний клавиш для некоторых из наиболее часто встречающихся специальных символов (для ПК):
ç — Альтернативный 1159
ü — Альтернативный 1153
ñ — Альтернативный 164
á — Альтернативный 0225
é — Альтернативный 130
è — Альтернативный 138
¢ — Альтернативный 0162
— (длинное тире) — Альтернативный 0151
• (маркер) — Alt 0149
МАРКИРОВКА ДЛЯ ПРОВЕРКИ
Пожалуйста, нажимайте оранжевую кнопку «ЗАВЕРШИТЬ и ПОМЕТИТЬ ДЛЯ ПРОСМОТРА» только после расшифровки ВСЕЙ страницы.Вы можете просто расшифровать одно слово, предложение или всю страницу, но если страница расшифрована не полностью, пожалуйста, только нажмите СОХРАНИТЬ, чтобы другие волонтеры знали, что еще предстоит выполнить расшифровку.
Вернуться к началу
КАК ПРОВЕРИТЬ
Когда доброволец завершает транскрипцию и отмечает ее для проверки, хорошо, если к ней привлечет еще одна пара глаз. Вот как просмотреть транскрипцию:
Вот как просмотреть транскрипцию:
- В качестве рецензента у вас должна быть учетная запись в Центре транскрипции, которую вы можете создать здесь.
- Обязательно прочитайте Общие и Расширенные инструкции, чтобы выявить ошибки в расшифровке. Проверьте документ на точность и полноту.
- Прочитайте всю расшифровку и внимательно сравните ее с исходным текстом.
ЕСЛИ ПЕРЕВОД ЗАВЕРШЕН И ГОТОВ:
Нажмите кнопку [Пометить как выполненную] (зеленую).После этого элемент будет помечен как «Выполнено и ожидает утверждения».
ЕСЛИ ВЫ СЧИТАЕТЕ, ЧТО ЕСТЬ ОШИБКИ, КОТОРЫЕ НЕОБХОДИМО ИСПРАВИТЬ:
- Нажмите кнопку [Повторно открыть для редактирования] (синяя).
- Внесите изменения и измените транскрипцию, чтобы она соответствовала странице, и исправьте ошибки. Не забывайте избегать редактирования оригинальной орфографии и грамматики.
- После того, как вы внесли изменения, нажмите кнопку [Завершить и отметить для проверки] — после этого для проверки потребуется новый доброволец.

Если вы столкнулись с проектом «ЗАВЕРШЕНО и ОЖИДАЕТ УТВЕРЖДЕНИЕ», который содержит ошибки и нуждается в дальнейшем редактировании, вы можете связаться с командой TC, нажав «кнопку обратной связи» сбоку на каждой странице проекта или написав нам по электронной почте напрямую по адресу transcribe @si.edu. Обязательно укажите URL-ссылку на рассматриваемую страницу, и команда TC ответит, повторно открыв страницу для расшифровки и просмотра.
Дополнительные советы по рецензированию см. в публикации волонтера Бет Грэм о ее процессе.
ДОПОЛНИТЕЛЬНЫЕ ИНСТРУКЦИИ И СОВЕТЫ
Нажмите здесь, чтобы найти дополнительную информацию о проектах, требующих расширенных или специальных рекомендаций, а также инструкции по расшифровке полей, таблиц и данных в столбцах, а также пометок.
Вернуться к началу
.
