Урок 5. Логарифмические вычисления | Уроки математики и физики для школьников и родителей
Переход от данной основы до другой.Если необходимо перейти от логарифмов с основанием а до логарифмов с основанием b, пользуются таким тождеством:
Множительназывают модулем переходу.
Очень часто в логарифмических преобразованиях пользуются также такими формулами:
ПРИМЕР:Используя формулу
получимПРИМЕР:
Вычислить
Зная, чтоЛогарифмирование.
Прологарифмировать выражение – значит выразить его логарифм через логарифмы отдельных чисел, которые входят в это выражение. Это можно сделать, используя теоремы про логарифм суммы, деления, степени и корня.
Логарифм произведения равен сумме логарифмов множителей.
Логарифм частного (дроби) равен разности логарифмов делимого и делителя.
Логарифм степени равен произведению показателя степени на логарифм его основания.
Логарифм корня равен частному от деления логарифма подкоренного числа на показатель корня.
Необходимо иметь ввиду, что логарифм суммы не равен суммы логарифмов, то есть нельзя вместо
Нельзя также вместо Все сформулированные выше теоремы справедливы для положительных значений а и b. Прологарифмировать выражение: logx = log3 + logb + logc.
Прологарифмировать выражение:
logx = loga – logbc =Прологарифмировать выражение:
logx = loga3 + logb2
Прологарифмировать выражение
: ПРИМЕР:Прологарифмировать выражение:
ПРИМЕР:Прологарифмировать выражение:
logx =1/2 loga + 1/4 loga + 1/8 loga – 1/9 loga Потенцирование.
 Если по данным результатом логарифмирования находят выражение, из которого получен
этот результат, то такую операцию называют потенцированием.
Если по данным результатом логарифмирования находят выражение, из которого получен
этот результат, то такую операцию называют потенцированием.Потенцировать выражение:
ПРИМЕР:Потенцировать выражение:
Задания к уроку 5Логарифмические уравнения, формулы и онлайн калькуляторы
Определение
Логарифмическое уравнение — это такое уравнение, в котором неизвестная стоит под знаком логарифма.
Логарифмировать алгебраическое выражение — значит выразить его логарифм через логарифмы отдельных чисел, входящих в это выражение.
Пример
Задание. Прологарифмировать выражение $x=3 b c$
Решение. В левой и правой части допишем логарифм по основанию $a$:
$\log _{a} x=\log _{a}(3 b c)$
По свойствам логарифмов логарифм произведения, стоящий в правой части, представим как сумму логарифмов от каждого из сомножителей, то есть:
$\log _{a} x=\log _{a} 3+\log _{a} b+\log _{a} c$
Больше примеров решенийОпределение
Если по данному результату логарифмирования находят выражение,
от которого получен этот результат, то такая операция называется потенцированием.
Второй корень не принадлежит ОДЗ, а значит решение $x=2$
Ответ. $x=2$
3. Логарифмическое уравнение вида $\log _{a} f(x)=\log _{a} g(x)$
Здесь $a$ — отличное от единицы положительное число; $f(x)$ и $g(x)$ — элементарные алгебраические функции.
Решение логарифмических уравнений такого типа сводится к решению уравнения $f(x)=g(x)$. Поэтому для решения рассматриваемого типа уравнений $\log _{a} f(x)=\log _{a} g(x)$ достаточно найти все решения уравнения $f(x)=g(x)$ и среди полученных выбрать те, которые относятся к ОДЗ уравнения $\log _{a} f(x)=\log _{a} g(x)$. Если уравнение $f(x)=g(x)$ решений не имеет, то их не имеет и исходное логарифмическое уравнение.
Пример
Задание. Решить уравнение $\ln (x+1)=\ln (2 x-3)$
Решение. Находим ОДЗ: $\left\{\begin{array}{l}x+1>0 \\ 2 x-3>0\end{array} \Rightarrow\left\{\begin{array}{l}x>-1 \\ 2 x>3\end{array} \Rightarrow\left\{\begin{array}{l}x>-1 \\ x>\frac{3}{2}\end{array} \Rightarrow\left(\frac{3}{2} ;+\infty\right)\right.
Решаем уравнение $x+1=2 x-3$ : $x=4 \in$ ОДЗ.
Итак, решением исходного логарифмического уравнения также является это значение.
Ответ. $x=4$
Больше примеров решенийЧитать дальше: логарифмические неравенства.
Метод логарифмирования
Решите уравнение методом логарифмирования.
Заданное уравнение представляет собой равенство двух степеней с положительными и отличными от единицы основаниями. Такие степени принимают только положительные значения, что следует из определения степени. Все это открывает дорогу для решения заданного уравнения методом логарифмирования.
Так как основаниями степеней в исходном уравнении являются числа 3, то логарифмирование целесообразно проводить по основанию 3. Логарифмирование обеих частей уравнения по основанию 3 дает уравнение . Оно с опорой на свойства логарифмов приводится к уравнению . Полученное уравнение равносильно исходному. Поэтому, решив его, мы получим нужное нам решение уравнения .
Полученное уравнение равносильно исходному. Поэтому, решив его, мы получим нужное нам решение уравнения .
Итак, все свелось к решению уравнения . Виден общий множитель , который стоит вынести за скобки. Также не помешает избавиться от дроби. Это подталкивает начинать решение по методу решения уравнений через преобразования:
Все проделанные преобразования являются равносильными преобразованиями, поэтому, полученное уравнение равносильно уравнению, которое было до проведения этих преобразований. Полученное уравнение , очевидно, можно решить методом разложения на множители:
Первое уравнение — иррациональное с тривиальным решением 0. Второе уравнение 2x−4=0 переносом четверки в правую часть приводится к простейшему показательному уравнению 2x=4 с легко находящимся единственным корнем 2 (2x=4, 2x=22, x=2). Завершающим этапом метода разложения на множители является проверка найденных корней. Проведем проверку подстановкой: оба найденных корня 0 и 2 удовлетворяют уравнению , значит, являются его корнями. Таким образом, уравнение имеет два корня 0 и 2.
Проведем проверку подстановкой: оба найденных корня 0 и 2 удовлетворяют уравнению , значит, являются его корнями. Таким образом, уравнение имеет два корня 0 и 2.
Остается сослаться на равносильность уравнения уравнению , которое в свою очередь равносильно исходному уравнению , и записать найденные корни в ответ.
зачем это нужно и как интерпретировать
В качестве дополнительной информации участникам семинара Аналитика для HR.Чаще всего у нас распределение зависимой переменной не носит характер нормального распределения (см. кстати, на эту тему пост Управление эффективностью.Распределение зависимой переменной (кейс по hr-аналитике)).
Вот, например, распределение зависимой переменной «стаж»
Или распределение показателей продаж сейлзов
Согласитесь, что даже визуально нет нормального распределения.
Чем это нам грозит? Искажением результатов регрессии. Помните, я показывал кейс с Москвой и Питером. Эти два случая сильно искажали результаты регрессии, их исключение из уравнение меняло R^2, коэффициенты.
 Т.е. данные, далеко отстающие от среднего значения, могут искажать уравнение регрессии. Наша задача минимизировать влияние таких данных. Желательно не исключая их.
Т.е. данные, далеко отстающие от среднего значения, могут искажать уравнение регрессии. Наша задача минимизировать влияние таких данных. Желательно не исключая их.В этом случае самый распространенный вариант действия — логарифмирование переменной
Если вы работаете в excel, то вы добавляете колонку рядом с той переменной, которую необходимо логарифмировать, и используете функцию LOG().Итого, прологарифмировав, вы получаете новую переменную. Для примера прологарифмируем переменную «стаж» на первом графике и получаем логарифмированный стаж с вот таким графиком
Это уже ближе к нормальному распределению.
И уравнение регрессии вы считаете для логарифмированной переменной.
Как интерпретировать
Тут самое забавное возникает: мы получаем уравнение на для стажа, а для лог стажа. К примеру у нас уравнение получает такой видlog(стаж) = 2.3 + 0.27(refferal)
Уравнение и коэффициент значимы.где 2.3 — константа, а 0.27 — коэффициент номинальной переменной источник подбора.
 Переменная у нас принимает два значение (0 — если источник побора Jobsites и 1 — если кандидат пришел через друзей в компанию).
Переменная у нас принимает два значение (0 — если источник побора Jobsites и 1 — если кандидат пришел через друзей в компанию).Таким образом, уравнение получает два результата
для Jobsites — 2.3
для рефералов — 2.57
Понятно, что данные цифры не имеют физического смысла, вы не пойдете докладывать руководству о том, что у вас средний стаж равен логарифму … Вам надо их прои нтепретировать, перевести в «живое» время.
Переводятся результаты обратной логарифмированию функцией — экспонентой.
В excel это функция EXP
EXP(2.3) = 9.97418245481472
EXP(2.57) = 13.0658244409346
Таким образом средний срок работы кандидата, пришедшего через jobsites равен 10 месяцев, через друзей — 13 месяцев. Разница — 3 месяца
Эконометрическое прогнозирование
Эконометрическое прогнозирование Эконометрическое прогнозирование по временным рядамЭкспоненциальная модель
Когда у исследователя создается впечатление, что на заданном для анализа участке временного ряда происходит постоянное ускорение процесса роста показателя, имеет смысл попробовать приблизить исходные данные функцией вида
где b0 – множитель, а b1 –
оценка годовой нормы прироста показателя. Эта модель
существенно нелинейна, но может быть сведена к
линейной посредством логарифмирования.
Эта модель
существенно нелинейна, но может быть сведена к
линейной посредством логарифмирования.
Теперь зависимость логарифма значения временного
ряда от момента наблюдения становится линейной, так
что снова можно применить простейший вариант
регрессионного анализа. При этом предварительно
следует прологарифмировать значения Y (будет
ли это десятичный, или натуральный логарифм – безразлично;
мы будем использовать натуральные логарифмы) и учесть,
что после построения регрессии константа уравнения
в действительности будет равна логарифму множителя,
коэффициент пропорциональности соответственно
логарифму нормы прироста показателя. Прогноз по
модели можно будет выполнить аналогично линейному
случаю, но важно, что после получения численного
значения придется взять его экспоненту, чтобы
перейти к тем же натуральным показателям, что и
в значениях исходного ряда. Соответственно ошибки
прогноза будут рассчитаны не для самого показателя,
а для его логарифма, и для получения интервальной
оценки также потребуется потенцирование. Тем не
менее все эти операции не представляют особой
сложности в электронных таблицах.
Соответственно ошибки
прогноза будут рассчитаны не для самого показателя,
а для его логарифма, и для получения интервальной
оценки также потребуется потенцирование. Тем не
менее все эти операции не представляют особой
сложности в электронных таблицах.
Вы можете сразу посмотреть итоговые результаты экспоненциального моделирования объема продаж фирмы Kodak и выводы, либо загрузить таблицу в формате Quattro или в формате Excel и выполнить упражнение, а затем сравнить свои результаты с представленными ниже.
|


Результаты расчета коэффициентов регрессии
| Результат регрессионного анализа | |
| Константа | 1. 061 061 |
| Оценка стандартной ошибки Y | 0.109 |
| Коэффициент вариации | 0.970 |
| Число наблюдений | 23 |
| Степени свободы | 21 |
| Коэффициент(ы) X | 0.090 |
| Стандартная ошибка коэффициента | 0.003 |
| Критерий Стьюдента | 26.048 |
В данном случае константа и коэффициент регрессии
относятся именно к прологарифмированному уравнению,
поэтому после получения прогноза непосредственно из
уравнения регрессии (5-я колонка таблицы внизу, прогнозные значения)
следует пропотенцировать рассчитанные результаты,
чтобы получить прогноз в нужных величинах.
Наблюдаемые и рассчитанные значения отклика
| Год | Измеренный объем выпуска | Логарифм объема выпуска | Значение X | Логарифм регрессионной оценки | Рассчитанное значение |
| 1970 | 2.8 | 1.030 | 1 | 1.150 | 3.159 |
| 1971 | 3. 0 0 |
1.099 | 2 | 1.240 | 3.455 |
| 1972 | 3.5 | 1.253 | 3 | 1.329 | 3.778 |
| 1973 | 4.0 | 1.386 | 4 | 7.419 | 4.132 |
| 1974 | 4.6 |  526 526 |
5 | 1.508 | 4.520 |
| 1975 | 5.0 | 1.609 | 6 | 1.598 | 4.943 |
| 1976 | 5.4 | 1.686 | 7 | 1.688 | 5.406 |
| 1977 | 6.0 | 1.792 | 8 | 1. 777 777 |
5.913 |
| 1978 | 7.0 | 1.946 | 9 | 1.867 | 6.467 |
| 1979 | 8.0 | 2.079 | 10 | 1.956 | 7.073 |
| 1980 | 9.7 | 2.272 | 11 | 2.046 | 7. 736 736 |
| 1981 | 10.3 | 2.332 | 12 | 2.135 | 8.461 |
| 1982 | 10.8 | 2.380 | 13 | 2.225 | 9.254 |
| 1983 | 10.2 | 2.322 | 14 | 2.315 | 10.121 |
| 1984 | 10. 6 6 |
2.361 | 15 | 2.404 | 11.069 |
| 1985 | 10.6 | 2.361 | 16 | 2.494 | 12.106 |
| 1986 | 11.5 | 2.442 | 17 | 2.583 | 13.241 |
| 1987 | 13.3 | 2. 588 588 |
18 | 2.673 | 14.482 |
| 1988 | 17.0 | 2.833 | 19 | 2.762 | 15.839 |
| 1989 | 18.4 | 2.912 | 20 | 2.852 | 17.323 |
| 1990 | 18.9 | 2.939 | 21 | 2. 942 942 |
18.946 |
| 1991 | 19.4 | 2.965 | 22 | 3.031 | 20.722 |
| 1992 | 20.1 | 3.001 | 23 | 3.121 | 22.663 |
| Прогнозные значения | |||||
| 1993 | — | — | 24 | 3. 210 210 |
24.787 |
| 1994 | — | — | 25 | 3.300 | 27.110 |
| 1995 | — | — | 26 | 3.389 | 29.650 |
| 1996 | — | — | 27 | 3.479 | 32.429 |
В данном случае модель предсказывает объем
чистых продаж на 1993 год на уровне 24. 8
миллиарда долларов, что заметно выше прогноза
по прочим моделям. Качество экспоненциальной
модели можно грубо оценить по коэффициенту
корреляции (0.97 — очень высокое значение,
хотя и сравнимое со случаем квадратичной модели).
Но прямое сравнение этих двух моделей по критерию
Фишера непосредственно из результатов регрессионного
анализа невозможно, поскольку в квадратичной
модели отклик задан в натуральных величинах, а в
экспоненциальной — в их логарифмах, и стандартная
ошибка модели рассчитана именно для логарифма отклика.
И тем не менее дисперсионное сопоставление выполнить
можно: следует только рассчитать дефект модели в
каждой точке ряда, возвести разности в квадрат,
просуммировать по всему ряду и поделить на число
степеней свободы – получится значение дисперсии
адекватности модели именно для натуральных
показателей ряда. В нашем случае дисперсия адекватности
экспоненциальной модели выше дисперсии для квадратичной,
но ниже, чем для линейной, хотя все эти модели неразличимы
с точки зрения критерия Фишера при доверительной
вероятности 95%.
8
миллиарда долларов, что заметно выше прогноза
по прочим моделям. Качество экспоненциальной
модели можно грубо оценить по коэффициенту
корреляции (0.97 — очень высокое значение,
хотя и сравнимое со случаем квадратичной модели).
Но прямое сравнение этих двух моделей по критерию
Фишера непосредственно из результатов регрессионного
анализа невозможно, поскольку в квадратичной
модели отклик задан в натуральных величинах, а в
экспоненциальной — в их логарифмах, и стандартная
ошибка модели рассчитана именно для логарифма отклика.
И тем не менее дисперсионное сопоставление выполнить
можно: следует только рассчитать дефект модели в
каждой точке ряда, возвести разности в квадрат,
просуммировать по всему ряду и поделить на число
степеней свободы – получится значение дисперсии
адекватности модели именно для натуральных
показателей ряда. В нашем случае дисперсия адекватности
экспоненциальной модели выше дисперсии для квадратичной,
но ниже, чем для линейной, хотя все эти модели неразличимы
с точки зрения критерия Фишера при доверительной
вероятности 95%. Что касается применения критерия
Стьюдента к коэффициенту экспоненциальной модели,
то он показывает отчетливую значимость при всех
разумных доверительных вероятностях.
Что касается применения критерия
Стьюдента к коэффициенту экспоненциальной модели,
то он показывает отчетливую значимость при всех
разумных доверительных вероятностях.
Неудивительно в свете сопоставления статистических характеристик моделей, что именно квадратичная модель в данном случае дала лучший прогноз вперед, хотя и прогнозы линейной и экспоненциальной моделей не слишком сильно отклонялись от коридора ошибок.
Следует признать, что в отношении прогнозов
экономических явлений регрессионные модели на длинных
временных рядах страдают тем пороком, что они
учитывают и недавнее, и давно прошедшее состояние
моделируемой системы с постоянным весовым фактором.
Естественно рассчитывать, что эффект последних
лет оказывает большее влияние на будущее состояние
системы, нежели древняя история. Расчеты взвешенной
регрессии также возможны, но допускают большой произвол
в вопросе выбора надлежащих статистических весов
для каждой точки временного ряда. Кроме того,
ни один из рассмотренных методов не способен
учитывать характерную цикличность экономических и
большинства природных явлений, а игнорирование одной
из компонент модели процесса может привести к ошибочным
и даже ложным выводам. Именно для устранения избыточной
субъективности исследователя и учета цикличности
разработаны другие методы прогнозирования.
Кроме того,
ни один из рассмотренных методов не способен
учитывать характерную цикличность экономических и
большинства природных явлений, а игнорирование одной
из компонент модели процесса может привести к ошибочным
и даже ложным выводам. Именно для устранения избыточной
субъективности исследователя и учета цикличности
разработаны другие методы прогнозирования.
Created 17.08.2007, Revised 13.04.2008 Используются технологии uCoz
Логарифмирование и потенцирование
Тема: « ЛОГАРИФМИРОВАНИЕ И ПОТЕНЦИРОВАНИЕ ВЫРАЖЕНИЙ»
План:
Логарифмирование выражений
Потенцирование выражений
Выполнение упражнений
Самостоятельная работа
Логарифмирование выражений
Логарифмирование – это нахождение логарифмов заданных чисел или выражений.
Прологарифмировать выражение – это значит выполнить следующий алгоритм:
Взять данное выражение в скобки и перед ними поставить знак логарифма по заданному основанию
Используя свойства логарифмов, необходимо убрать внутри логарифма такие действия, как возведение в степень, возведение в корень, умножение и деление
Пример: прологарифмировать выражение по основанию 10
Решение: 1. Взять данное выражение в скобки и перед ними поставить знак логарифма по заданному основанию
2.внутри логарифма находится умножение, возведение в степень 2 и деление. Избавимся от них по свойствам сложения и вычитания логарифмов, а также умножение числа на логарифм. Получим
Вывод: логарифмирование – это преобразование, при котором логарифм выражения с переменными приводится к сумме или разности логарифмов переменных
Потенцирование выражений
Потенцирование – это преобразование, обратное логарифмированию. Применяется при решении логарифмических уравнений
Применяется при решении логарифмических уравнений
Потенцировать выражение – это значит освобождаться от знаков логарифмов в процессе решения логарифмического выражения. Потенцировать можно только в том случае, когда и в левой и правой частях уравнения стоят по одному логарифму с одинаковыми основаниями и больше никаких действий с ними не производится.
То есть в этом случае можно избавиться от знаков логарифма вместе с основаниями и получим
f(x)=g(x)
Пример: потенцировать выражение log2 3x = log2 9
Решение: так как основания логарифмов одинаковые и в каждой части выражения стоят по одному логарифму и никаких действий больше нет, то избавляемся от логарифмов
3х = 9.
В результате получаем простое уравнение, которое решается за несколько секунд:
х = 9 : 3 = 3.
Выполнение упражнений
Прологарифмировать по основанию 10 выражение
Решение:
Здесь мы использовали формулу
Найти х, используя свойства логарифмов и потенцирование
Решение: в правой части выражения больше одного логарифма и есть еще дополнительные действия – это умножение числа на логарифм
используем свойство
Используем свойства сложения и вычитания логарифмов
потенцировать можно
Выполните потенцирование выражения:
Решение:
Самостоятельная работа
Решить из учебника №491(а, г), №492(а), №493(б), №497(в, г) стр.
 237
237Решить из учебника №7(под цифрой 3 под буквой а) стр. 274
 237
237Логарифмы — Справочник химика 21
По таблице антилогарифмов отыскивают число, соответствующее найденному логарифму [c.169]Для вычисления пользуются таблицей четырехзначных логарифмов и антилогарифмов [c.163]
В основу потарелочного термодинамического расчета ректификации нефтяных смесей в сложных разделительных системах в работе [84] положены коэффициенты разделения компонентов р,-между смежными секциями колонны. В качестве итерируемых величин приняты логарифмы коэффициентов разделения T] = lg pi, обеспечивающие получение более стабильного решения. Подробно с использованием коэффициентов разделения для анализа и расчета процесса ректификации можно ознакомиться по работе [84]. [c.93]
Вычисления следует проводить, пользуясь таблицами логарифмов и антилогарифмов .
 [c.156]
[c.156]Количественное обозначение реакции среды можно упростить, если принять за основу так называемый водородный показатель pH, определяемый как десятичный логарифм концентрации водородных ионов, взятый с обратным знаком pH = —Ig [Н+]. Тогда [c.189]
Заменяя натуральные логарифмы десятичными, получим [c.14]
Напомним, что водородный показатель pH представляет собой логарифм концентрации (вернее, активности) ГР-ионов, взятый с обратным знаком [c.84]
Далее вычисляют gy, пользуясь таблицами логарифмов [c.169]
В е эти вычисления нужно делать, пользуясь таблицами четырехзначных логарифмов и антилогарифмов, с точностью, отвечающей точности анализа (т. е. до четырех значащих цифр). Наоборот, вычисления объемов концентрированной соляной кислоты при приготовлении ее растворов являются приближенными, и потому все соответствующие величины целесообразно округлять. [c. 299]
299]
В разбавленных растворах сильных электролитов логарифм среднего коэффициента активности лектролита линейно зависит от квадратного корня из его ионной силы [c.81]
Пели прологарифмировать уравнение (1) и пер логарифмов на обратные, то получим [c.235]
В соответствии со сказанным выше величины pH и рО ляются как отрицательные логарифмы активностей Н+- и ОН [c.235]
Чтобы от [Н ] перейти к pH, прологарифмируем уравнение (2) и переменим знаки логарифмов на обратные. При этом получим [c.261]
Логарифмируя и меняя у логарифмов знаки на обратные, на ходим [c.264]
Логарифмируя и меняя знаки у логарифмов на обратные, получим [c.275]
Обозначая отрицательный логарифм концентрации (точнее, активности) определяемых С1 -ионов через рС1, можно написать [c.316]
Если подставить числовые значения констант и от натуральных логарифмов перейти к десятичным, то для комнатной [c. 351]
351]
При этом, если некоторые из компонентов представляют собой твердую фазу, газообразное вещество, насыщающее раствор при постоянном давлении в одну атмосферу, либо молекулы вещества, концентрация которого настолько велика, что ее можно считать постоянной (например, молекулы растворителя), то они lit фигурируют под знаком логарифма, так как их активности, будучи постоян-ними, входят в величину как это будет показано в приведенных дальше примерах. [c.352]
Ясно, что величина Е зависит также и от концентрации Н+-ио-нов в растворе. Указанная величина концентрации входит в числитель дроби, стоящей под знаком логарифма, в степени, равной соответствующему стехиометрическому коэффициенту, например [c.353]
Факторы пересчета (с их логарифмами) для важнейших весовых определений приводятся в химических справочниках . Поль-зонаппе факторами пересчета значительно облегчает вычисления, что особенно важно в условиях промышленных лабораторий, где имеют дело с массовыми определениями одних и тех же элементов. [c.156]
[c.156]
Очевидно, при определении стандартного потенциала в этих случаях необходимо не только равенство концентраций окисленной и восстановленной форм в растворе, но и создание концентрации Н , равной единице. Действительно, только тогда дробь, стоящая под знаком логарифма, будет равна единице, и == / . [c.353]
Так как выражение, стоящее под знаком логарифма, — это константа равновесия рассматриваемой реакции, то [c.358]
Вычислим, наконец, величину Е в точке эквивалентности. Для этого в приведенных выше выражениях (1) и (2) уравняем коэффициенты при членах, содержащих логарифмы [путем умножения [c.361]
Переходя от натуральных к десятичным логарифмам, получим [c.461]
Из (3.64) видно, что с ростом концентрации электролита коэффициент активности должен возрас тать по сравиеиню с дебай-гюккелевским коэффициентом и может принимать значения больше единицы. Действительно, когда концентрация раствора растет, U2 уменьшается (й2 всегда меньи1е единицы) и второе слагаемое увеличивается. Точно так же, с ростом концентрации пи уменьшается, поэтому, хотя V растет, числитель будет расти медленнее знаменателя, т. е. под логарифмом всегда будет правильная дробь, уменьшающаяся с ростом концентрации, а следовательно, и третье слагаемое должно возрастать, оставаясь все время положительным. Для проведения расчетов уравнение (3.64) целесообразно не- [c.95]
Действительно, когда концентрация раствора растет, U2 уменьшается (й2 всегда меньи1е единицы) и второе слагаемое увеличивается. Точно так же, с ростом концентрации пи уменьшается, поэтому, хотя V растет, числитель будет расти медленнее знаменателя, т. е. под логарифмом всегда будет правильная дробь, уменьшающаяся с ростом концентрации, а следовательно, и третье слагаемое должно возрастать, оставаясь все время положительным. Для проведения расчетов уравнение (3.64) целесообразно не- [c.95]
Коэффициент толстостенности р определяем по величине логарифма коэффициента толстостенности 1п Р = р,/(0д сф) =31,4/(1 75 1) =0,179 (ф=1 см. 4.2). [c.170]
Величина, обратная г ( ), может быть разложена на простейшие дроби, каждая из которых дает при интегрировании логарифм или отрицательную степень в случае, когда — кратный корень [c.95]
В этих уравнениях и В являются константами, соответственно равными логарифмам коэффициентов активности компонентов при бесконечном разбавлении. В этом легко убедиться, решив два последних уравнения относительно А тя. В. [c.52]
В этом легко убедиться, решив два последних уравнения относительно А тя. В. [c.52]
Из уравнения (11.102) видно, что логарифмы константы равновесия 1п К линейно зависит от обратного [c.91]
В формулах (4,32) — (4.34) О — внутренний диаметр, м С — прибавка па коррозию, м С] — конструктивно-технологическая прибавка, м Хц—толщина центральной обечайки, м 3 — коэффи-циенг голстостешюсти определяется по величине логарифма коэффициента толстостенности 1п 3 = )/(адопф) (табл. 4.9), где р — расчетное давление, А4Па Одои — допускаемое напряжение, МПа, Ф — коэффициент прочности сварного шва. [c.169]
Важной характерной особенностью формул, определяющих дебит жидкости и газа, является слабая зависимость дебита от радиуса контура питания Л, и от радиуса скважины г , так как эти радиусы входят в формулы под знаком логарифма. [c.78]
Переходя от функции Лейбензона к давлению, найдем, что для несжимаемой жидкости давление в каждой зоне подчинено логарифмическому закону, а для газа-корню квадратному из логарифма радиуса (формулы приведены в табл. 3.7). [c.96]
3.7). [c.96]
Пределы существования бинарного гомоазеотропа наглядно представляются на графике Натинга и Хорсли, дающем зависимости логарифма давления паров чистых компонентов а ж IV системы и образуемого ими азеотропа от величины 1/(230 — — г) °С. В соответствии с уравнением Антуана (1.54) по оси абсцисс откладывается величина I — — С)» , а по оси ординат значение lg Р, тогда линии давлений насыщенных паров чистых компонентов, а также азеотропа, как правило, выпрямляются, по крайней [c.324]
И наконец, округляя резулр>тат до трех значащих цифр, находим окончательно у = 59,5%. Если то же вычисление провести без запасной цифры, то мы получим несколько отличающийся результат, а именно 59,6%. Впрочем, поскольку последняя цифра результата является недостоверной, такая разница вполне допустима. Отсюда ясно, что соблюдение правила об оставлении при вычислениях одной запасной цифры является желательным, но не обязательным. Иногда (например, при вычислении с таблицами четырехзначных логарифмов, когда запасная цифра являлась бы пятой значащей цифрой) от него приходится отступать. [c.60]
[c.60]
Для характеристики термодинамической устойчивостн электрохимических систем в водных средах весьма удобны диаграммы потенциал— отрицательный логарифм активности водородных ионов (диаграммы ё — pH), получив1иие широкое применение главным образом благодаря работам Пурбе и его школы. Для построения таких диаграмм, часто называемых диаграммами Пурбе, необходимо располагать сведениями об основных реакциях (окисления и восстановления, комплексообразования и осаждения), возможных в данной системе, об их количественных характеристиках (изобарно-изотермических потенциалах, произведениях растворимости и т. д.) и передать их графически в координатах S — pH. Для водных сред, естественно, наиболее важной диаграммой — pH следует считать диаграмму электрохимического равновесия воды. [c.186]
Уравнения (3.18) — (3.21) устанавливают связь между константами диссоциации, выраженными в т(фминах активности и концентрации, Подобным же образом можно установить связь и для других случаев химического равновесия в идеальных и в реальных растворах. Так, иапример, водородный показатель в реальных растворах должен быть равен отрицательному десятичному логарифму активности иопов водорода [c.78]
Так, иапример, водородный показатель в реальных растворах должен быть равен отрицательному десятичному логарифму активности иопов водорода [c.78]
Или, после перехода к десятичному логарифму и подстановки численных значений постоянных величгн, [c.88]
Очевидно, что чем сильнее кислота, тем ее константа ионизации больше (табл. 21). Для характеристики силы кислоты часто вместо Ка н[1именяют отрицательный десятичный логарифм ее численного значег ия и обозначают рКа [c.183]
Часто вместо значений ПР применяют показатель растворимости рПР. Под последним понимают отрицательный логарифм произведения растворимости рПР = — lgПP. [c.191]
Поскольку Ха1 И Ха ыольные ДОЛИ Б ЖИДКОЙ фазе компонента а — меньше 1, логарифм поддается разложению [c.73]
Общая химия (1979) — [ c.520 ]
Лабораторная техника химического анализа (1981) — [
c. 246
]
246
]
Справочник по аналитической химии (1975) — [ c.416 ]
Справочник по аналитической химии (1962) — [ c.256 ]
Справочник по английской химии (1965) — [ c.256 ]
Количественный анализ (0) — [ c.208 ]
Справочник по химии Издание 2 (1949) — [ c.24 ]
Справочник по аналитической химии Издание 4 (1971) — [ c.416 ]
Справочник по аналитической химии Издание 3 (1967) — [ c.256 ]
Краткий справочник химика Издание 6 (1963) — [ c.570 , c.585 ]
Курс аналитической химии (1964) — [
c. 359
]
359
]
Количественный анализ (0) — [ c.547 ]
Краткий справочник химика Издание 4 (1955) — [ c.508 , c.524 ]
Краткий справочник химика Издание 7 (1964) — [ c.570 , c.585 ]
Справочник химика Издание 2 Том 1 1963 (1963) — [ c.0 ]
Справочник химика Том 1 Издание 2 1962 (1962) — [ c.0 ]
Справочник химика Том 1 Издание 2 1966 (1966) — [ c.0 ]
Справочник химика Изд.2 Том 1 (1962) — [ c.0 ]
Руководство по программированию на Прологе
Руководство по программированию на ПрологеОНЛАЙН-РУКОВОДСТВО ПО | |
Секунда Издание 1998 г.  | |
Добро пожаловать к Онлайн-руководству по программированию на Прологе, разработанному и поддерживаемому Романом Бартаком.Я открыл этот сайт как вклад в развивающуюся область языков логического программирования. и PROLOG в частности. Я хочу, чтобы это было введением в логическое программирование. и PROLOG для начинающих, но я также рассчитываю осветить некоторые более сложные темы. Это не имел в виду неклассифицированный набор ссылок на другие страницы, хотя я также включить некоторые интересные ссылки здесь.
Это второе издание прежнего интерактивного руководства по Prolog.
это приносит новый дизайн и лучшую организацию глав.Это также более «интерактивно», поскольку я включаю
Зона испытаний
где вы можете попробовать и протестировать свои программы Prolog в интерактивном режиме в веб-браузере с поддержкой Java. Наконец я
ожидайте добавить несколько глав по продвинутым темам, о которых вы меня просили. Я все еще изучаю возможность предоставить
Гайд в виде файла скачать но я пока не решил.
Если вы хотите узнать больше о автор сайта, добро пожаловать в мой Дом Страница. Кроме того, ваши комментарии, предложения и исправления высоко ценятся.
Итак, куда вам идти дальше?
Оглавление
Вы впервые знакомитесь с руководством или просто хотите обновить некоторые знание? Затем начните со страницы оглавления.Дополнения и исправления
Старый посетитель (не по возрасту, а по времени вашего последнего визит ;-)? Тогда страница Дополнения и исправления, отслеживающая изменения в руководстве, для вас.Тестовая зона
Вы хотите немедленно протестировать некоторые программы на Прологе? в вашем веб-браузере? Затем перейдите непосредственно в тестовую зону, где доступна бесплатная реализация пролога на Java.Домашняя страница автора
Хотите узнать больше об авторе этого сайта? Затем посетите мой веб-сайт, на котором размещены некоторые другие программы на языке Prolog.Интерактивное руководство по Прологу (первое издание)
Если вы предпочитаете структуру оригинального Интерактивного руководства по Прологу, оно все еще доступно (по крайней мере, некоторое время)Курсы на компакт-диске
Если вы заинтересованы в получении руководства по Prolog на компакт-диске, посетите эту страницу и заполните форму.
 также доступны.
также доступны.Как перемещаться по сайту?
Вверху и внизу каждой страницы есть панель навигации. которые можно использовать для навигации по страницам. Каждая страница этого руководства имеет следующую схему:
……………..
кликабельный список вложенных глав кнопки навигации
Главная
Глава XПредыдущий | Содержимое | Следующий
Глава Х.
……………..
См. также:- другие ресурсы
Разработано и поддерживается Романом Бартаком Предыдущий | Содержимое | Следующий
кнопки навигации
 Д
ДНаконечники: Вы можете скрыть панели инструментов навигации и местоположения в своем браузере, чтобы увеличить видимую область.Вам не понадобится эти гаджеты для навигации по этому руководству. Не забудьте добавить эту страницу в закладки для быстрого доступа в будущем.

Благодарности
Веб-сервер и подключение к Интернету для этого сайта любезно предоставлено факультетом математики и физики Карлова университета в Праге. Я очень ценю все дополнительные сторонники.
Я также благодарен за все ободряющие электронные письма, отправленные мне во время разработка Путеводителя. Я ценю все электронные письма, выражающие ваше мнение, комментарии, предложения, исправления и пожелания о Гиде.
Адрес этого сайта: http://kti.mff.cuni.cz/~bartak/prolog/.
%PDF-1.4
%
1076 0 объект
>
эндообъект
внешняя ссылка
1076 119
0000000016 00000 н
0000004598 00000 н
0000004814 00000 н
0000004851 00000 н
0000005428 00000 н
0000005585 00000 н
0000005738 00000 н
0000005896 00000 н
0000006051 00000 н
0000006209 00000 н
0000006368 00000 н
0000006526 00000 н
0000006686 00000 н
0000006841 00000 н
0000007001 00000 н
0000007161 00000 н
0000007314 00000 н
0000007467 00000 н
0000007625 00000 н
0000007780 00000 н
0000007940 00000 н
0000008095 00000 н
0000009277 00000 н
0000010445 00000 н
0000010549 00000 н
0000012368 00000 н
0000014182 00000 н
0000014933 00000 н
0000014972 00000 н
0000015701 00000 н
0000016590 00000 н
0000017315 00000 н
0000018037 00000 н
0000018850 00000 н
0000020017 00000 н
0000020190 00000 н
0000022009 00000 н
0000022799 00000 н
0000023195 00000 н
0000037013 00000 н
0000050953 00000 н
0000066041 00000 н
0000068735 00000 н
0000068810 00000 н
0000068967 00000 н
0000069070 00000 н
0000069197 00000 н
0000069338 00000 н
0000069451 00000 н
0000069654 00000 н
0000069807 00000 н
0000069989 00000 н
0000070164 00000 н
0000070378 00000 н
0000070521 00000 н
0000070730 00000 н
0000070891 00000 н
0000071026 00000 н
0000071196 00000 н
0000071441 00000 н
0000071642 00000 н
0000071813 00000 н
0000072013 00000 н
0000072224 00000 н
0000072371 00000 н
0000072544 00000 н
0000072743 00000 н
0000072878 00000 н
0000073087 00000 н
0000073293 00000 н
0000073451 00000 н
0000073611 00000 н
0000073740 00000 н
0000073964 00000 н
0000074086 00000 н
0000074240 00000 н
0000074401 00000 н
0000074569 00000 н
0000074707 00000 н
0000074887 00000 н
0000075057 00000 н
0000075223 00000 н
0000075369 00000 н
0000075522 00000 н
0000075718 00000 н
0000075842 00000 н
0000075966 00000 н
0000076134 00000 н
0000076294 00000 н
0000076456 00000 н
0000076598 00000 н
0000076736 00000 н
0000076878 00000 н
0000077074 00000 н
0000077244 00000 н
0000077416 00000 н
0000077560 00000 н
0000077734 00000 н
0000077918 00000 н
0000078090 00000 н
0000078262 00000 н
0000078481 00000 н
0000078652 00000 н
0000078825 00000 н
0000079068 00000 н
0000079309 00000 н
0000079498 00000 н
0000079669 00000 н
0000079836 00000 н
0000080062 00000 н
0000080214 00000 н
0000080356 00000 н
0000080512 00000 н
0000080664 00000 н
0000080806 00000 н
0000080962 00000 н
0000081082 00000 н
0000081203 00000 н
0000002676 00000 н
трейлер
]/предыдущая 1204099>>
startxref
0
%%EOF
1194 0 объект
>поток
hVWSW/@ Xj f=BҖʶM)(IH-plDZ6uuU P+`,ZͶC@. xgW(Z,.6[«~QOrd .|_
xgW(Z,.6[«~QOrd .|_
Веб-сайт GNU Prolog
Веб-сайт GNU Prolog Текущая стабильная версия — gprolog-1.5.0GNU Prolog — бесплатный компилятор Пролога с решением ограничений над конечными областями, разработанными Даниэлем Диасом.
GNU Prolog принимает программы Prolog + ограничения и создает собственные двоичные файлы (как это делает gcc из исходного кода C). Затем полученный исполняемый файл автономный. Размер этого исполняемого файла может быть довольно маленьким, поскольку GNU Prolog можно избежать компоновки кода большинства неиспользуемых встроенных предикатов.Спектакли GNU Prolog очень обнадеживают (сравнимо с коммерческими системами).Помимо компиляции собственного кода, GNU Prolog предлагает классический интерактивный интерпретатор (верхнего уровня) с отладчиком.
Часть Prolog соответствует стандарту ISO для Prolog со многими очень полезные на практике расширения (глобальные переменные, интерфейс ОС, Розетки,.
GNU Prolog также включает эффективный решатель ограничений над конечными Домены (ФД). Это открывает возможность программирования логики ограничений для пользователя, комбинируя от силы программирования ограничений к декларативности логического программирования.
 ..).
..).Пролог-система:
- соответствует стандарту ISO для Пролога (числа с плавающей запятой, потоки, динамический код,…).
- множество расширений: глобальные переменные, грамматики с определенным предложением (DCG), интерфейс сокетов, интерфейс операционной системы,…
- более 300 встроенных предикатов Prolog.
- Отладчик Prolog и низкоуровневый отладчик WAM.
Возможность редактирования строки- под интерактивным интерпретатором с завершение на атомах.
- мощный двунаправленный интерфейс между Prolog и C.
Компилятор:
- Компилятор собственного кода, создающий автономные исполняемые файлы.
- простой компилятор командной строки, принимающий широкий спектр файлов: Файлы Prolog, файлы C, файлы WAM,…
- прямое создание ассемблерного кода в 15 раз быстрее, чем wamcc + гкк.
- большинство неиспользуемых встроенных предикатов не связаны (для уменьшения размер исполняемых файлов).
- скомпилированных предикатов (собственный код) в среднем так же быстро, как wamcc.
- обрабатывал предикаты (байт-код) в 5 раз быстрее, чем wamcc.
Решатель ограничений:
- Переменные FD хорошо интегрированы в среду Prolog (полный совместимость с переменными Пролога и целыми числами). Нет необходимости в явном декларации ФД.
- очень эффективный решатель FD (сравним с коммерческими решателями).
- высокоуровневых ограничений можно описать в терминах простых примитивов.
- много предопределенных ограничений: арифметические ограничения, логические ограничения, символические ограничения, материализованные ограничения,.
- несколько предопределенных эвристик перечисления.
- пользователь может определить свои собственные новые ограничения.
- более 50 встроенных ограничений/предикатов FD.

 ..
..Компилятор GNU Prolog основан на абстрактной машине Уоррена. (ВАМ). Сначала он компилирует программу Prolog в WAM-файл, который затем переводится на низкоуровневый машинно-независимый язык, называемый мини-сборкой специально разработан для GNU Prolog.Полученный файл затем переводится к языку ассемблера целевой машины (с которой объект полученный). Это позволяет GNU Prolog создавать собственный автономный исполняемый файл. из источника Prolog (аналогично тому, что делает компилятор C из программы C). Основным преимуществом этой схемы компиляции является создание машинного кода. и быть быстрым. Еще одна интересная особенность заключается в том, что исполняемые файлы имеют небольшой размер. Действительно, код большинства неиспользуемых встроенных предикатов можно исключить из исполняемые файлы во время компоновки.GNU Prolog также включает эффективный решатель ограничений над конечными Домены (ФД). Ключевой особенностью решателя GNU Prolog является использование единственного (низкоуровневый) примитив для определения всех (высокоуровневых) ограничений FD. Есть много преимуществ этого подхода: ограничения могут быть скомпилированы, пользователь может определить свои собственные ограничения (с точки зрения примитива), решатель открыт и расширяемый (в отличие от решателей типа «черный ящик», таких как CHIP),… Более того, Решатель GNU Prolog довольно эффективен, часто более эффективен, чем коммерческие решатели.

GNU Prolog вдохновлен двумя системами, разработанными одним и тем же автором:
- wamcc: компилятор Prolog to C. ключевой момент wamcc была его способность создавать автономные исполняемые файлы с использованием оригинальной компиляции схема: трансляция Пролога на Си через WAM. Его недостатком было то, время, необходимое gcc для компиляции исходников.
 Пролог GNU также может
создавать автономные исполняемые файлы, но с использованием более быстрой схемы компиляции.
Пролог GNU также может
создавать автономные исполняемые файлы, но с использованием более быстрой схемы компиляции.Разработка GNU Prolog началась в январе 1996 года под названием Калипсо.
- clp(FD): язык программирования с ограничениями поверх FD.Его ключевой особенностью было использование одного примитива для определения ограничений FD. GNU Prolog основан на той же идее, но расширяет возможности примитива до сделать возможными более сложные определения ограничений. По сравнению с clp(FD), GNU Prolog предлагает новые предопределенные ограничения, новые предопределенные эвристики, ограничения,…
В настоящее время поддерживаются следующие архитектуры:Если вы заинтересованы в переносе GNU Prolog на другую архитектуру прочитать файл PORTING в src.
- ix86/GNU/Linux
- ix86 / Win32 с использованием Cygwin (см. файл src/WINDOWS-OLD)
- ix86 / Win32 с использованием MinGW (см. файл src/WINDOWS-OLD)
- ix86 / Win32 с использованием MSVC++ (см.
- ix86/SCO
- ix86 / Солярис
- ix86 / FreeBSD
- ix86 / OpenBSD
- ix86/NetBSD
- ix86/Darwin (Mac OS X)
- x86_64 / GNU/Linux
- x86_64 / Солярис
- x86_64 / Win64 с использованием MinGW64 (см. файл src/WINDOWS)
- x86_64 / Win64 с использованием MSVC++ (см. файл src/WINDOWS)
- x86_64 / Дарвин (Mac OS X)
- PowerPC/GNU/Linux
- PowerPC/Darwin (Mac OS X)
- PowerPC/NetBSD
- sparc/SunOS (4.1.3 или выше)
- СПАРК / Солярис
- sparc / NetBSD
- альфа / GNU/Linux
- альфа/OSF1
- миль в секунду / irix
- рука 32 бита / GNU/Linux (armv6, armv7)
- 64-битная рука (aarch64)/GNU/Linux (armv8)
- 64-битная рука (aarch64) / Darwin (Mac OS X) (armv8)
Вы можете просмотреть следующие файлы:
 файл src/WINDOWS-OLD)
файл src/WINDOWS-OLD)
Данное руководство доступно в следующих форматах:
Мы предоставляем как исходный код, так и бинарный дистрибутив для GNU Prolog.Исходные дистрибутивы:
Бинарные дистрибутивы: Другие версии: Некоторые из этих файлов также можно загрузить с основного ftp-сайта GNU или с любого зеркала.Репозиторий GIT размещен на GitHub.
Для пользователей Windows: пользовательский язык Notepad++ (UDL) файл профиля для GNU Prolog (также доступны из Блокнот++ вики о УДЛ).Для установки: запустите Notepad++, в меню «Язык» выберите «Определить свой собственный язык», нажмите «Импорт» и выберите загруженный .xml файл. Затем закройте и перезапустите Notepad++. Файлы с суффиксами «.pl» и «.pro» должны теперь распознаются как файлы Prolog (иначе выберите «Prolog (GNU)» в «Языках», меню). Для получения дополнительной информации см. Блокнот++ вики.
GNU Prolog присутствует на сайте Black Duck Open Hub.
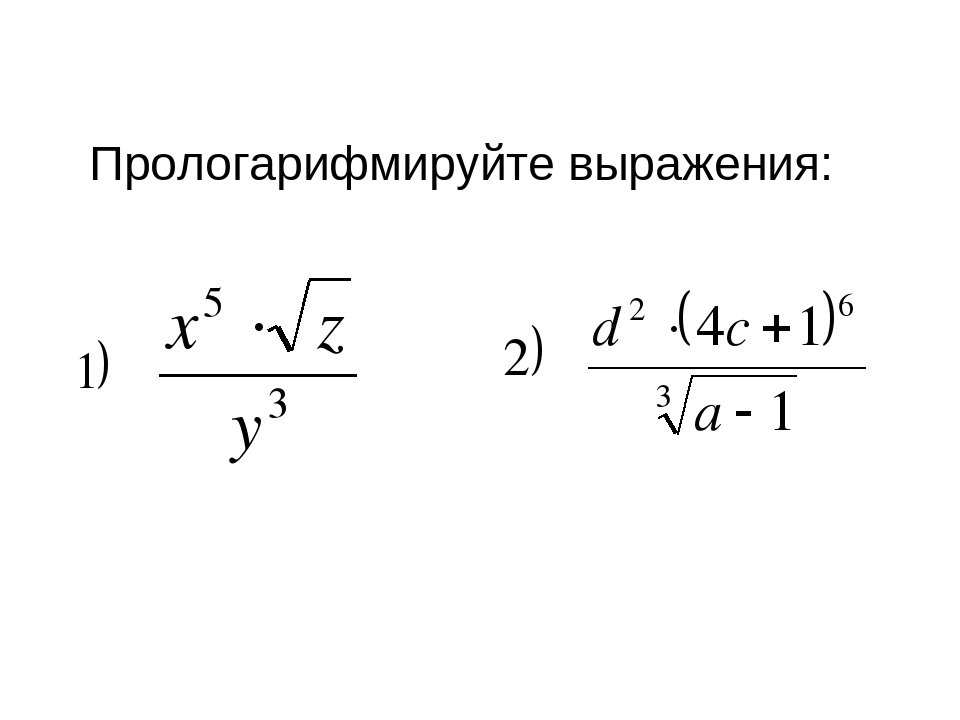
Участие приветствуется. Если вы хотите включить свой вклад отправьте письмо на адрес users-prolog@gnu.организация (для получения дополнительной информации об этом списке нажмите здесь). Вот список доступных взносов:
- Bedevere — обертка SWIG
- ЗАЖИМ — а CLP (интервалы) интерпретатор
- CLPGUI — графический пользовательский интерфейс для CLP
- cTI — ограниченный левый инструмент Termination Inference для ISO-Prolog
- GNU Prolog/CX — расширение GNU Prolog для контекстно-логического программирования
- gnuprolog-json — библиотека GNU Prolog JSON
- gnuprolog-redisclient — клиент GNU Prolog redis
- gprolog-rh — расширение gprolog с атрибутированными переменными, сопрограммами и CLP над реалами
- Logtalk — объектно-ориентированный расширение для Пролога
- Мышцы PS/SC — интерфейс к библиотеке Muscle PC/SC
- MySQL/Пролог — интерфейс к базе данных MySQL
- ODBC/Пролог — небольшой интерфейсный модуль ODBC для gprolog
- XGP — IDE для Mac OS X подключение gprolog и Cocoa
- CGI-программирование — введение в CGI-программирование с помощью GNU-Prolog
Список рассылки users-prolog@gnu.
 org: для общения
с другими пользователями и/или разработчиками GNU Prolog:
org: для общения
с другими пользователями и/или разработчиками GNU Prolog:Список рассылки bug-prolog@gnu.org: для сообщений ошибки:Чтобы сообщить другим пользователям, отправьте письмо по адресу bug-prolog@gnu.org. Чтобы (от)подписаться на этот список, отправьте письмо по адресу bug-prolog-request@gnu.org с (не)подписаться в строке темы. Вы также можете (от)подписаться через Интернет по адресу http://mail.gnu.org/mailman/listinfo/bug-prolog.
С того же сайта вы также можете просмотреть архив.
Сообщения об ошибках имеют решающее значение для нашей работы. Если мы не знаем о проблемы, мы не можем их исправить. С другой стороны, это пустая трата времени прочитать/проверить/ответить на наличие ошибок, которые не являются ошибками! Пожалуйста, обратитесь к руководству (доступна онлайн-версия). если ты можно попробовать проверить, возникает ли ошибка с последней нестабильной версией (все нестабильные версии здесь).Ваш отчет должен включать все эти вещи:
- Тип используемой вами машины (используйте uname -a в Unix).
- Версия GNU Prolog (используйте gprolog —version).
- Операнды, заданные для `configure’, и выходные данные конфигурации если ошибка касается этапа компиляции/установки.
- Полный текст всех файлов, необходимых для воспроизведения ошибки. Пытаться чтобы получить минимальный пример, показывающий ошибку.
- Точные команды, которые нам нужно ввести, чтобы воспроизвести ошибку.
- Описание наблюдаемого вами поведения, которое вы считаете неправильно.
- Если вы хотите упомянуть что-то в исходном коде GNU Prolog, покажите строка кода с несколькими строками контекста.
 Если вы уже используете последнюю нестабильную
версия попробовать
последняя стабильная версия. Когда вы уверены, что обнаружили ошибку,
пожалуйста, сообщите об этом по адресу bug-prolog@gnu.организация
(для получения дополнительной информации об этом списке нажмите здесь).
Если вы уже используете последнюю нестабильную
версия попробовать
последняя стабильная версия. Когда вы уверены, что обнаружили ошибку,
пожалуйста, сообщите об этом по адресу bug-prolog@gnu.организация
(для получения дополнительной информации об этом списке нажмите здесь). Не просто дайте линию
номер.
Не просто дайте линию
номер.Copyright (C) 1999-2021 Даниэль Диас
Разрешается дословное копирование и распространение всей этой статьи.
на любом носителе при условии сохранения этого уведомления.
Использование Пролога с AllegroGraph | AllegroGraph 7.2.0
Введение
Если вы новичок в Prolog, мы рекомендуем вам пройти это руководство, а затем изучить документацию Allegro Prolog, если вам нужны дополнительные сведения. Операторы пролога в AllegroGraph описаны в справочнике по Lisp. Примечание о различиях между использованием SPARQL и использованием Prolog для запросов можно найти в справочнике по SPARQL.
Это базовое руководство по использованию Пролога с AllegroGraph 7.2.0. Этого должно быть достаточно, чтобы начать работу, но если у вас есть какие-либо вопросы, обратитесь за помощью в службу поддержки Franz. В этом уроке мы сосредоточимся в основном на том, как использовать следующие конструкции:
Поскольку запрос Prolog может использоваться для оценки произвольного кода Lisp, для выполнения запросов Prolog требуется разрешение eval . Разрешения пользователей обсуждаются в разделе «Управление пользователями» в документе WebView.
Разрешения пользователей обсуждаются в разделе «Управление пользователями» в документе WebView.
Нотация Пролога
При обращении к Справочному руководству следует понимать соглашения по документированию предикатов Пролога (которые являются операторами Пролога, также называемыми функторами ).Здесь мы повторяем кое-что из того, что сказано в Справочном руководстве, и добавляем пример.
Вызов предиката Пролога (в синтаксисе Лиспа) выглядит как обычный вызов функции Лиспа; символ, именующий предикат, является первым элементом списка, а остальные элементы являются аргументами. Но аргументы для вызова предиката Prolog могут быть предоставлены в качестве входных данных для вызова или не предоставлены (то есть указаны как переменная, а не значение), так что предложение может возвращать возможные значения для этого аргумента в результате унификации некоторых данных для это или может быть дерево узлов, содержащее как наземные данные, так и переменные Пролога, как показано в примере ниже. Таким образом, в документации по предикатам мы должны различать аргументы, которые должны быть указаны со значением, аргументы, которые должны быть переменной, и аргументы, которые могут быть и тем, и другим. Мы опишем нотацию для этого после примера, чтобы показать, что мы имеем в виду, определяя значения или переменные.
Таким образом, в документации по предикатам мы должны различать аргументы, которые должны быть указаны со значением, аргументы, которые должны быть переменной, и аргументы, которые могут быть и тем, и другим. Мы опишем нотацию для этого после примера, чтобы показать, что мы имеем в виду, определяя значения или переменные.
В следующем примере используется предикат append , который имеет три аргумента и завершается успешно для любого решения, где третий аргумент совпадает с первыми двумя добавленными аргументами. Что примечательно в семантике Пролога, так это то, что append представляет собой декларативное отношение , которое работает независимо от того, какие аргументы предоставляются в качестве входных данных (значений), а какие — в качестве выходных данных (указанных как переменные).В примере используется интерпретатор Prolog. Результаты отображаются по одному. , указывающее, что пользователь нажимает клавишу Return, заставляет Prolog найти следующий результат, если он есть, или вывести Нет , если его нет. Символы, имена которых начинаются с ? являются переменными. (В этом примере используются простые выражения для иллюстрации вызовов Пролога и того, что мы имеем в виду, говоря, что аргументы могут быть указаны как значения или переменные. Вызовы, используемые в связи с AllegroGraph, более сложны и обычно возвращают списки троек результатов, а не результаты по одному.)
Символы, имена которых начинаются с ? являются переменными. (В этом примере используются простые выражения для иллюстрации вызовов Пролога и того, что мы имеем в виду, говоря, что аргументы могут быть указаны как значения или переменные. Вызовы, используемые в связи с AllegroGraph, более сложны и обычно возвращают списки троек результатов, а не результаты по одному.)
> (?- (добавить (1 2) (3) ?z)) ;; Спрашивает, какие значения ?z
;; удовлетворит вызов
?z = (1 2 3)
<возврат>
Нет.
;; Работает только ?z = (1 2 3).
> (?- (добавить (1 2) ?y (1 2 3))) ;; Спрашивает, какие значения ?y
;; удовлетворит вызов
?у = (3)
<возврат>
Нет. ;; Опять же, только одна возможность
> (?- (добавить ?x ?y (1 2 3))) ;; Какие значения ?x и ?y
;; буду работать? Есть четыре
;; возможности:
?х = ()
?у = (1 2 3)
<возврат>
?х = (1)
?y = (2 3)
<возврат>
?х = (1 2)
?у = (3)
<возврат>
?х = (1 2 3)
?у = ()
<возврат>
Нет. ;; И не более
> (?- (добавить ? (1 ?далее . ?) (1 2 1 3 4 1 5 1)))
?следующий = 2
<возврат>
?следующий = 3
<возврат>
?следующий = 5
<возврат>
№  ;; И не более
> (?- (добавить ? (1 ?далее . ?) (1 2 1 3 4 1 5 1)))
?следующий = 2
<возврат>
?следующий = 3
<возврат>
?следующий = 5
<возврат>
№
;; И не более
> (?- (добавить ? (1 ?далее . ?) (1 2 1 3 4 1 5 1)))
?следующий = 2
<возврат>
?следующий = 3
<возврат>
?следующий = 5
<возврат>
№ Последний пример последовательно унифицирует каждый элемент в списке, которому непосредственно предшествует 1 . Это показывает силу объединения против частично заземленной древовидной структуры.
Теперь вернемся к обозначениям: все подробности см. в разделе Пролог Справочного руководства по Лиспу, но вкратце префикс + перед аргументом в списке аргументов в документации указывает, что аргумент должен быть предоставлен как значение (это вход в предикат), префикс - указывает, что аргумент является выходным и не должен предоставляться (должен быть переменной), а префикс ± указывает, что аргумент может быть любым из них.
Также иногда имена, оканчивающиеся на /N , где N — число, появляются в документации Пролога и в отладчике: например, parent/2 . Это синтаксис предиката /арности . Часть этой нотации, которая является именем предиката, parent в этом примере, совпадает с символом Лиспа, именующим предикат. Неотрицательное целое число после косой черты — это арность , то есть количество аргументов предиката.Два предиката с одним и тем же именем предиката, но разными ариями — это совершенно разные предикаты. В примере далее в этом руководстве предикат parent/1 не имеет отношения к предикату parent/2 , который он вызывает.
Это синтаксис предиката /арности . Часть этой нотации, которая является именем предиката, parent в этом примере, совпадает с символом Лиспа, именующим предикат. Неотрицательное целое число после косой черты — это арность , то есть количество аргументов предиката.Два предиката с одним и тем же именем предиката, но разными ариями — это совершенно разные предикаты. В примере далее в этом руководстве предикат parent/1 не имеет отношения к предикату parent/2 , который он вызывает.
Пример данных и настройка
Этот учебник будет основан на крошечной генеалогической базе данных семьи Кеннеди.
Пожалуйста, откройте файл kennedy.ntriples , поставляемый с этим дистрибутивом (он будет находиться в подкаталоге tutorial клиента Lisp) в текстовом редакторе или с помощью TopBraidComposer и изучите содержимое файла.Обратите внимание, что люди в этом файле имеют тип, иногда несколько детей, несколько супругов, несколько профессий и посещали несколько колледжей или университетов.
Сначала давайте подготовим AllegroGraph к использованию. Здесь предполагается, что вы запустили сервер AllegroGraph и знаете, как загрузить свой любимый клиент Lisp в работающий Lisp. (Подробнее см. в кратком руководстве):
;; Мы удалили вывод следующих форм
> :ld [каталог клиента agraph]/agraph.фасл
> (в пакете: тройной пользователь магазина)
> (включить-!-читатель)
> (включить печать-декодирование t)
> (register-namespace "ex" "http://franz.com/simple#" :errorp nil) Теперь мы можем создать тройное хранилище и загрузить в него данные. Функция create-triple-store создает новый тройной магазин и открывает его. Если вы используете тройное хранилище с именем «тест», то AllegroGraph создаст тройное хранилище с именем test в корневом каталоге. Следующие три формы создадут хранилище и загрузят данные.Они работают, как написано, только с прямым клиентом Lisp. Если вы используете удаленный клиент, снова обратитесь к разделу «Быстрый старт» для получения дополнительных сведений об аргументах :port, :user и :password для create-triple-store.
> (создать-тройное хранилище «тест»: если-существует: заменить)
> (load-ntriples #p"sys:agraph;tutorial-files;kennedy.ntriples")
> (коммит-тройной магазин)
;; .... вывод удален. Итак, давайте сначала посмотрим на person1 в этой базе данных:
> (печать-тройки
(получить-тройной-список :s !ex:person1))
.
.
.
. .
 com/simple#1969> .
com/simple#1969> .
.
.
.
.
.
.
.
.
.
 com/simple#has-child>
com/simple#has-child> .
.
.
.
.
.
. Теперь мы готовы попробовать оператор select в сочетании с предикатом Prolog q-. Попробуем найти всех детей человек1 . Начните с ввода следующего в слушателе (объяснение следует).
> (выберите (?x)
(q- !ex:person1 !ex:имеет-ребенка ?x))
;; производит вывод:
(("http://Франц. com/простой#person9")
("http://franz.com/simple#person13")
("http://franz.com/simple#person17")
("http://franz.com/simple#person4")
("http://franz.com/simple#person6")
("http://franz.com/simple#person15")
("http://franz.com/simple#person11")
("http://franz.com/simple#person3")
("http://franz.com/simple#person7"))  com/простой#person9")
("http://franz.com/simple#person13")
("http://franz.com/simple#person17")
("http://franz.com/simple#person4")
("http://franz.com/simple#person6")
("http://franz.com/simple#person15")
("http://franz.com/simple#person11")
("http://franz.com/simple#person3")
("http://franz.com/simple#person7"))
com/простой#person9")
("http://franz.com/simple#person13")
("http://franz.com/simple#person17")
("http://franz.com/simple#person4")
("http://franz.com/simple#person6")
("http://franz.com/simple#person15")
("http://franz.com/simple#person11")
("http://franz.com/simple#person3")
("http://franz.com/simple#person7")) select — это оболочка, используемая вокруг одного или нескольких предложений Пролога. Первый элемент после select — это шаблон формата и переменных, которые вы хотите связать и вернуть.Итак, в этом примере мы хотим связать переменную Prolog ?x . Оставшееся объединение предложений сообщает Прологу, как ограничить привязку ?x в результирующем наборе.
Эта форма выбора содержит только одно предложение, а именно (q- !ex:person1 !ex:has-child ?x) .
Если вы изучали, как работает get-triples, то уже догадались, что q- является его аналогом в Прологе. q- вызывает get-triples и объединяет ?x с объектами всех троек с подлежащим !ex:person1 и предикатом !ex:has-child . 1
1
Чтобы усложнить задачу, найдем всех потомков потомков человека1:
> (выберите (?y)
(q- !ex:person1 !ex:имеет-ребенка ?x)
(q- ?x !ex:имеет-ребенка ?y))
;; производит вывод:
(("http://franz.com/simple#person33")
("http://franz.com/simple#person26")
("http://franz.com/simple#person28")
("http://franz.com/simple#person31")
("http://franz.com/simple#person25")
("http://franz.com/simple#person62")
("http://Франц.com/простой#person56")
("http://franz.com/simple#person42")
("http://franz.com/simple#person47")
("http://franz.com/simple#person51") ...) Хотя Пролог является декларативным языком, этот запрос легко читается процедурно:
Найти все тройки, у которых есть тема !ex:person1 и предикат !ex:has-child . Для каждого совпадения объедините ?x с объектом этой тройки; затем для каждой тройки, имеющей субъект ?x и предикат !ex:has-child , возвращаем объект.
Далее попробуем найти всех супругов внуков !ex:person1 . Обратите внимание, что select не возвращает в запросе информацию о переменных ?x и ?y . Шаблон выбора вернет только ?z , потому что это то, что находится в списке, который является первым аргументом.
> (выберите (?z)
(q- !ex:person1 !ex:имеет-ребенка ?x)
(q- ?x !ex:имеет-ребенка ?y)
(q- ?y !ex:супруга ?z))
;; производит вывод:
(("http://Франц.com/простой#person34")
("http://franz.com/simple#person27")
("http://franz.com/simple#person30")
("http://franz.com/simple#person32")
("http://franz.com/simple#person63")
("http://franz.com/simple#person57")
("http://franz.com/simple#person43")
("http://franz.com/simple#person49")
("http://franz.com/simple#person48")
("http://franz.com/simple#person52") ...) Теперь, если вы хотите, вы можете вернуть другие переменные. Вот тот же запрос, который также возвращает внука.
> (выберите (?y ?z)
(q- !ex:person1 !ex:имеет-ребенка ?x)
(q- ?x !ex:имеет-ребенка ?y)
(q- ?y !ex:супруга ?z))
;; производит вывод:
(("http://franz.com/simple#person33" "http://franz.com/simple#person34")
("http://franz.com/simple#person26" "http://franz.com/simple#person27")
("http://franz.com/simple#person28" "http://franz.com/simple#person30")
("http://franz.com/simple#person31" "http://franz.com/simple#person32")
("http://franz.com/simple#person62" "http://franz.com/простой#person63")
("http://franz.com/simple#person56" "http://franz.com/simple#person57")
("http://franz.com/simple#person42" "http://franz.com/simple#person43")
("http://franz.com/simple#person47" "http://franz.com/simple#person49")
("http://franz.com/simple#person47" "http://franz.com/simple#person48")
("http://franz.com/simple#person51" "http://franz.com/simple#person52")
...) Мы рассмотрели select и q- и знаем, как выполнять базовые запросы Prolog к тройному хранилищу. Далее мы увидим, как использовать больше возможностей Пролога:
Далее мы увидим, как использовать больше возможностей Пролога:
Расширение Пролога: определение новых предикатов
Предикаты определяются с использованием <-- и <- (мы объясним разницу ниже). Следующее определяет предикат, который успешен, если его первый и единственный аргумент является мужским, при условии, что необходимая тройка присутствует в памяти троек.
> (<-- (мужской ?x)
(q- ?x !ex:sex !ex:мужской))
мужской Давайте попробуем найти всех сыновей человека1.
> (выберите (?x)
(q- !ex:person1 !ex:имеет-ребенка ?x)
(мужской ?x)) ;;; Обратите внимание, как мы используем NO q здесь!
(("http://franz.com/simple#person13")
("http://franz.com/simple#person17")
("http://franz.com/simple#person4")
("http://franz.com/simple#person3")) Обратите внимание, что это эквивалентно более сложному запросу:
(выберите (?x)
(q- !ex:person1 !ex:имеет-ребенка ?x)
(q- ?x !ex:sex !ex:male)) Определим еще несколько полезных предикатов, чтобы расширить наш полезный словарь:
> (<-- (женский ?x)
(q- ?x !ex:sex !ex:женщина))
женский
> (<-- (отец ?x ?y)
(мужской ?x)
(q- ?x !ex:имеет-ребенка ?y))
отец
> (<-- (мать ?x ?y)
(женщина ?x)
(q- ?x !ex:имеет-ребенка ?y))
мать Отношения женщина , отец и мать просты для понимания. Мы также можем создавать более сложные отношения, которые могут быть удовлетворены более чем одним способом. Например, предположим, что мы хотим определить родительское отношение
Мы также можем создавать более сложные отношения, которые могут быть удовлетворены более чем одним способом. Например, предположим, что мы хотим определить родительское отношение : ?x является родителем ?y , если
-
?xявляется отцом?yили -
?xмать?y.
В Прологе это может быть реализовано как
> (<-- (родительский ?x ?y)
(отец ?x ?y))
родитель
> (<- (родительский ?x ?y)
(мать ?x ?y))
parent Обратите внимание, как мы определяем предикат parent , который состоит из двух правил: первое правило использует , а второе правило использует .Причина в том, что означает стереть все предыдущие правила и начать заново, тогда как означает добавить к существующим правилам предиката. Правила для любого конкретного предиката и арности образуют упорядоченный набор. При вызове этого предиката правила проверяются по порядку.
При вызове этого предиката правила проверяются по порядку.
Предикат parent можно было бы записать как одно правило с использованием предиката или . Эти два по существу эквивалентны и являются вопросом личных предпочтений.
> (<-- (родительский ?x ?y)
(или (отец ?x ?y)
(мама ?х ?у)))
parent В любом случае, можем ли мы использовать наш новый предикат, чтобы найти внуков человека1:
> (выберите (?y)
(родитель !ex:person1 ?x)
(родитель ?x ?y))
;; производит продукцию
(("http://franz.com/simple#person33")
("http://franz.com/simple#person26")
("http://franz.com/simple#person28")
("http://franz.com/simple#person31")
("http://Франц.com/простой#person25")
("http://franz.com/simple#person62")
("http://franz.com/simple#person56")
("http://franz.com/simple#person42")
("http://franz.com/simple#person47")
("http://franz.com/simple#person51") . ..)  ..)
..) Мы могли бы сделать то же самое, определив предикат grandparent.
> (<-- (прародитель ?x ?y)
(родительский ?x ?z)
(родитель ?z ?y))
бабушка и дедушка
> (<-- (внук ?x ?y)
(дедушка ?y ?x))
grandchild Наконец, мы можем определить предка , который является рекурсивным предикатом (т.е. он определяется в терминах самого себя).
> (<-- (предок ?x ?y)
(родитель ?x ?y))
предок
> (<- (предок ?x ?y)
(родительский ?x ?z)
(предок ?z ?y))
предок Читать предыдущие два выражения как
-
?xявляется предком?y, если-
?xявляется родителем?yили -
?xявляется родителем какого-либо лица?zи?zявляется предком?y
-
Потомок, конечно, противоположен предку
> (<-- (потомок ?x ?y)
(предок ?y ?x))
потомок Итак, если мы хотим найти всех потомков мужского пола человека person1, то вот как это сделать.
> (выберите (?x)
(потомок ?x !ex:person1)
(мужской? х))
;; производит вывод:
(("http://franz.com/simple#person13")
("http://franz.com/simple#person17")
("http://franz.com/simple#person4")
("http://franz.com/simple#person3")
("http://franz.com/simple#person33")
("http://franz.com/simple#person28")
("http://franz.com/simple#person31")
("http://franz.com/simple#person25")
("http://franz.com/simple#person62")
("http://franz.com/simple#person47") ...) Вот несколько головоломок, которые вы можете решить сами. Обратите внимание на использование вместо и part= в этих операторах. «не» может содержать любое выражение. part= сравнивает два своих аргумента как UPI.
> (<-- (тетя ?x ?y)
(отец ?z ?x)
(женщина ?x)
(отец ?z ?w)
(не (часть = ?x ?w))
(родитель ?w ?y))
тетя
> (<-- (дядя ?x ?y)
(отец ?z ?x)
(мужской ?x)
(отец ?z ?w)
(не (часть = ?x ?w))
(родитель ?w ?y))
дядя И последний запрос: найти всех детей человека1, которые являются дядями
> (выберите (?x ?y)
(родитель !ex:person1 ?x)
(дядя ?x ?y))
(("http://Франц. com/simple#person13" "http://franz.com/simple#person33")
("http://franz.com/simple#person13" "http://franz.com/simple#person26")
("http://franz.com/simple#person13" "http://franz.com/simple#person28")
("http://franz.com/simple#person13" "http://franz.com/simple#person31")
("http://franz.com/simple#person13" "http://franz.com/simple#person25")
("http://franz.com/simple#person13" "http://franz.com/simple#person62")
("http://franz.com/simple#person13" "http://franz.com/simple#person56")
("http://Франц.com/simple#person13" "http://franz.com/simple#person42")
("http://franz.com/simple#person13" "http://franz.com/simple#person47")
("http://franz.com/simple#person13" "http://franz.com/simple#person51")
...)  com/simple#person13" "http://franz.com/simple#person33")
("http://franz.com/simple#person13" "http://franz.com/simple#person26")
("http://franz.com/simple#person13" "http://franz.com/simple#person28")
("http://franz.com/simple#person13" "http://franz.com/simple#person31")
("http://franz.com/simple#person13" "http://franz.com/simple#person25")
("http://franz.com/simple#person13" "http://franz.com/simple#person62")
("http://franz.com/simple#person13" "http://franz.com/simple#person56")
("http://Франц.com/simple#person13" "http://franz.com/simple#person42")
("http://franz.com/simple#person13" "http://franz.com/simple#person47")
("http://franz.com/simple#person13" "http://franz.com/simple#person51")
...)
com/simple#person13" "http://franz.com/simple#person33")
("http://franz.com/simple#person13" "http://franz.com/simple#person26")
("http://franz.com/simple#person13" "http://franz.com/simple#person28")
("http://franz.com/simple#person13" "http://franz.com/simple#person31")
("http://franz.com/simple#person13" "http://franz.com/simple#person25")
("http://franz.com/simple#person13" "http://franz.com/simple#person62")
("http://franz.com/simple#person13" "http://franz.com/simple#person56")
("http://Франц.com/simple#person13" "http://franz.com/simple#person42")
("http://franz.com/simple#person13" "http://franz.com/simple#person47")
("http://franz.com/simple#person13" "http://franz.com/simple#person51")
...) В Allegro Prolog есть еще одно удобное сокращение. Часто бывает необходимо использовать небольшие фрагменты кода на Лиспе внутри ряда предложений Пролога. Вот типичный пример, когда необходимо внутри последовательности предложений Prolog получить значение из окружающей среды Lisp. Здесь мы определяем функцию Лиспа, которая возвращает имя и фамилию каждого человека, родившегося в указанный год.
Здесь мы определяем функцию Лиспа, которая возвращает имя и фамилию каждого человека, родившегося в указанный год.
> (по определению год рождения (год)
(select0 (?имя ?фамилия)
(шепелявый ?год (буквальный (принц-строковый год)))
(q- ?человек !ex:год рождения ?год)
(q- ?человек !ex:имя ?имя)
(q- ?человек !ex:фамилия ?фамилия)))
год рождения
> (1915 года рождения)
(({Джозеф} {Кеннеди}) ({Роберт} {Шрайвер}))
т
Аргумент year может быть строкой или целым числом, но нам нужно преобразовать его в строку, так как именно так хранятся годы рождения в этой конкретной базе данных.Тогда аргумент должен быть интернирован как литерал. Но важным моментом является то, что нам нужно получить значение year из окружения Lisp и связать его с переменной Prolog (здесь она называется ?year ), чтобы ее можно было передать в q-.
Эта необходимая передача данных в среду Prolog загромождает код и затрудняет его чтение.
?? Синтаксический маркер может устранить многое из этого:
> (по определению год рождения (год)
(select0 (?имя ?фамилия)
(q- ?человек !ex:год рождения (?? (буквальный (принц-в-строку год))))
(q- ?человек !ex:имя ?имя)
(q- ?person !ex:last-name ?last-name))) Это не что иное, как синтаксическая стенограмма предыдущего примера, и работает точно так же.Это устраняет необходимость в том, чтобы переменная Prolog была видимой. Тело ?? имеет синтаксис, подобный Lisp progn , и заменяет во время выполнения значение, вычисленное телом progn , в предложение Prolog.
Другой полезный предикат Prolog — , необязательный . При обертывании конкатенации предложений это позволяет этой конкатенации быть успешным столько раз, сколько это было бы успешно, если бы эти предложения были просто последовательно в этом месте. Однако, если объединение не удалось хотя бы один раз, необязательный предикат завершается успешно один раз без установления каких-либо новых привязок переменных.
Например, если некоторые люди в нашей базе данных не имеют данных об именах, наш предыдущий предикат рождения-в-годе не найдет этих людей. Мы могли бы улучшить это и вернуть nil для неизвестных имен:
> (по определению год рождения (год)
(select0 (?имя ?фамилия)
(q- ?человек !ex:год рождения (?? (буквальный (принц-в-строку год))))
(необязательно (q- ?человек !ex:имя ?имя))
(q- ?человек !ex:фамилия ?фамилия)))
Проблема с использованием ! в коде Пролога
Существует конфликт между синтаксисом сокращения Пролога (описанным в Руководстве по Прологу Allegro) и нотацией будущей части AllegroGraph (см. здесь).Пролог использует восклицательный знак ! для обозначения предиката cut. При выполнении разрез очищает все предыдущие точки возврата в вызове текущего предиката. Например,
> (<-- (родительский ?x)
(родитель ?х ?)
!) определяет предикат, который проверяет, является ли аргумент person родителем, но если да, то только один раз. (Если существует несколько правил для
(Если существует несколько правил для parent/1 ! , то выполняется полное сокращение до выбора текущего правила.) ! — это традиционная запись Пролога, но AllegroGraph использует ! символов в качестве макроса чтения для создания будущей детали, поэтому приведенное выше определение будет сигнализировать об ошибке чтения, когда действует таблица чтения AllegroGraph (см. раздел макросов !-reader).
Самый простой способ решить эту проблему — ввести предисловие к Прологу ! с обратной косой чертой в любом коде, который может быть прочитан с действующей таблицей чтения AllegroGraph. Обратная косая черта подавляет любой макрос чтения для следующего символа.Это минимизирует беспорядок в исходном коде и совершенно безвредно, даже если таблица чтения AllegroGraph не действует.
> (<-- (является-родителем ?x)
(родитель ?х ?)
\!)
Изучите программирование на Прологе от нуля до героя
Вы только что наткнулись на наиболее полный и углубленный онлайн-курс по программированию на Прологе .
Желаете ли вы:
- развить навыки, необходимые для получения вашей первой работы по программированию на Прологе
- перейти на более старшую должность разработчика программного обеспечения
- стать специалистом по информатике, освоив вычисления
- или просто изучить Пролог чтобы иметь возможность быстро создавать свои собственные приложения Prolog.
...этот полный мастер-класс по Прологу - это курс, который вам нужен, чтобы сделать все это, и многое другое.
Этот курс разработан, чтобы дать вам навыки Prolog, необходимые для того, чтобы стать разработчиком Prolog. К концу курса вы будете очень хорошо понимать Prolog и сможете создавать свои собственные приложения Prolog и работать продуктивно в качестве компьютерного ученого и разработчика программного обеспечения.
Что делает этот курс бестселлером?
Как и вы, тысячи других были разочарованы и сыты по горло разрозненными учебными пособиями на Youtube или неполными или устаревшими курсами, которые предполагают, что вы уже знаете кучу вещей, а также толстыми, похожими на колледж учебниками, способными отправить даже самый кофеин- уложил кодера спать.
Как и вы, они устали от некачественных уроков, плохо объясненных тем и запутанной информации, представленной в неправильном виде. Вот почему так много людей добиваются успеха в этом полном курсе для разработчиков Prolog. Он разработан с учетом простоты и плавного продвижения по содержанию.
Этот курс предполагает отсутствие предыдущего опыта программирования и знакомит вас с основными понятиями для начинающих. Вы изучите основные навыки работы с Prolog и освоите логическое программирование. Это универсальный магазин для изучения Пролога.Если вы хотите выйти за рамки основного контента, вы можете сделать это в любое время.
Вот лишь часть того, что вы узнаете
(Ничего страшного, если вы еще этого не понимаете, вы поймете в ходе курса)
Все основные ключевые слова Пролога, факты, отношения, аргументы и выражения, необходимые для полного понимания того,
что именно вы кодируете и для чего, что делает программирование простым для понимания и менее утомительным.Вы узнаете ответы на такие вопросы, как Что такое база данных Prolog, Что такое правила и модели и как применять их к своим приложениям Prolog.
Функции и основная структура экспертных систем , а также работа с неопределенностью и представлением знаний.

Что делать, если у меня есть вопросы?
Поскольку этот курс был недостаточно полным, я предлагаю полную поддержку , отвечая на любые ваши вопросы 7 дней в неделю (в то время как многие инструкторы отвечают только раз в неделю, или вообще не отвечают ).
Это означает, что вы никогда не застрянете на одном уроке на несколько дней подряд.Под моим руководством вы пройдете этот курс плавно, без каких-либо серьезных препятствий.
Риска тоже нет!
К этому курсу предоставляется полная 30-дневная гарантия возврата денег . Это означает, что если вы не полностью удовлетворены курсом или своим прогрессом, просто дайте мне знать, и я верну вам 100%, до последней копейки, без вопросов.
Это означает, что если вы не полностью удовлетворены курсом или своим прогрессом, просто дайте мне знать, и я верну вам 100%, до последней копейки, без вопросов.
Вы либо приобретете навыки Пролога, продолжите разработку отличных программ и, возможно, сделаете потрясающую карьеру для себя, либо вы попробуете курс и просто вернете все свои деньги, если он вам не понравится…
Вы буквально не могу проиграть.
Готовы начать, разработчик?
Зарегистрируйте сейчас , нажав кнопку «Добавить в корзину» справа, и начните свой путь к творческому расширенному совершенству Prolog. Или пройдите этот курс бесплатно, используя функцию предварительного просмотра, чтобы вы были на 100% уверены, что этот курс для вас.
Увидимся внутри (спешите, Пролог ждет!)
Вы слышали о Прологе?. Краткий обзор этого малоизвестного… | Фернандо Доглио
Поверьте мне, Пролог все еще используется, просто не так широко, как некоторые из наиболее часто используемых языков в нашей отрасли, и для этого есть очень веская причина. Но прежде чем углубиться в это, позвольте мне быстро объяснить, что такое Пролог, если вы еще не сталкивались с ним.
Но прежде чем углубиться в это, позвольте мне быстро объяснить, что такое Пролог, если вы еще не сталкивались с ним.
Что такое Пролог?
Пролог — это язык логического программирования, что по существу означает, что он написан декларативным способом (в отличие от использования императивного подхода, доступного в других распространенных языках). Вы используете отношения, факты и правила для описания своей бизнес-логики, а затем просто запрашиваете данные по этим фактам.
Это, безусловно, другой способ работы, но вы можете узнать (если достаточно углубитесь в Пролог), что он действительно упрощает решение некоторых задач.
С Прологом вы начинаете с определения желаемого состояния вашего мира, также известного как Предикат (факт), а затем просите Пролог попытаться достичь этого состояния.
Например, давайте поиграем. Представьте, что у вас есть эти магические числа: 1 , 2 , 4 и 5 . Вы хотите иметь возможность найти все решения для простой операции «сложения», используя два из этих чисел. Подумайте об этом так:
Подумайте об этом так:
Дано 1 — магическое число
Дано 2 — магическое число
Дано 4 — магическое число
Дано 5 — магическое число Какие числа можно сложить, чтобы получить 6?
Конечно, мы читаем эти утверждения и можем решить их в уме, но если вы хотите реализовать это на одном из самых «распространенных» языков, вам придется реализовать какой-то алгоритм, который будет проверять все возможные пары, оценивать их результаты и оставить только те, которые совпадают.
Однако на Прологе решение состоит в том, что псевдокод, который я только что написал, просто записан другими словами: X), magicNumber(Y), plus(X, Y, 6)
Эти первые несколько строк идентичны тому, что я говорю, какие из них являются «магическими числами», а затем вы просто указываете, «Учитывая мои магические числа, на переменные X и Y , какие из них я могу использовать, учитывая, что вместе они дадут в сумме 6 ?»
Результат:
1, 5
2, 4
5, 1
4, 2
Мы можем продолжать усложнять вещи, чтобы избежать повторяющихся решений, но это должно быть достаточно сложно, чтобы дать вам представление о силе логического программирования. Требуется некоторое время, чтобы понять это, так как вы не решаете проблему . Вы только устанавливаете правила своего мира (т. е. какие числа являются магическими), а затем указываете желаемое решение. Средний шаг, который вы все время думаете о реализации, выполняется движком.
Требуется некоторое время, чтобы понять это, так как вы не решаете проблему . Вы только устанавливаете правила своего мира (т. е. какие числа являются магическими), а затем указываете желаемое решение. Средний шаг, который вы все время думаете о реализации, выполняется движком.
Ознакомьтесь с этими примерами, если хотите продолжить чтение об этом. Они очень интересные.
Теперь рассмотрим эту силу. Как вы можете использовать это и почему вы еще этого не сделали?
Где Prolog действительно сияет прямо сейчас?
Я понимаю, как вы можете видеть это и считать его бесполезным для вашей повседневной жизни, особенно если вы фронтенд-разработчик или разрабатываете инструменты автоматизации в Node.js. Это справедливо, и не каждый язык предназначен для использования в каждом сценарии. Мы все это знаем. Тем не менее, — это место, где этот тип логического программирования работает и работает отлично: сопоставление с образцом.
Одной из ключевых областей внутри ИИ является понимание того, как использовать сопоставление с образцом, если вы пытаетесь понять естественный язык, и именно здесь сияет Prolog. Имейте в виду, внутри ИИ есть множество других ключевых областей. Я просто утверждаю, что Пролог очень полезен внутри одного из них.
Имейте в виду, внутри ИИ есть множество других ключевых областей. Я просто утверждаю, что Пролог очень полезен внутри одного из них.
Итак, принимая во внимание этот факт, где сияет Пролог? Где бы вы могли его использовать, если бы захотели? Хорошо, если вы имеете дело с такими проблемами, как планирование (которое, если вы еще не пробовали, решить довольно сложно), проверка цифровых цепей, управление трафиком или любой другой тип логического программирования ограничений в вашей повседневной жизни день, то вы можете взглянуть на него.
В частности, для ИИ, если вы занимаетесь программированием наборов ответов или НЛП (как в обработке естественного языка), Пролог также очень полезен.Приводить вам пример того, как это может выглядеть, может быть слишком много для такой статьи, учитывая требуемую глубину знаний, и, поскольку я не эксперт по Прологу, я бы попросил вас просто довериться мне в этом. Если мне удалось заинтересовать вас, посмотрите несколько примеров.
Кто тогда на самом деле использует Prolog?
Мы ведь хотим ответить на этот вопрос, не так ли?
Учитывая данные, представленные до сих пор, можно с уверенностью предположить, что существуют группы, использующие Prolog, но они не так широко известны всем из-за того, что их поле не является общедоступным. И даже если их проекты известны, они не кричат везде, что они использовали Пролог для его создания, поскольку Пролог обычно является небольшой частью целого. Тем не менее, рассмотрите следующие примеры:
И даже если их проекты известны, они не кричат везде, что они использовали Пролог для его создания, поскольку Пролог обычно является небольшой частью целого. Тем не менее, рассмотрите следующие примеры:
- TerminusDB: это модельно-управляемая RDF-база данных с контролем версий, способная обеспечить многие функции и поведение Git для управления версиями, но для больших наборов данных. Он предоставляет стандартный RESTful API, который позволяет вам взаимодействовать с ним.
- Уотсон из IBM: Верно, один из флагманских проектов IBM также использует Prolog внутри компании. Конечно, он не был построен исключительно на Прологе, как TerminusDB, но использует его. Как вы можете знать или не знать, Watson предназначен для помощи экспертам-людям, позволяя вам запрашивать конкретную информацию или отвечать на простые вопросы. Он попал в прессу, когда лихо победил главных чемпионов известного телешоу под названием Jeopardy . Команда IBM использовала Prolog для анализа естественного языка и перевода вопросов, задаваемых людьми, в форму, удобную и понятную для Watson.
- GeneXus: эта платформа разработки с низким кодом использует Prolog для преобразования и перевода желаемых функций в код (она генерирует код для вас). Он может генерировать код на многих языках, включая Java, Ruby, C#, Objective-C и других.

Как вы можете видеть, существует целый ряд вариантов использования, если вы посмотрите на продукт в целом, но Пролог, являясь лишь частью этих систем, может очень помочь для набора очень трудно решаемых задач. .
Имейте в виду, если вы заглянете на GitHub и выполните быстрый поиск по прологу, вы заметите, что существует более 7000 репозиториев, которые утверждают, что Пролог является одним из их языков, поэтому многие пытаются его использовать.Проблема (на мой взгляд) в том, что немногие из них смогли создать успешные коммерческие продукты, сделавшие их хорошо известными (или даже известными) публике.
Введение в Prolog — документация 383summer2019
Что такое Пролог?
Пролог — это язык логического программирования, разработанный в начале
1970-х годов, посвященных объектам и отношениям между объектами. Он стремится быть
декларативный язык программирования, т.е. Prolog
программы часто просто говорят что они будут делать без точного указания как они сделают это.Пролог имеет встроенный поиск с возвратом, который может решить
почти любая проблема (если у вас есть достаточно времени — наивные программы на Прологе
может быть довольно медленным!). Другими примерами декларативных языков являются SQL, регулярные выражения и HTML.
Он стремится быть
декларативный язык программирования, т.е. Prolog
программы часто просто говорят что они будут делать без точного указания как они сделают это.Пролог имеет встроенный поиск с возвратом, который может решить
почти любая проблема (если у вас есть достаточно времени — наивные программы на Прологе
может быть довольно медленным!). Другими примерами декларативных языков являются SQL, регулярные выражения и HTML.
Хотя Пролог не был коммерчески успешным языком, он некоторые распространенные приложения, такие как:
- Грамматика для обработки естественного языка. Например, IBM Watson. система использовала Пролог (среди другие языки), чтобы помочь ему ответить на вопросы естественного языка.
- приложений ИИ, основанных на логике или знаниях. Пролог имеет хороший поддержка логики предикатов первого порядка. Например, Пролог был основным язык для японского компьютерного проекта пятого поколения в 1980-х годах.
- Базы данных в оперативной памяти. Пролог можно использовать как язык для создания и
запросы, сложные базы данных внутри других языков. Нередко вариации
Пролог используется для такого рода приложений, например. Datomic — это база данных, использующая Prolog-подобный
язык данных для записи
запросы.
- Проблемы, которые требуют какого-либо возврата, например, планирование или проблема расписания из логистики, часто может быть красиво представлена и решается на Прологе.
 Пролог можно использовать как язык для создания и
запросы, сложные базы данных внутри других языков. Нередко вариации
Пролог используется для такого рода приложений, например. Datomic — это база данных, использующая Prolog-подобный
язык данных для записи
запросы.
Пролог можно использовать как язык для создания и
запросы, сложные базы данных внутри других языков. Нередко вариации
Пролог используется для такого рода приложений, например. Datomic — это база данных, использующая Prolog-подобный
язык данных для записи
запросы.Хотя Пролог можно использовать как язык программирования общего назначения, он не очень популярен для этого, поскольку его синтаксис и семантика незнакомы большинству программистов, и может быть довольно сложно писать эффективные программы (даже для некоторые распространенные проблемы программирования). Кроме того, у него нет стандарта. реализация объектов или модулей (важных в масштабных программная инженерия).
Несмотря на отсутствие коммерческого успеха, Пролог был влиятельным
язык, который стимулировал множество исследований в области языков программирования.
Обзор Пролога
Многое из того, что следует далее, основано на книге «Программирование на Прологе» автора Clocksin. и Меллиш. Это хорошая книга, если вы хотите научиться еще Пролог.
Хороший способ думать о Прологе состоит в том, что он примерно реляционный. программирование . В математике отношение — это набор кортежей.Например, если \(A\) и \(A\) множества, то отношением является любое подмножество их перекрестный продукт:
\[A \times B = \{(a, b) : a \in A, b \in B \}\]
В более общем случае, если \(A_1, A_2, \ldots, A_n\) непустые множества, то отношением к ним является любое подмножество этого перекрестного произведения:
\[A_1 \times A_2 \times \ldots \times A_n = \{(a_1,a_2,\ldots,a_n) : a_1\in A_1, a_2\in A_2, \ldots, a_n \in A_n \}\]
\((a_1,a_2,\ldots,a_n)\) является n-кортежем, т.е. упорядоченным набором n разные значения.Отношение — это просто набор из 0 или более n-кортежей
Например, предположим, что множество \(A=\{18,19,20\}\) и множество
\(P=\{\textrm{yi}, \textrm{veronica}, \textrm{pat}, \textrm{gary}\}\). Мы
Затем можно было бы определить отношение age следующим образом:
\(\{(\textrm{veronica},19), (\textrm{pat},19), (\textrm{yi},18)\}\). Этот
отношение - это просто набор пар, где первый элемент каждой пары из
\(A\), а второй элемент из
\(П\). Другим отношением будет \(\{(\textrm{yi},19),
(\textrm{yi},20), (\textrm{yi},18)\}\); нет требования, чтобы все значения
из \(A\) или \(P\).
Мы
Затем можно было бы определить отношение age следующим образом:
\(\{(\textrm{veronica},19), (\textrm{pat},19), (\textrm{yi},18)\}\). Этот
отношение - это просто набор пар, где первый элемент каждой пары из
\(A\), а второй элемент из
\(П\). Другим отношением будет \(\{(\textrm{yi},19),
(\textrm{yi},20), (\textrm{yi},18)\}\); нет требования, чтобы все значения
из \(A\) или \(P\).
Отношения оказались очень мощным способом осмысления вычислений. Например, рассмотрим это отношение на \(A \times A \times B\), где \(A=\{1,2,3\}\) и \(B=\{1,2,3,4,5,6\}\):
х у г ===== 1 1 2 1 2 3 1 3 4 отношение x + y = z 2 1 3 2 2 4 2 3 5 3 1 4 3 2 5 3 3 6
Для \(x\) и \(y\) \(\{1,2,3\}\) эта таблица содержит все возможные суммы. Теперь мы можем использовать эту таблицу, чтобы ответить на различные вопросы. За пример:
- Является ли \(2 + 1 = 3\)? Чтобы ответить на этот вопрос, ищем в таблице тройку
\((2,1,3)\).Он есть в таблице, и поэтому мы знаем, что \(2 + 1 = 3\) равно
истинный. Точно так же мы знаем, что \(2 + 2 = 1\) равно , а не , потому что
тройка \((2,2,1)\) отсутствует в таблице.
- Что такое \(x\) в уравнении \(x + 1 = 4\)? Чтобы решить это, у нас есть найти тройку, соответствующую \((x,1,4)\); мы видим, что есть только одна такая тройка, \((3,1,4)\), и так в этом уравнении \(x=4\).
- Какие значения \(x\) и \(y\) удовлетворяют \(x + y = 4\)? Мы тут нужно найти тройки, соответствующие \((x,y,4)\).Таких троек две в таблице: \((1,3,4)\) и \((3,1,4)\), поэтому уравнение имеет два разных решения: \(x=1\) и \(y=3\) или \(x=3\) и \(у=1\).
 Точно так же мы знаем, что \(2 + 2 = 1\) равно , а не , потому что
тройка \((2,2,1)\) отсутствует в таблице.
Точно так же мы знаем, что \(2 + 2 = 1\) равно , а не , потому что
тройка \((2,2,1)\) отсутствует в таблице.Здесь интересно то, что мы преобразовали задачу решения уравнения для поиска кортежей в таблице. И это по сути то, что Пролог делает: он предоставляет способ использовать отношения для вычислений.
Структура программы на языке Пролог
Программы на большинстве языков программирования состоят из таких функций, как функции, переменные и модули.Пролог немного отличается, и его программа состоят из трех основных вещей:
- Факты об объектах и их отношениях. Объекты Prolog имеют номер , а не .
объекты в смысле объектно-ориентированного программирования, но объекты в
чувство логики. Объект может быть любым значением, например. число, строка,
список и т. д. Отношения между объектами рассматриваются как логические предикаты.
как в квантифицированной логике первого порядка.
- Правила об объектах и их отношениях.Например, у вас может быть правило «если X и Y имеют одних и тех же родителей, то они братья и сестры».
- Вопросы , которые можно задать об объектах и их отношениях. Эти аналогичны запросам в системе баз данных.
 Объекты Prolog имеют номер , а не .
объекты в смысле объектно-ориентированного программирования, но объекты в
чувство логики. Объект может быть любым значением, например. число, строка,
список и т. д. Отношения между объектами рассматриваются как логические предикаты.
как в квантифицированной логике первого порядка.
Объекты Prolog имеют номер , а не .
объекты в смысле объектно-ориентированного программирования, но объекты в
чувство логики. Объект может быть любым значением, например. число, строка,
список и т. д. Отношения между объектами рассматриваются как логические предикаты.
как в квантифицированной логике первого порядка.Факты и правила вместе образуют то, что часто называют базой знаний . Часто написание программы на Прологе состоит из создания (иногда очень сложная!) база знаний, а также запросы к этой базе знаний.
Запуск Пролога
Для начала загрузите и установите SWI-Prolog.Вы запускаете его в командной строке, набрав пролог :
$ пролог Добро пожаловать в SWI-Prolog (многопоточный, 32-битный, версия 7.
 2.3)
Авторское право (c) 1990-2015 Амстердамский университет, VU Amsterdam
SWI-Prolog поставляется АБСОЛЮТНО БЕЗ ГАРАНТИЙ. Это бесплатное программное обеспечение,
и вы можете распространять его при определенных условиях.
Пожалуйста, посетите http://www.swi-prolog.org для получения подробной информации.
Для справки используйте ?-help(Тема). или ?- по поводу (Word).
?-
2.3)
Авторское право (c) 1990-2015 Амстердамский университет, VU Amsterdam
SWI-Prolog поставляется АБСОЛЮТНО БЕЗ ГАРАНТИЙ. Это бесплатное программное обеспечение,
и вы можете распространять его при определенных условиях.
Пожалуйста, посетите http://www.swi-prolog.org для получения подробной информации.
Для справки используйте ?-help(Тема). или ?- по поводу (Word).
?-
?- является подсказкой интерпретатора Пролога и означает, что он ждет вас
утверждать факт или правило или задавать ему вопрос.
Предположим, у вас есть файл с именем intro.pl с таким содержимым:
% intro.pl любит(Джон, Мэри). % факт, утверждающий, что Джону нравится Мэри
Этот файл содержит один факт, лайков (Джон, Мэри). , что мы можем
интерпретировать как означающее «Джон любит Мэри». % отмечает начало одной строки
комментарий к исходному коду.
Теперь давайте загрузим intro.pl в интерпретатор Пролога (используя [ и ] ), и задайте несколько вопросов:
?- [вступление].
 % вступление скомпилировано 0.00 сек, 2 пункта
истинный.
?- нравится(Джон, Мэри).
истинный.
?- нравится(мэри, джон).
ложный.
?- нравится(Джон, Iron_man).
ложный.
% вступление скомпилировано 0.00 сек, 2 пункта
истинный.
?- нравится(Джон, Мэри).
истинный.
?- нравится(мэри, джон).
ложный.
?- нравится(Джон, Iron_man).
ложный.
Наша программа утверждает , что это факт, что джон любит мэри , и поэтому
когда мы задаем ему «вопрос» лайков (джон, мэри). , возвращает true .
Когда мы спрашиваем, любит ли мэри джон , то есть лайков(мэри, джон). ,
Prolog возвращает false , потому что это не тот факт, который он знает или может вывести.
Третий вопрос, лайка(john, iron_man). , интересно на пару
причины. Объект iron_man нигде не упоминается в intro.pl .
Вы можете предположить, что это вызовет ошибку, но в данном случае это не проблема.
пример. Поскольку Пролог не может доказать, что Джону нравится iron_man, он заключает, что
Джон не любит iron_man.
Но это довольно агрессивный вывод: точнее, мы просто не
знать, нравится ли Джону iron_man, потому что мы ничего не знаем о
тот. Так что более точным ответом будет: «Я не знаю, нравится ли Джону
Железный человек". Но Пролог этого не делает: если Пролог не может доказать, что что-то
верно, предполагается, что оно ложно.
Так что более точным ответом будет: «Я не знаю, нравится ли Джону
Железный человек". Но Пролог этого не делает: если Пролог не может доказать, что что-то
верно, предполагается, что оно ложно.
Факты
Давайте посмотрим на факт подробнее:
Указывает связь между двумя объектами: объектом john и
объект mary находится в отношениях нравится .
Обратите внимание на следующее:
- Имена связей и объектов должны начинаться с строчной буквы .В Прологе заглавные буквы являются переменными.
- Имя отношения часто называют предикатом , т.е.
нравитсяявляется предикатом. - Предикат
нравитсяявляется двоичным , т. е. имеет арность 2. Он имеет два аргументы ,ДжониМэри. - В общем порядок аргументов имеет значение, т.е.
лайков(джон, мэри).это не тот же факт, что инравится(мэри, джон). - Имена объектов, такие как
johnиmary, аналогичны символам в Лисп. Это , а не строки. Все, что мы можем сделать, это проверить, являются ли два объекта одинаковые или разные — мы не можем получить доступ к их отдельным персонажам. - Символ точки
.всегда должно стоять в конце факта.

Вот еще несколько примеров фактов:
жир(гомер). % гомер толстый мужчина (Гомер). % Гомер мужчина Отец_из (Гомер, Барт).% гомер отец барта ногами (зуд, колючий). % чешется колючий украл (барт, пончик, гомер). % Барт украл пончик у Гомера
Мы часто называем список фактов базой данных или базой знаний . ( КБ ). В самом деле, как вы увидите, Пролог во многом похож на система реляционных баз данных.
Используемые здесь имена не имеют специального значения в Прологе и могут было написано так:
а(б). в(б).г(б, д). f(g, h). i(e,j,b).

Конечно, это гораздо труднее читать!
Упражнение. Переведите каждый из следующих фактов на Пролог. Использовать английский слова и имена, чтобы их было легко читать.
- Золото ценно.
- Вода мокрая.
- Эмили поцеловала Томаса.
- Джими поцеловал небо.
- Мистер Шепот заснул на диване.
- Рэнди украл книгу у Стэна и отдал ее Кайлу.
Решения.
-
ценный(золото). -
влажный (вода). -
поцеловал(Эмили, Томас). -
поцеловал(джим, the_sky). -
заснул(mr_whiskers, диван).; илиупал_уснул_на_диван(mr_whiskers). -
украл(рэнди, книга, стэн, кайл).
вопросов
Имея базу знаний, мы можем задавать вопросы о ней, т. е. запрашивать ее. За пример:
?- нравится(Джон, Мэри).истинный
Здесь лайка(Джон, Мэри). интерпретируется как вопрос «Нравится ли Джону
Мэри?".
Пролог отвечает на вопросы, ища факты в своей базе знаний, чтобы увидеть
если они соответствуют вопросу. Если это так, возвращается true ; если нет, ложь есть
вернулся. Мы будем говорить, что запрос следует за , когда он возвращает истину, и терпит неудачу , когда возвращает false.
Пролог использует алгоритм, называемый объединением , для сопоставления.Два факта говорят, что объединяют , если они имеют одинаковое имя предиката, одинаковое количество аргументы, и те же аргументы в той же позиции.
Так, например, лайков(джон, мэри) и лайков(джон, мэри) объединяются, в то время как нравится(Джон, Мэри) и нравится(Мэри, Джон) нет.
Переменные
Мы часто хотим задать вопросы в форме «Кого любит Джон?» или «Кто
нравится Джон?». Чтобы иметь дело с «Кто» в этих вопросах, нам нужно ввести
переменные.
Чтобы иметь дело с «Кто» в этих вопросах, нам нужно ввести
переменные.
Переменные в Прологе называются логическими переменными , и они отличаются чем переменные в других языках программирования:
Все переменные Prolog должны начинаться с заглавной буквы. Например,
X,WhoиJohnявляются примерами переменных Пролога, аx,whoиjohn— неизменяемые объекты.Переменная Пролога является либо инстанцированной , либо неконкретизированной .Ан конкретизированная переменная имеет некоторое значение, связанное с ней, в то время как неэкземплярная переменная не имеет связанного с ней значения.
В большинстве других языков программирования переменные всегда связаны с какое-то значение. Мы можем не знать, какова ценность, но она всегда есть.
Предположим, наша база знаний состоит из следующих фактов:
лайка(Джон, Мэри).
 любит(мэри, катание на лыжах).
любит(Джон, катание на лыжах).
любит(Джон, цветы).
нравится(мэри, сюрпризы).
любит(мэри, катание на лыжах).
любит(Джон, катание на лыжах).
любит(Джон, цветы).
нравится(мэри, сюрпризы).
Мы можем использовать переменную в таком вопросе:
?- нравится(Джон, Х).% Что нравится Джону? Х = Мэри; % типов пользователей; Х = катание на лыжах; % типов пользователей; Х = цветы.
Возвращенный результат верен для базы знаний: john лайков Мэри , лыжи и цветы . После того, как Пролог находит соответствие
присвоение для X , он останавливается и отображает то, что он нашел. Затем пользователь
имеет возможность остановить программу, набрав . или, набрав ; по
пусть Пролог откатывается и пытается найти другое значение, удовлетворяющее X .В
в этом примере пользователь набрал ; после каждого значения для X , чтобы получить
следующий результат.
Когда Prolog впервые видит вопрос, лайков (john, X). переменная 
X не конкретизированный, то есть он не имеет связанной с ним ценности. Когда
неэкземплярная переменная появляется как аргумент предиката, Пролог позволяет это
переменная унифицирует с любое значение в той же позиции для предиката с
то же имя.
Чтобы ответить на вопрос лайков(джон, X). Пролог просматривает свои
базу знаний, чтобы увидеть, какие факты, если таковые имеются, объединяются с лайками (Джон, Х). Вы
мог представить, что поиск будет выглядеть так:
- Можно
лайков(Джон, Х).объединяются слайками (Джон, Мэри).? Да можно, еслиХ = Мэри. - Можно
лайков(Джон, Х).объединить слайками(мэри, лыжи).? Нет, нет возможное значение, которое можно присвоитьX, что дастлайков(джон, ИКС).то же, что илайков(мария, лыжи).. - Можно
лайков(Джон, Х).объединить слайками(Джон, лыжи).? Да можно, если X = катание на лыжах. - Можно
лайков(Джон, Х).объединяются слайками (джон, цветы).? Да можно, еслиX = цветы. - Можно
лайков(Джон, Х).объединяются слайками (мэри, сюрпризы).? Нет, есть нет возможного значения, которое можно присвоитьX, что сделаетлайков(джон, ИКС).то же, что и ``лайки(мэри, сюрпризы)``.

Когда Prolog успешно объединяет факт, он внутренне помечает место в
базу знаний, где произошло объединение, чтобы потом можно было
вернитесь к этой точке и попытайтесь найти другое совпадение. Когда пользователь вводит ; , который указывает Прологу продолжить поиск, начав сразу после
то что было просто унифицировано. Если вместо этого пользователь вводит . , он говорит
Пролог для немедленной остановки поиска.
Вот еще пример:
?- нравится(Х, лыжи).
 % Кто любит кататься на лыжах?
Х = Мэри;
Х = Джон.
% Кто любит кататься на лыжах?
Х = Мэри;
Х = Джон.
И еще:
?- нравится(надин, X). % Что любит Надин? ложный.
Никакие факты в нашей базе знаний не соответствуют этому вопросу, поэтому ложь вернулся.
Вот вопрос с двумя переменными:
?- нравится(X,Y). % Что нравится людям? Х = Джон, Y = Мэри; % пользователь вводит все ; символы Х = Мэри, Y = катание на лыжах; Х = Джон, Y = катание на лыжах; Х = Джон, Y = цветы; Х = Мэри, Y = сюрпризы.
Сравните это с этим:
?- нравится(X, X). % Кто любит себя? ложный.
Это означает, что в базе знаний нет факта, первый аргумент которого то же самое его второй аргумент.
Союзы
Еще один полезный тип вопросов включает в себя слово «и», например. «Джону нравится и Мэри, и катание на лыжах?». На Прологе мы можем написать такие вопросы следующим образом:
?- нравится(джон, мэри), нравится(джон, лыжи). истинный.
, означает «и», а возвращается true , так как оба факта находятся в
база знаний.
Все факты, разделенные числами , , должны быть объединены, чтобы вопрос
преуспевать. Так, например, это не удается:
?- нравится(джон, мэри), нравится(джон, сюрпризы). ложный.
Переменные и союзы можно комбинировать, чтобы задать несколько интересных вопросов. Например, «Что нравится Джону и Мэри?»:
.?- нравится(Джон, Х), нравится(Мэри, Х). Х = катание на лыжах; ложный.
Пролог пытается ответить на этот вопрос, сначала пытаясь объединить лайка(john,
Х) .Сначала он объединяется с фактом лайков (Джон, Мэри). и, следовательно, X =
Мэри . Затем Пролог проверяет вторую цель вопроса, лайков(мэри,
Х) . Здесь X имеет значение mary , так что это эквивалентно запросу лайков(мэри, мэри) , что не удалось.
В этот момент Пролог автоматически возвращает к точке, где
создано X . Он возвращается к лайкам(john, X) , отменяет X и
продолжает поиск в базе знаний с того места, где он был остановлен. Так
Так лайка(джон, X) затем объединяются с лайками(джон, катание на лыжах) , и, таким образом, X =
лыжи . Теперь он пытается удовлетворить лайков(mary, X) . Поскольку X имеет
значение катание на лыжах , это то же самое, что и запросить лайков(мэри, катание на лыжах) , то есть
истинный. Таким образом, вся конъюнкция истинна.
Если пользователь вводит ; после этого возвращается X , тогда Пролог сохраняет
поиск по базе знаний таким же образом, но не находит
больше совпадений, поэтому возвращает false .
Правила
Правилапозволяют нам кодировать такие вещи, как «Джон любит всех, кто любит вино». За пример:
лайка(Джон, Х):- лайков(Х, вино). % правило
:- в правиле Пролога означает «если». Слева от :- находится голова правила, а справа тело правила. Как с
факты, правило заканчивается на
Как с
факты, правило заканчивается на . .
Вот еще одно правило:
нравится(Джон, X):- нравится(X, вино), нравится(X, еда).% правило
Кодирует «Джону нравятся все, кто любит и еду, и вино». Или, эквивалентно, «Джону нравится X, если X любит вино и X любит еду».
Давайте рассмотрим более сложное правило. Мы будем использовать эту базу знаний:
кобель(боб). мужчина (дуг). жен.(вал). женщина (ада). родители (дуг, ада, боб). родители(вал, ада, боб).
Мы определяем правило сестра_из следующим образом:
сестра_из (X, Y): -
женщина (Х),
родители(X, Мать, Отец), % Мать и Отец пишутся с большой буквы,
родители (Y, Мать, Отец).% и поэтому они являются переменными
Кодирует правило «X — сестра Y, если X — женщина, а мать и отец X такой же, как мать и отец Y».
Теперь мы можем задавать такие вопросы:
?- сестра_из(вал, даг). истинный.
Поучительно проследить, как получают ответ на этот вопрос:
- Вопрос
сестра_оф(вал, дог).объединяется с головкой сестра_правила. - Следующий пролог пытается удовлетворить каждую цель в правиле
сестра_изв порядок им дан.ПосколькуXравноval, он проверяет, чтоfemale(val)правда. -
женский(val)является фактом в базе знаний, поэтому Пролог переходит к следующую цель в правиле и ищет первый факт, который объединяется сродители(вал, Мать, Отец). - Заглянув в базу знаний, мы видим, что есть только одно совпадение:
родителей(вал, ада, боб). Таким образом, на данный моментМатьимеет значениеadaиОтецимеет значениебоб. - Пролог теперь пытается объединить
родителей (Y, Мать, Отец)с фактом в база знаний. ПосколькуX- этоval,Y- этоdoug,Mother- этоada, аОтецравенбобу, Пролог проверяет, являются лиродителем (дуг, ada, bob)есть в базе знаний. И это так, поэтому Пролог возвращает верно. - Хотя мы этого не видим, Пролог на самом деле откатывает в этом правиле, чтобы увидеть
если есть другие способы удовлетворить его.Нет другого способа удовлетворить
родителей(doug, ada, bob), поэтому Пролог возвращается кродителям(val, Mother, Отец), чтобы узнать, есть ли в базе знаний какой-либо другой факт, который объединяется с ним. Нет, поэтому он снова возвращается кfemale(val), который не может быть унифицирован ни с чем другим. Таким образом, Пролог нашел один и единственный способ удовлетворить это правило.

 И это так, поэтому Пролог возвращает
И это так, поэтому Пролог возвращает Давайте попробуем еще вопрос:
?- сестра_из(значение, X). Х = Дуг; Х = знач.
Вопрос сестра_оф(вал, Х). спрашивает: «У кого есть сестра Вэл?» (или «Кто
братья и сестры Валя?). Как мы видим из результатов, он не возвращается совсем
правильный ответ. Он правильно определяет, что у Дага есть сестра Вэл, но
он также утверждает, что Вэл - ее родная сестра! Это явно не правильно, но наша
правило это позволяет.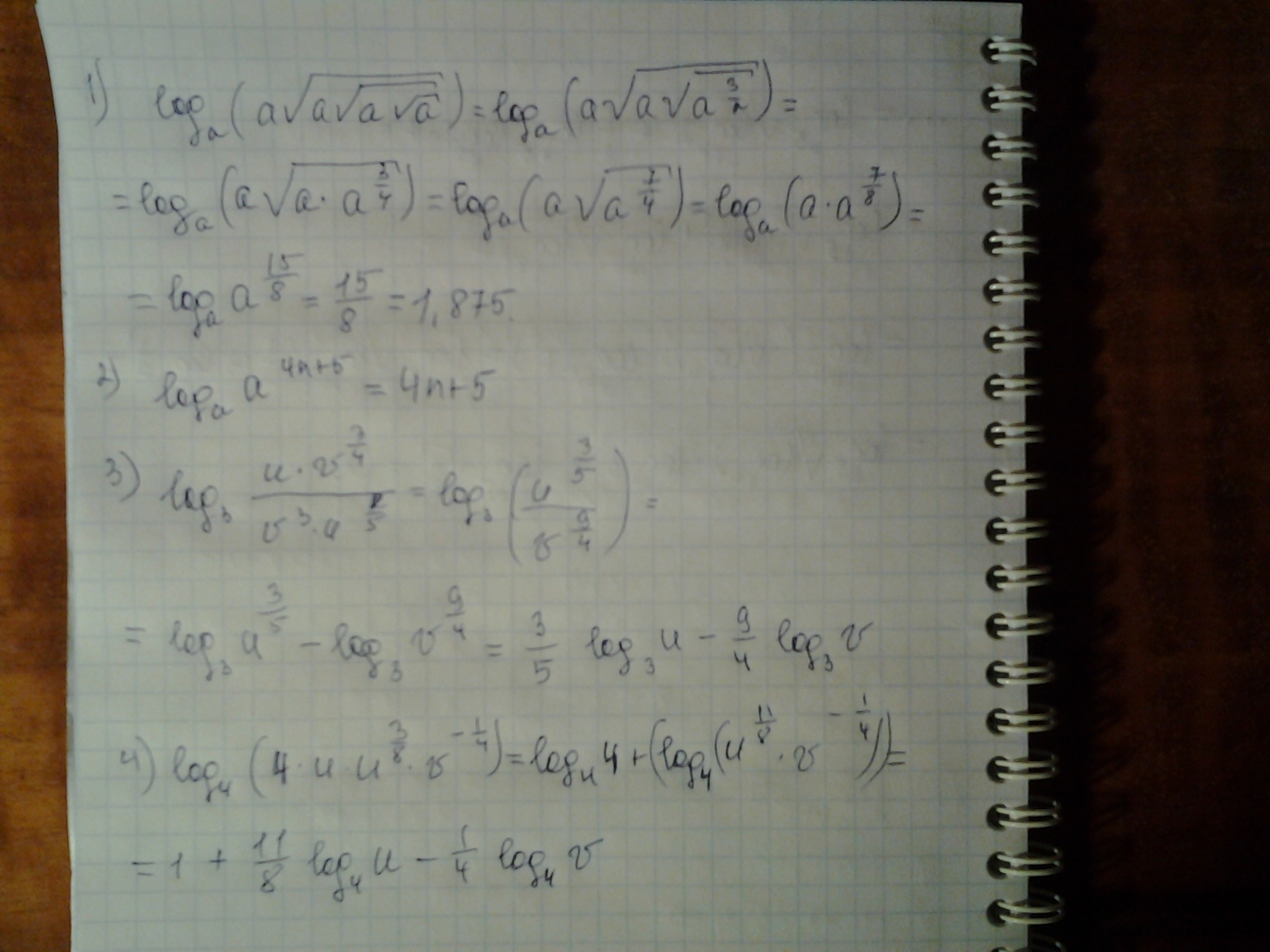 Давайте проследим это, чтобы понять, почему:
Давайте проследим это, чтобы понять, почему:
-
сестра_оф(вал, X)объединяется с главой правиласестра_оф,сестра_из(X, Y). Нам нужно быть осторожными с двумя переменнымиX. здесь.Xв заголовке правила присваиваетсяval, и так для остальных трассировки мы заменимXнаval.Xв вопрос в другом. Он объединяется с переменнойY. Мы говорим, чтоXиYявляются общими переменными, или что они кореферентны друг другу. Происходит следующее: как только одной из этих двух переменных присваивается значение, другая переменная немедленно получает то же значение. - Теперь Пролог проверяет отдельные цели в теле правила. Первое
один,
женщина(вал), преуспевает. - Следующий пролог пытается объединить
родителей (val, Mother, Father)и находит (единственное) совпадениеродителей (val, ada, bob). Теперь Мать— этоада, иОтецэтобоб. - Теперь Prolog пытается объединить
родителей (Y, ada, bob). Первый факт в база знаний, которая соответствует этому, составляетродителей (дуг, ада, боб).и такYполучает значениеdoug. ПеременнаяXиз вопроса ( неXв заголовке правила!) имеет то же значение, что иX, поэтому результат вопросаX = doug. - Если пользователь вводит
;, Пролог отступает и пытается найти другой решение. Пролог делает возврат, отменяя присвоение переменных в большинстве недавно достигнутая цель, т. е. он пытается найти еще один факт для объединенияродителей(Y, ada, bob)с.И есть такой факт в наших знаниях база:родители(вал, ада, боб). Таким образом,Yполучает значениеvalи, таким образом, общая переменнаяX(та, что в вопросе, а не в правиле head!) также получаетval. Вот как второй результат X = valнайден.
 Теперь
Теперь  Вот как второй результат
Вот как второй результат Интуитивно понятно, что проблема с правилом сестра_из заключается в том, что оно не указывает
что кто-то не может быть родной сестрой, т.е. нигде не сказано, что Х и Y должны отличаться.Так что мы могли бы исправить это так:
сестра_из (X, Y): -
женщина (Х),
родители (Х, Мать, Отец),
родители (Y, Мать, Отец),
Х \= У.
\= означает X \= Y успешно, только если X и Y не унифицируются с между собой, т.е. имеют разные значения:
?- сестра_из(значение, X). Х = Дуг; ложный.
В общем, получить правила, которые работают корректно во всех случаях, довольно сложно. Пролог: они должны быть абсолютно точными.
Анонимные переменные
Пролог позволяет использовать _ в качестве специальной анонимной переменной . Мы используем его, когда
мы должны включить переменную, но не заботимся о присваиваемом ей значении. За
пример:
Мы используем его, когда
мы должны включить переменную, но не заботимся о присваиваемом ей значении. За
пример:
?- сестра_из(значение, _). % Является ли Вэл чьей-то сестрой? истинный
Пролог сообщает нам, что вопрос успешен, но не возвращает значение для _ .
Важной деталью является то, что анонимная переменная _ не ссылается
(я.е. share) с любой другой переменной (даже с самой собой). Итак, когда сестра_оф(вал,
_) , _ будет ли , а не иметь то же значение, что и переменная X в сестра_правила .
Мы также можем использовать анонимные переменные в фактах. Например:
лайка(_,еда). % всем нравится еда
Использование Пролога в качестве базы данных
Одно из применений Пролога — база данных в памяти. Например, вот простая база знаний о горных породах:
зерна (обсидиан, мелкий).цвет(обсидиан, темный). состав(обсидиан, лаваль_стекло).
 зерно(пемза, мелкая).
цвет(пемза,светлый).
состав(пемза,липкая_лава_пена).
зерно(шлак, мелкий).
цвет(шлак, темный).
состав (шлак, жидкая_лава_пена).
зерно(фельзит, мелкий_или_смешанный).
цвет(фельзит, светлый).
состав(фельзит, high_silica_lava).
зерно(андезит, мелкий_или_смешанный).
цвет(андезит, средний).
состав(андезит, medium_silica_lava).
зерно(базальт, мелкий_или_смешанный).
цвет(базальтовый, темный).
состав (базальт, low_silica_lava).зерно(пегматит, очень_грубое).
цвет(пегматит, любой).
состав (пегматит, гранит).
зерно(пемза, мелкая).
цвет(пемза,светлый).
состав(пемза,липкая_лава_пена).
зерно(шлак, мелкий).
цвет(шлак, темный).
состав (шлак, жидкая_лава_пена).
зерно(фельзит, мелкий_или_смешанный).
цвет(фельзит, светлый).
состав(фельзит, high_silica_lava).
зерно(андезит, мелкий_или_смешанный).
цвет(андезит, средний).
состав(андезит, medium_silica_lava).
зерно(базальт, мелкий_или_смешанный).
цвет(базальтовый, темный).
состав (базальт, low_silica_lava).зерно(пегматит, очень_грубое).
цвет(пегматит, любой).
состав (пегматит, гранит).
Обратите внимание, что в этой базе знаний нет правил, только факты.
Вот несколько запросов, которые мы можем сделать:
Какие там камни?:
?- зерно(Камень, _). Камень = обсидиан; Камень = пемза; Камень = шлак; Камень = фельзит; Камень = андезит; Камень = базальт; Камень = пегматит.
Обратите внимание, что в этом запросе предполагается, что все камни имеют зерна.Мы получили бы то же самое результат (для этой базы знаний), если мы заменили
зернонацветилисостав.Какие породы имеют светлый цвет?:
?- цвет (скала, свет). Камень = пемза; Камень = фельзит.
Какие породы не имеют светлого цвета?:
?- цвет(Камень, Цвет), Цвет\= светлый. Камень = обсидиан, Цвет = темный; Рок = шлак, Цвет = темный; Камень = андезит, Цвет = средний; Камень = базальт, Цвет = темный; Камень = пегматит, Цвет = любой.
Обратите внимание, что выражение вида
X \= Yзавершается успешно только тогда, когдаXиYсделать , а не унифицировать.Какие породы имеют такое же зерно, как базальт?:
?- зерно(базальт, Г), зерно(Камень, Г). G = тонкий_или_смешанный, Камень = фельзит; G = тонкий_или_смешанный, Камень = андезит; G = тонкий_или_смешанный, Камень = базальт.
Зернистость каких горных пород отличается от базальта?:
?- зерно(базальт, BasaltGrain), зерно(Other, OtherGrain), Базальтовое зерно \= Другое зерно.
Базальтовое зерно = мелкий_или_смешанный,
Другое = обсидиан,
Другое Зерно = хорошо;
Базальтовое зерно = мелкий_или_смешанный,
Другое = пемза,
Другое Зерно = хорошо;
Базальтовое зерно = мелкий_или_смешанный,
Другое = шлак,
Другое Зерно = хорошо;
Базальтовое зерно = мелкий_или_смешанный,
Другое = пегматит,
OtherGrain = очень_грубый.

 Базальтовое зерно = мелкий_или_смешанный,
Другое = обсидиан,
Другое Зерно = хорошо;
Базальтовое зерно = мелкий_или_смешанный,
Другое = пемза,
Другое Зерно = хорошо;
Базальтовое зерно = мелкий_или_смешанный,
Другое = шлак,
Другое Зерно = хорошо;
Базальтовое зерно = мелкий_или_смешанный,
Другое = пегматит,
OtherGrain = очень_грубый.
Базальтовое зерно = мелкий_или_смешанный,
Другое = обсидиан,
Другое Зерно = хорошо;
Базальтовое зерно = мелкий_или_смешанный,
Другое = пемза,
Другое Зерно = хорошо;
Базальтовое зерно = мелкий_или_смешанный,
Другое = шлак,
Другое Зерно = хорошо;
Базальтовое зерно = мелкий_или_смешанный,
Другое = пегматит,
OtherGrain = очень_грубый.
Выполнение простых арифметических операций с помощью Пролога
Функции Пролога не возвращают значения таким же образом, как функции в большинстве другие языки делают. Вам нужно использовать дополнительные параметры, чтобы получить результаты расчет.Например:
to_celsius(F, C):- C равно (F - 32) * 5/9.
Оператор is используется всякий раз, когда нам нужен результат арифметического действия.
расчет.
Вы вызываете to_celsius следующим образом:
?- to_celsius(90,C). С = 32,22222222222222.
К сожалению, первый аргумент to_celsius не может быть без конкретизации, например:
?- to_celsius(F, 15).
 ОШИБКА: is/2: Аргументы недостаточно конкретизированы
ОШИБКА: is/2: Аргументы недостаточно конкретизированы
Ошибка говорит о том, что правая часть оператора is не разрешена
иметь неинстанцированные переменные.
Вот еще одна функция, вычисляющая площадь круга:
circle_area(Радиус, Площадь):- Площадь равна Радиус * Радиус * 3.14. ?- круг_область(3, Площадь). Площадь = 28,26.
Работа со списками
Пролог обеспечивает хорошую поддержку списков. Список пролога начинается с [ , конец
с ] и отдельные значения с , . Например, [5, 7, 3] и [a, b, c] оба являются списками Пролога. Пролог предоставляет удобную запись для
легко получить доступ к первому элементу списка и остальным элементам:
?- [Голова|Отдых] = [a, b, c, d].Голова = а, Отдых = [b, c, d].
Мы будем часто использовать этот | нотация для обработки перечисляет один элемент в
время.
Вы также можете получить более одного элемента во главе списка, например:
?- [Первый, Второй | Отдых] = [а, б, в, г].
 Первый = а,
Второй = б,
Отдых = [в, г].
Первый = а,
Второй = б,
Отдых = [в, г].
Функция-член
Правила Пролога достаточно гибки, чтобы реализовать любую функцию , которая нам нравится, и поэтому можно использовать Пролог как язык программирования общего назначения.
Давайте напишем функцию с именем member(X, L) , которая завершается успешно, когда X где-то в списке L . В Прологе нет циклов, поэтому используем рекурсию:
участника(X, [X|_]). % базовый вариант элемент(X, [_|Остальное]):- член(X, Остальное). % рекурсивный случай
Как и в случае любой рекурсивной функции, у нас есть базовый и рекурсивный случай. То
базовый случай: member(X, [X|_]) , что завершается успешно только тогда, когда элемент, который мы
ищете — это первый элемент списка.Мы используем анонимный
переменная _ здесь, потому что мы не используем остальную часть списка.
В рекурсивном случае мы можем с уверенностью предположить, что первый элемент списка
не X , потому что это было бы поймано в предыдущем случае. Так что если
Так что если X есть в списке, должно быть где-то в Остальное , вот что мы
проверить в теле.
Мы можем использовать элемент следующим образом:
?- член(5, [6, 8, 15, 1]). ложный. ?-член(5, [6, 8, 5, 1]).истинный ; % введено пользователем ; ложный.
Второй пример странный: Пролог вернул и истину, и ложь! Который
Это? Пролог нашел 5 в конце списка, и поэтому он вернул
истинный. Поскольку пользователь набрал ; , Пролог возвращается к своему последнему
точка принятия решения и пытается найти 5 где-то дальше в списке. Не может и
поэтому он возвращает ложь.
Таким образом, вы можете считать, что истинное означает, что 5 было найдено, а ложное что означает «больше пятерок не найдено».Если вас волнует только то, есть или нет
находится где-то в списке 5, то вы можете остановиться (введите . ), как только возвращается true .
Теперь появляется очень хорошая особенность Пролога. Мы можем использовать элемент
Мы можем использовать элемент для создания
элементы в списке один за другим. Например:
?- член(X, [6, 8, 1, 15]). Х = 6; Х = 8; Х = 1; Х = 15; ложный.
Это, по существу, выполняет итерацию по элементу списка за раз, аналогично цикл в императивном языке.
Мы также можем писать запросы:
?- член(5, [6, 8, X, 1, 15]). Х = 5; ложный.
Эти примеры показывают, что член может делать гораздо больше, чем просто проверять,
номер есть в списке. Программисты на Прологе часто пытаются писать функции таким образом,
что позволяет переменным появляться в любом месте аргументов. Это не всегда
сделать это возможно (см. to_celsius выше), но когда вы можете это сделать,
результаты могут быть весьма полезными.
Функция длины
Функцию Пролога length(Lst, N) можно использовать для вычисления длины
список:
?- длина([], N).Н = 0. ?- длина([3],N). Н = 1. ?- длина([3, 6, 8], N).
 Н = 3.
?- длина([3, X, 6, 8], N).
Н = 4.
Н = 3.
?- длина([3, X, 6, 8], N).
Н = 4.
Вы также можете использовать длины , чтобы проверить, имеет ли список заданную длину, например:
?- длина([3, 1, 4], 3). истинный. ?- длина([3, 1, 4], 2). ложный.
Удивительно, но вы также можете длины создавать списки заданной длины для
вы, например:
?- длина(X, 2). X = [_G1985, _G1988].
X — это список длины 2, содержащий две переменные, сгенерированные
Пролог.
Вы даже можете передать две переменные до длины :
?- длина(Lst, N). Лст = [], Н = 0; Лст = [_G1997], Н = 1; Lст = [_G1997, _G2000], Н = 2; Lst = [_G1997, _G2000, _G2003], Н = 3; Lst = [_G1997, _G2000, _G2003, _G2006], Н = 4 ...
Генерирует бесконечное количество списков длины 0, 1, 2, 3, ….
Хотя длина встроена, полезно написать собственную версию
Это. Например:
милен([], 0). % базовый вариант
mylen([_|Xs], Len) :- % рекурсивный регистр
mylen(Xs, Rest_len),
Len равен 1 + Rest_len. 
В обычных случаях мылен работает так же, как длина :
?- mylen([], N). Н = 0. ?- мылен([3], N). Н = 1. ?- мылен([3, 6, 8], N). Н = 3. ?- mylen([3, X, 6, 8], N). Н = 4. ?- mylen([3, 1, 4], 3). истинный. ?- mylen([3, 1, 4], 2). ложный.
Это также работает, когда вы передаете ему две переменные:
?- мылен(Lst, N). Лст = [], Н = 0; Lст = [_G20210], Н = 1; Lst = [_G20210, _G20213], Н = 2; Lst = [_G20210, _G20213, _G20216], Н = 3; Lst = [_G20210, _G20213, _G20216, _G20219], Н = 4 ...
Но в данном случае это не совсем так:
?- мылен(Lst, 3). Lst = [_G22652, _G22655, _G22658] ; % типов пользователей; %... работает вечно...
mylen(Lst, 3) находит в качестве первого решения список длины 3. Но тогда, если
вы запрашиваете другое решение, набрав ; , программа зависает
в бесконечном цикле. Поскольку нас интересует только базовый Пролог, мы
просто проигнорирует эту проблему; это конкретное использование mylen не кажется
быть очень распространенным или полезным.
Простая статистика
Предположим, вы хотите вычислить сумму списка чисел. Вот как вы мог бы сделать это на Прологе:
сумма([], 0). % базовый вариант
sum([X|Xs], Total) :- % рекурсивный случай
сумма (Xs, Т),
Итого равно X + T. % всегда используют "is" для арифметики.
Теперь мы можем написать функцию для вычисления среднего:
среднее (X, среднее): -
сумма (X, Всего),
длина(Х, Н),
Среднее значение — общее количество/количество.
Теперь давайте напишем функцию, которая вычисляет минимальное значение списка.Во-первых, мы пишем функцию min , которая определяет меньшее из двух
входы:
мин(X, Y, X):- X =< Y. % =< меньше или равно min(X, Y, Y) :- X > Y.
Мы используем min в определении min_list следующим образом:
мин_список([Х],Х). % базовый вариант
min_list([Head|Tail], Min): - % рекурсивный регистр
min_list(Хвост, Tмин),
мин(Напор, Tмин, Мин).

Добавление
Пролог имеет стандартную встроенную функцию добавления, но полезно пишем свою версию.Например:
myappend([], Ys, Ys). % базовый вариант myappend([X|Xs], Ys, [X|Zs]) :- % рекурсивный регистр myappend(Xs, Ys, Zs).
Потратьте некоторое время на то, чтобы внимательно изучить это определение — оно того стоит. понимание.
Эту функцию можно использовать по-разному. Например:
?- myappend([1,2],[3,4],[1,2,3,4]). % подтверждают, что добавляются два списка истинный. % в другой список ?- myappend([1,2],[3,4],[1,2,3,4,5]).ложный. ?- мое добавление([1,2],[3,4],X). % добавить два списка Х = [1, 2, 3, 4]. ?- myappend([1,2],X,[1,2,3,4]). % какой список дописать, чтобы сделать другой? Х = [3, 4]. ?- myappend(X,[3,4],[1,2,3,4]). Х = [1, 2]. ?- myappend(X,Y,[1,2,3,4]). % все пары списка, которые добавляются, чтобы сделать Х = [], % [1,2,3,4] Y = [1, 2, 3, 4]; Х = [1], Y = [2, 3, 4] ; Х = [1, 2], Y = [3, 4] ; Х = [1, 2, 3], Y = [4] ; Х = [1, 2, 3, 4], Y = [] ; ложный.
