Узнаем как разобрать предложение по составу? Русский язык
Разбор предложения по частям речи — это очень важная часть познания русского языка в принципе. Она поможет вам вникнуть в суть построения всех предложений в вашей речи, понять, какие роли есть у слов, которые мы употребляем, как правильно их применять и почему все строится именно так в нашем великом и могучем русском языке. Итак, в этой статье мы разберемся, как разобрать предложение по составу, но для начала обратимся к теории.
Что такое предложение
Чтобы наша речь была связной и имела информационный посыл, мы разделяем ее на смысловые единицы. Если «копать» глубоко, то, чтобы донести информацию, мы издаем звуки, которые образуют буквы, складывающиеся в слова, которые, в свою очередь, объединяются с другими словами в словосочетания и образуют предложения.
Если слова сами по себе несут какой-то определенный, постоянный смысл, то в предложениях они начинают играть уже другие роли, менять оттенки своих значений, чтобы подстроиться под доносимую человеком информацию. В предложении всегда есть законченный смысл, который может подкрепляться интонацией, если вы говорите, или знаками препинания, если вы пишете. Сложные конструкции состоят из множества разных частей, эту тему обязательно проходят в школе, а, значит, домашним заданием часто оказывается разбор предложений по русскому языку. Сейчас мы попробуем научиться делать это быстро, легко и правильно.
В предложении всегда есть законченный смысл, который может подкрепляться интонацией, если вы говорите, или знаками препинания, если вы пишете. Сложные конструкции состоят из множества разных частей, эту тему обязательно проходят в школе, а, значит, домашним заданием часто оказывается разбор предложений по русскому языку. Сейчас мы попробуем научиться делать это быстро, легко и правильно.
Виды предложений
Начнем с того, что определим, какие бывают виды этих языковых единиц в русском языке, а уже потом перейдем к составляющим предложения. Итак, два их основных типа — это простые и сложные предложения. Простые имеют минимум одну грамматическую основу и законченный смысл, а вся особенность сложных в том, что они состоят из двух или больше простых, которые соединяются союзами, знаками препинания ну и, естественно, смыслом и интонацией.
Также, имея дело со сложным, может быть осуществлен не только разбор предложения по частям речи, а и графическое изображение его схемы. Это возможно потому, что сложные предложения также имеют свои виды. Они могут быть сложносочиненными, сложноподчиненными и бессоюзными. В сложносочиненных и бессоюзных простые предложения равноправны по своему смыслу, и отличие этих двух видов лишь в том, что сложносочиненные соединяются при помощи союза, а бессоюзные — благодаря знакам препинания. В сложноподчиненных предложениях одна часть зависит от другой по смыслу (или две части равноправны, а одна зависит от них, или несколько частей зависят друг от друга и относятся при этом к одному, главному), которые также соединяются с помощью союзов.
Это возможно потому, что сложные предложения также имеют свои виды. Они могут быть сложносочиненными, сложноподчиненными и бессоюзными. В сложносочиненных и бессоюзных простые предложения равноправны по своему смыслу, и отличие этих двух видов лишь в том, что сложносочиненные соединяются при помощи союза, а бессоюзные — благодаря знакам препинания. В сложноподчиненных предложениях одна часть зависит от другой по смыслу (или две части равноправны, а одна зависит от них, или несколько частей зависят друг от друга и относятся при этом к одному, главному), которые также соединяются с помощью союзов.
Части предложения
Перейдем к тому, из каких частей состоят и простые, и сложные предложения. Это могут быть как слова, так и словосочетания, которые подчеркиваются линиями различных видов (кроме служебных частей речи, так как они не отвечают ни на какие вопросы). Также части предложения играют свои роли, от которых зависит и то, как их подчеркивать, и то, каким будет смысл доносимой информации.
Грамматическая основа
Говоря о том, как разобрать предложение по составу, первым делом нужно понять, что такое его грамматическая основа. Это то, что содержит стержень и основной смысл того, что вы хотите сказать, и состоит из подлежащего (подчеркивается одной линией) и сказуемого (подчеркивается двумя линиями).
Подлежащее отвечает на вопрос «кто?» и «что?» и обычно является существительным или местоимением (однако в некоторых случаях подлежащим может быть и глагол — здесь уже нужно вникать в смысл и правильно ставить вопросы).
Сказуемое отвечает на вопрос «что делать?» и реже «каков?», выражается чаще всего глаголом, в некоторых случаях кратким прилагательным и даже существительным. Определив грамматическую основу, вы уже на половине пути к тому, чтобы понять, как разобрать предложение по составу, осталось справиться с остальными частями.
Второстепенные члены
Кроме грамматической основы, в предложении есть другие, второстепенные части, которые отвечают за уточнение, распространение и украшение основного смысла и посыла. Всего этих остальных составляющих предложения три:
Всего этих остальных составляющих предложения три:
- Определение, которое отвечает на вопросы «какой?», «который?», «чей?», может выражаться самыми разными частями речи, но в основном прилагательным, местоимением и числительным, при разборе подчеркивается волнистой линией.
- Дополнение, отвечающее на все вопросы косвенных падежей, выражающееся, в основном, существительными и местоимениями, подчеркивается пунктиром.
- Обстоятельство, которое выражается наречием или существительным с предлогом, отвечает на вопросы наречия («как?», «где?», «куда?», «когда?», «зачем?») и подчеркивается пунктиром с точкой.
Разбор простого предложения
Теперь от теории можно перейти к практике. Далее будет продемонстрирован образец разбора предложения по его составляющим и детальное описание его вида.
Конкретно в этом примере определить грамматическую основу и второстепенные члены довольно легко: нужно просто поставить вопросы. Теперь разберемся с тем, что написано в скобочках:
- Предложение простое, так как есть лишь одна грамматическая основа (девочка подобрала).

- Повествовательное, так как в нем просто описывается не вопрошающее и не призывающее ни к чему действие.
- Невосклицательное, так как в конце стоит точка.
- Распространенное, так как есть второстепенные члены предложения.
- Двусоставное, так как в основе есть и подлежащее, и сказуемое.
- Не усложнено ни оборотами, ни однородными членами.

Если запомнить такой алгоритм, то разбор простого предложения не будет представлять никаких трудностей, а значит, можно переходить уже и на следующий уровень.
Разбор сложного предложения
Чтобы разобрать сложное предложение, не нужно пугаться того, что оно длинное, и просто запомнить — это всего лишь несколько простых предложений, соединенных между собой.
Итак, как видите, сначала была дана общая характеристика всему предложению (оно вновь повествовательное и невосклицательное, однако теперь сложноподчиненное, так как вторая часть зависит по смыслу от первой, и к ней можно задать вопрос «зачем?»), а затем разбираются уже отдельно каждое из двух простых предложений.
Первое не изменилось с прошлого примера, но заметьте, что теперь оно стало главным предложением, а второе — подчиненным, и они соединяются союзом «чтобы», обозначающим причину действия.
Второе предложение также двусоставное, распространенное, но теперь уже осложненное деепричастным оборотом «выходя из комнаты», который отвечает на вопрос «что делая?», выделяется запятыми и полностью подчеркивается пунктиром с точкой.
Схемы
Объясняя то, как разобрать предложение по составу, нельзя не упомянуть изображение соответствующих схем. Они показывают грамматические основы в сложных предложениях и то, как они связаны между собой. Главные части изображаются в квадратных скобочках, а зависимые в круглых, при этом указывается союз для лучшего понимания смысла. Рассмотрим схему предыдущего сложного предложения.
Первая часть о том, что девочка подобрала жвачку, заключена в квадратные скобки, так как это главное предложение (внутри вы видите изображение грамматической основы), вторая часть заключена в круглые, так как в ней указывается причина того, что произошло в первой части, а, значит, она от нее зависима. Также во втором простом предложении есть деепричастный оборот — он тоже в скобках и стоит между подлежащим и сказуемым.
Также во втором простом предложении есть деепричастный оборот — он тоже в скобках и стоит между подлежащим и сказуемым.
Как можно самостоятельно выполнить синтаксический разбор простого и сложного предложения (схема и план) + 5 лучших онлайн сервисов для ленивых
Просмотров 69.2k. Опубликовано Обновлено
Синтаксический анализ вызывает у новичка в этом вопросе большие трудности. Особенно пугает длинное предложение, которое имеет множество членов, предикативных частей. На деле выполнять решение не так страшно, и русский язык предельно логичен, как и его синтаксис. Из этой статьи вы узнаете о том, что такое полный синтаксический разбор предложения – образец анализа приведен подробно, в деталях.
Для чего нужен синтаксический анализ
Синтаксический анализ – это выделение членов предложения по их функциональному значению и описание высказывания исходя из его целевых, эмоциональных, структурных особенностей.
Иногда его называют пунктуационным разбором. Такой анализ более глобален, чем орфографический, морфологический или фонетический.
Научившись самостоятельно делать синтаксический анализ на примере, можно разобраться в структуре высказывания, принципах его построения. Синтаксис и пунктуация взаимосвязаны, поэтому определение схемы дает знания о том, как расставлять знаки препинания.
Таблица или образец синтаксического разбора будут помогать как ребенку в начальной школе, так и студенту лингвистической специальности, изучающему русский язык.
Типы простого предложения
Простое предложение – это высказывание, где есть одно подлежащее и одно сказуемое. Также возможен вариант, когда есть только подлежащее или только сказуемое.
По цели бывают:
- повествовательными – автор делится информацией, есть точка в конце;
Катя решила сделать гимнастику.
- вопросительными – автор хочет узнать определенную информацию, есть вопрос в конце;
Когда уже наступит лето?
- побудительные – автор побуждает сделать что-либо, восклицательный знак в конце.

Не сорите в общественном месте!
Побудительные высказывания часто имеют лексические маркеры, которые дают подсказку: давай, будем, сделай, идемте и т.п.
Классификация по эмоциональной окраске включает в себя:
- восклицательные – есть восклицательный знак в конце;
Петя, почему ты не помыл руки?!
- невосклицательные – нет восклицательного знака в конце.
На дворе снежно и солнечно.
По наличию главных членов простые предложения принимают такой вид:
- односоставные – если есть подлежащее, но нет сказуемого, или наоборот;
В городе весна.
В столице пахнет осенью.
- двусоставные – есть и подлежащее, и сказуемое.
Зима настала в городе
Когда нет одного из главных членов:
- назывные – только подлежащее;
Здесь глушь.

- определенно-личные – только сказуемое, которое стоит в 1-м или 2-м лице;
Люблю кататься на коньках.
- неопределенно-личное – сказуемое стоит во множественном числе и 3-м лице;
К вам пришли.
- обобщенно-личное – грамматическая форма сказуемого не важна, важно только значение обобщенности и то, что высказывание можно отнести к любому человеку;
Работаешь, работаешь – и без результата
.
- безличное – сказуемое может быть наречием, а также страдательным причастием прошедшего времени или безличным глаголом.
Мне нужно выйти. Ему не спится.
Обобщенно-личный тип включает прежде всего пословицы, поговорки, фразеологизмы и другие устойчивые сочетания.
По наличию второстепенных членов высказывания делятся на:
- нераспространенные – есть только грамматическая основа;
Корабль плывет.

- распространенные – есть другие члены предложения, кроме грамматической основы: обстоятельство, или дополнение, или определение, или все вместе.
Корабль величественно плывет по волнам.
По критерию полноты выражения предложение может быть:
- полным – все члены прописаны, нет недоговоренности;
Мое жилье располагается здесь.
- неполным – определенные члены могут подразумеваться, нередко на их месте стоит тире.
А мое жилье – здесь.
Учитывая все критерии, по которым делятся предложения, и их характеристики, можно сделать подробный синтаксический анализ по плану.
Типы сложного предложения
Сложное – это высказывание, в котором при идеальном раскладе есть два подлежащих и два сказуемых. Но иногда случается, что есть только два сказуемых или только два подлежащих, одно сказуемое и два подлежащих и т.п.
В сложном предложении с несколькими придаточными частями можно найти даже 3 или 4 грамматических основы, а не только 2.

Сложные высказывания делятся по цели и эмоциональной окраске так же, как и простые.
При определении типа сложного предложения нужно смотреть на наличие союза:
- союзное – союз есть;
Если бы на Земле не было воды, здесь бы не зародилась жизнь.
- бессоюзное – союз отсутствует, может стоять запятая или даже двоеточие;
Ярик не пошел в школу и остался дома: он болел.
В зависимости от союза высказывания бывают:
- сложносочиненные – союз сочинительный: сюда входят соединительные, противительные и разделительные;
Аня хотела хорошую оценку, но она не сделала домашнее задание.
- сложноподчиненные – союз подчинительный: все остальные союзные группы относятся к этому виду.
Аня должна была сделать домашнее задание, чтобы учитель поставил ей хорошую оценку.
Необходимо указывать, какой союз соединяет предикативные части высказывания; в бессоюзных предложениях это интонация.

После указания типа придаточной каждая из частей разбирается как простое предложение. Порядок синтаксического разбора такой же, но алгоритм начинается с критерия односоставности/двусоставности.
Как составить схему предложения
Рисовать схему нужно после выполнения самого синтаксического разбора. Произведите сперва обобщающий пунктационный разбор, иначе она рискует быть неполной или неверной.
Предлагаем составление схемы по следующей последовательности:
- рисуем скобки – в простом и сложносочиненном высказывании всегда нужны квадратные скобки, т.к. оно не имеет зависимых частей, а в сложноподчиненном –квадратными обозначается главная часть, а круглыми – зависимая;
- делаем графическое отображение предложения внутри, отмечая только грамматическую основу прямыми линиями в логическом порядке, никаких пунктирных или волнистых подчеркиваний.
- если есть союз или союзное слово, оно пишется буквами, а сверху подписывается с. или с. с.
- если сложноподчиненное, нужно нарисовать стрелку от главной части и подписать сверху вопрос к придаточной, на который она отвечает.
 с.
с.Например, схематический анализ сложноподчиненного предложения с разными видами связи выглядит так:
Я не хотел никого обидеть, но Саша надулся и сказал, что теперь он не будет со мной общаться.
[– =], но [– = и =], (что…).
Грамматическую основу рисуют только в главных частях, а союз в придаточной находится только внутри скобок, в отличие от независимых частей.
Образец простого разбора
Высшее общество всегда казалось ей неестественным, лживым и лицемерным.
Повествовательное, невосклицательное, простое, двусоставное, распространенное, полное.
Грамматическая основа: подлежащее – общество, сказуемое – казалось неестественным, лживым, лицемерным. Второстепенные члены: высшее – определение, ей – дополнение. Осложнено однородными составными глагольными сказуемыми.
Осложнено однородными составными глагольными сказуемыми.
Образец сложного разбора
Артур, уберись в своей комнате до прихода гостей, иначе я тебя накажу.
Побудительное, невосклицательное, сложносочиненное, состоит из двух предикативных частей, средство связи – сочинительный союз «иначе».
Первая часть: односоставное, определенно-личное, распространенное, полное. Сказуемое – уберись. В своей комнате до прихода гостей – обстоятельство. Осложнено обращением.
Вторая часть: двусоставное, распространенное, полное. Подлежащее – я, сказуемое – накажу. Тебя – дополнение. Ничем не осложнено.
5 лучших онлайн сервисов
Синтаксический разбор предложения и текста сегодня можно выполнить онлайн и бесплатно.
ТОП-5 сервисов для этого:
- ProgaOnline – делает подчеркивания, определяет не только части речи, но и их формы: падеж, число, лицо и др.;
- Rustxt – яркий понятный дизайн, предоставляет довольно подробный синтаксический анализ;
- Seosin – может выполнять синтаксический разбор не только словосочетание или предложение, но и текст, подчеркивает все члены, делает морфологический анализ;
- GoldLit – неограниченное количество символов, есть анализы художественной литературы, но выдает только полный анализ части речи;
- Школьный помощник – поможет только со справочной информацией по теме, есть схемы анализа и упражнения.
Необходимо помнить, что анализ, который выполняется любой программой, может содержать мелкие неточности.
Проблемы с синтаксическим разбором предложений
Самой распространенной проблемой для школьника становится разделение частей речи от их функций в высказывании. Отсюда вытекает неумение правильно подчеркнуть члены.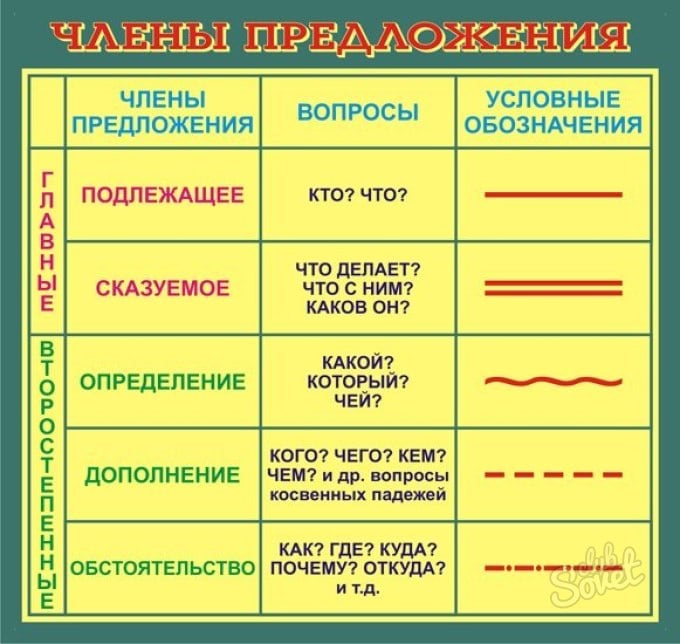
Важно помнить: существительное либо местоимение может быть как дополнением, так и подлежащим, для имени прилагательного определение не приговор, числительные могут выступать в любой функции, а предлоги зависимы и закреплены за другими членами.
Побудительные предложения иногда заканчиваются точкой, а повествовательные – восклицательным знаком. Чтобы не запутаться, нужно обратить внимание на семантический аспект (что оно означает), а не только на знаки препинания.
Возникают проблемы и с тем, какими членами может быть осложнено предложение.
Высказывание часто осложняется:
- вводными конструкциями;
- деепричастием с зависимыми словами;
- причастным оборотом;
- сравнением и другими обособленными оборотами;
- обращением;
- приложением, т.е. определением в форме существительного;
- однородными членами.
Выводы
В этом материале мы рассмотрели, как сделать синтаксический анализ (разбор) простых и сложных предложений, разобрали конкретные примеры письменного анализа, возможные трудности. С использованием такой пошаговой инструкции и памяткой проанализировать высказывание сможет даже новичок.
С использованием такой пошаговой инструкции и памяткой проанализировать высказывание сможет даже новичок.
Разбор слова по звукам. Схемы и примеры
В процессе школьного обучения русскому языку ученики знакомятся с разными видами разборов. Это и лексический анализ слова, и разбор по составу и способам образования. Дети учатся разбирать предложение по членам, выявлять его синтаксические и пунктуационные особенности. А также производить многие другие языковые операции.Обоснование темы
После повторения материала, пройденного в начальной школе, учащиеся 5-х классов приступают к первому крупному разделу языкознания – фонетике. Завершением его изучения является разбор слова по звукам. Почему именно с фонетики начинается серьёзное и глубокое знакомство с родной речью? Ответ прост. Текст состоит из предложений, предложения – из слов, а слова – из звуков, которые и являются теми кирпичиками, строительным материалом, первоосновой языка, причем не только русского, а любого. Вот почему разбор слова по звукам – начало формирования практических навыков и умений школьников в лингвистической работе.
Почему именно с фонетики начинается серьёзное и глубокое знакомство с родной речью? Ответ прост. Текст состоит из предложений, предложения – из слов, а слова – из звуков, которые и являются теми кирпичиками, строительным материалом, первоосновой языка, причем не только русского, а любого. Вот почему разбор слова по звукам – начало формирования практических навыков и умений школьников в лингвистической работе.
Понятие фонетического разбора
Что именно включает он в себя, и что нужно знать школьникам, чтобы успешно справляться с заданиями фонетического характера? Во-первых, хорошо ориентироваться в слоговом членении. Во-вторых, разбор слова по звукам не может производиться без чёткого различения гласных и согласных фонем, парных и непарных, слабых и сильных позиций. В-третьих, если оно (слово) включает йотированные, мягкие или твёрдые элементы, удвоенные буквы, ученик тоже должен уметь ориентироваться, какая литера используется для обозначения того или иного звука на письме. И даже такие сложнейшие процессы, как аккомодация или ассимиляция (уподобление) и диссимиляция (расподобление), тоже должны быть ими хорошо изучены (хотя указанные термины и не упоминаются в учебниках, тем не менее, дети знакомятся с этими понятиями). Естественно, что разбор слова по звукам не может производиться, если ребёнок не умеет транскрибировать, не знает элементарных правил транскрипции. Поэтому учитель должен серьёзно и ответственно подойти к преподаванию раздела «Фонетика».
Естественно, что разбор слова по звукам не может производиться, если ребёнок не умеет транскрибировать, не знает элементарных правил транскрипции. Поэтому учитель должен серьёзно и ответственно подойти к преподаванию раздела «Фонетика».
Теоретические рекомендации
Что представляет собой схема разбора слова по звукам? Какие этапы она включает? Разберёмся в этом подробно. Для начала лексема выписывается из текста, ставится знак «тире», после чего она пишется снова, только уже разделённая на слоги. Проставляется ударение. Затем открываются квадратные скобки, и ученик должен слово затранскрибировать – записать так, как оно слышится, т. е. выявить его звуковую оболочку, обозначить мягкость фонем, если таковые имеются, и т. д. Далее под вариантом транскрипции нужно пропустить строчку, провести вниз вертикальную черту. Перед ней в столбик записываются все буквы слова, после – в квадратных скобках звуки и даётся их полная характеристика. В конце разбора проводится небольшая горизонтальная черта и, как подведение итогов, отмечается количество буквы и звуков в слове.
Пример первый
Как всё это выглядит на практике, т. е. в школьной тетрадке? Произведём вначале пробный разбор слова по звукам. Примеры анализа дадут возможность понять многие нюансы. Записываем: покрывало. Делим на слоги: по-кры-ва´-ло. Транскрибируем: [пакрыва´ла].
Анализируем:
п – [п] – это звук согласный, он глухой, парный, пара — [б], твердый;
о – [а] – это гласный звук, безударный;
к – [к] – звук согл., он глух., парн., [пара — г], твёрд.;
р – [р] — звук согласный, сонорный, поэтому непарный по звонкости, твёрдый;
ы – [ы] – это гласный, в данной позиции безударный;
в – [в] – звук этот согл., является звонким, пара его — [ф], твёрдый;
а — [а´] – гласный звук, в ударной позиции;
л – [л] – это звук согл., относится к сонорным, поэтому непарн., твёрдый;
о – [а] – согласный, безударный.
Итого: 9 букв в слове и 9 звуков; количество их полностью совпадает.
Пример второй
Посмотрим, как произвести разбор слова «друзья» по звукам. Действуем по уже намеченной схеме. Делим его на слоги, выставляем ударение: дру-зья´. Теперь записываем в транскрибируемом виде: [друз’й’а´]. И анализируем:
Действуем по уже намеченной схеме. Делим его на слоги, выставляем ударение: дру-зья´. Теперь записываем в транскрибируемом виде: [друз’й’а´]. И анализируем:
д – [д] – согласный, он звонкий и является парным, пара — [т], твёрдый;
р – [р] – согл., звонкий, сонорный, непарный, твёрдый;
у – [у] – гласный, безударный;
з – [з’] – согл., является звонким, имеет глухую пару — [с], мягкий и тоже парный: [з];
ь – звука не обозначает;
я – [й’] – полугласный, звонкий всегда, поэтому непарный, всегда мягкий;
[а´] – гласный, ударный.
В данном слове 6 букв и 6 звуков. Их количество совпадает, т. к. Ь звука не обозначает, а буква Я после мягкого знака обозначает два звука.
Пример третий Показываем, как следует делать разбор слова «язык» по звукам. Алгоритм вам знаком. Выписывайте его и делите на слоги: я-зык. Затранскрибируйте: [й’изы´к]. Разберите фонетически:
я – [й’] – полугласный, звонкий, непарный всегда, только мягкий;
[а] – этот звук гласный и безударный;
з – [з] – согл., звонкий, парный, пара — [с], твёрдый;
ы – [ы´] – гласный, ударный;
к – [к] – согласный, глухой, парный, [г], твёрдый.
Слово состоит из 4 букв и 5 звуков.
Их количество не совпадает потому, что буква Я стоит в абсолютном начале и обозначает 2 звука. Пример четвёртый Посмотрим, как выглядит разбор слова «белка» по звукам. После выписки его произведите слогоделение: бел-ка. Теперь затранскрибируйте: [б’э´лка]. И произведите буквенно-звуковой анализ:
б – [б’] – согл., звонкий, парный, [п], мягкий;
е – [э´] – гласный, ударный;
л – [л] – согл., сонорный, непар., в данном случае твёрдый;
к – [к] – согл., глух., парный, [г], твёрдый;
а – [а] – гласный, безударный.
В данном слове одинаковое количество букв и звуков – по 5. Как видите, производить фонетический разбор этого слова достаточно просто. Важно только обращать внимание на нюансы его произношения.
Пример пятый
Теперь давайте сделаем разбор слова «ель» по звукам. Пятиклассникам это должно быть интересно. Он поможет повторить и закрепить фонетические особенности йотированных гласных. Состоит слово из одного слога, что тоже непривычно ученикам. Транскрибируется оно так: [йэ´л’]. Теперь произведем анализ:
е – [й’] – полугласный, звонкий, непарный, мягкий;
[э´] – гласный, ударный;
л – [л´] – согласный, сонорный, поэтому непарный, в данном слове мягкий;
ь – звука не обозначает.
Таким образом, в слове «ель» 3 буквы и 3 звука. Буква Е обозначает 2 звука, т. к. стоит в начале слова, а мягкий знак звуков не обозначает.
Делаем выводы
Мы привели примеры фонетического разбора слов, состоящих из разного количества слогов и звуков. Учитель, объясняя тему, обучая своих школьников, должен стараться наполнить их словарный запас соответствующей терминологией. Говоря о звуках «Н», «Р», «Л», «М», следует называть их сонорными, попутно указывая, что они всегда звонкие и потому не имеют пары по глухости. [Й] сонорным не является, но тоже только звонкий, и по этому параметру примыкает к 4 предыдущим. Более того, раньше считалось, что этот звук относится к согласным, однако его справедливо называть полугласным, т. к. он очень близок к звуку [и]. Как лучше запомнить их? Запишите с детьми предложение : «Мы не увидели подругу». В неё и входят все сонорные.
Особые случаи разбора
Для того чтобы правильно определить фонетическую структуру слова, важно уметь в него вслушаться. Например, словоформа «лошадей» будет иметь такой вид в транскрипции: [лашыд’э´й’], «дождь» — [до´щ’]. Разобраться самостоятельно пятиклассникам с такими и подобными случаями довольно сложно. Поэтому учитель должен на уроках стараться анализировать интересные примеры и обращать внимание учеников на некоторые языковые тонкости. Касается это и таких слов, как «праздник», «дрожжи», т. е., содержащих удвоенные или непроизносимые согласные. На практике оно выглядит следующим образом: празд-ник, [пра´з’н’ик]; дрож-жи, [дро´жы]. Над «ж» следует провести черту, указывающую на длительность звука. Нестандартна тут и роль буквы И. Здесь она обозначает звук Ы.
О роли транскрипции
Для чего слово обязательно нужно транскрибировать? Фонетический анализ помогает увидеть графический облик лексемы. Т. е., наглядно показать, как слово выглядит в своей звуковой оболочке. Какова вообще цель такого разбора? Она состоит не только в сравнение языковых единиц (буквы и звуки, их количество). Фонетический анализ даёт возможность проследить, в каких позициях одна и та же буква обозначает разные звуки. Так, традиционно считается, что в русском языке гласная «ё» всегда стоит в сильной ударной позиции. Однако в словах иноязычного происхождения это правило не срабатывает. То же самое касается и сложных по составу лексем, состоящих из двух и более корней. Например, прилагательное трёхъядерный. Транскрипция его такова: [тр’иох’а´д’ирный’]. Как видим, ударный тут звук [а].
К вопросу о слогоделении
Слогоделение — тоже вопрос довольно сложный для пятиклассников. Обычно учитель ориентирует детей на такое правило: сколько в слове гласных букв, столько и слогов. Ре-ка: 2 слога; по-душ-ка: 3 слога. Это так называемые простые случаи, когда гласные находятся в окружение согласных. Несколько сложнее для детей другая ситуация. Например, в слове «синяя» наблюдается стечение гласных. Школьники затрудняются, как делить на слоги подобные варианты. Следует им объяснить, что и тут правило остаётся неизменным: си-ня-я (3 слога).
Вот такие особенности наблюдаются при фонетическом разборе.
http://fb.ru/article/141406/razbor-slova-po-zvukam-shemyi-i-primeryi
Синтаксический разбор простого предложения | Учебно-методический материал по русскому языку (3 класс) на тему:
Упражнения,
карточки проверочных работ,
тесты
Главные члены предложения Подлежащее — обозначает о ком или о чём говорится в предложении и отвечает на вопрос именительного падежа КТО? ЧТО? Сказуемое — сообщает что-либо о подлежащем и отвечает на вопросы ЧТО ДЕЛАЕТ предмет? и др. Второстепенные члены предложения Определение — Какой? Какая? Какие? Дополнение — вопросы косвенных падежей – Р. — Кого? Чего? Д. — Кому? Чему? В. — Кого? Что? Т. — Кем? Чем? П. — О ком? О чём? Обстоятельство — Где? Куда? Когда? Как? и др. |
Упражнение 1
Разбери предложения по членам. Выпиши основу предложения и словосочетания.
ПРИМЕР.
Сильный ветер весело разметал осеннюю листву.
Ветер разметал – основа предложения
Ветер (какой?) сильный
Разметал (что?) листву
Разметал (как?) весело
По небу плывут белые облака.
_______________________________________
_______________________________________
_______________________________________
Рыжая белочка быстро пробежала по стволу.
_______________________________________
_______________________________________
_______________________________________
_______________________________________
На траве всюду сверкала утренняя роса.
_______________________________________
_______________________________________
_______________________________________
_______________________________________
Чёрная собака глухо зарычала на нас.
_______________________________________
_______________________________________
_______________________________________
_______________________________________
Впереди мелькнул яркий свет.
_______________________________________
_______________________________________
_______________________________________
_______________________________________
Небо заволокло тяжёлыми тучами.
_______________________________________
_______________________________________
_______________________________________
Вдруг ослепительно сверкнула яркая молния.
_______________________________________
_______________________________________
_______________________________________
_______________________________________
Сильный ветер весело разметал осеннюю листву.
_______________________________________
_______________________________________
_______________________________________
_______________________________________
Сквозь дымку тумана виднелась река.
_______________________________________
_______________________________________
_______________________________________
_______________________________________
Чудесно переливаются лучезарные краски заката. _______________________________________
_______________________________________
_______________________________________
_______________________________________
Плот бесшумно скользил по черной воде.
_______________________________________
_______________________________________
_______________________________________
_______________________________________
Упражнение 2
Спишите. Разберите предложения по членам.
- В сырых местах прятались голубоглазые незабудки.
- Серая дождевая дымка затянула окрестность.
- Вечерняя мгла быстро покрыла все поля.
- Серебристый иней запушил окно.
- Теплая летняя ночь спустилась на землю.
- По крыше часто стучали капли дождя.
- В гнезде лежало маленькое голубое яичко.
- Дикие утки и крикливые журавли летят на соседнее озеро.
- Вечернее солнце бросает свои золотые лучи на леса и поля.
- За деревней весело играла кошка со своими котятами.
- Весенние воды и летние ливни легко размывают чернозем.
- Седые туманы плывут к облакам.
- В воздухе стоял страшный зной.
- На крылечке дремал рыжий кот.
- Рыжие лисята вылезли из норы.
- Ветер забирался в печные трубы и тоскливо выл.
Упражнение 3
Спишите. Разберите предложения по членам.
- Невдалеке сверкает на солнце извилистая речонка.
- Перед нами простирался необъятный лесной массив.
- Красногрудые снегири клевали ягодки рябины.
- Вдали стоит дубовый лес и блестит на солнце.
- Пушистый снег хлопьями падает на землю.
- Красивый пейзаж вызывает радостное чувство.
- Гусь подошел сзади и больно долбанул Каштанку клювом.
- Собака громко залаяла на ребят.
- Пушистый иней украсил деревья.
- Мотылек лениво повис на стебельке.
- Бабочка села на цветок и тихонько двигала крылышками.
- Вечером я с приятелем сидел на обрыве.
- Последние перелетные птицы покидают родные места.
- Зимние вьюги напевали нам песни чудные.
- Белобокие сороки сидели на сучке и резко стрекотали.
- Кот мягко подпрыгнул и впился когтями в мышку.
- В сырых местах прятались голубоглазые незабудки.
Упражнение 4
Спишите. Разберите предложения по членам.
- На черемухе соловей распевал свои песни.
- Две большие лохматые белые собаки бросились на кошку.
- Белый пар по лугам расстилается.
- Отец осторожно снял нагар со свечи.
- Ветерок ласково перебирает на ясенях листья.
- Из большой корзины девочка отбирала спелые вишни.
- В детских журналах часто встречаются загадочные картинки.
Быстро наступает вечер в глухом лесу. Тёмные тени ложатся под деревьями. Недвижно высятся старые сосны, чернеют густые ели. Пахнет в лесу смолой, сосновой хвоёй.
Скрылось за дальними деревьями вечернее солнце, но ещё не спят птицы в лесу. Слышишь торопливый стук дятла. Вертятся возле дятла шустрые синички, подбирают жучков и червячков. Скоро наступит в лесу тёмная, непроглядная ночь. Только в полночь замолкнут и заснут дневные птицы. Глухая беззвучная ночь накрывает землю. Но вот прошуршала под ногами мышь. И опять тихо. Потрескивает костёр, и колышутся над огнём лохматые еловые ветви. А у огня на смолистой постели беззаботно похрапывает охотник.
С-1 ЗАЧЁТНАЯ КАРТОЧКА ПО ТЕМЕ «СИНТАКСИС» 1. Пушистый снег тихо кружится в воздухе. 2. Синицы съедают вредных насекомых. 3. Вдруг налетела буря с крупным градом. 4. Сквозь дождь лучилось солнце и золотило капли на траве. |
С-2 ЗАЧЁТНАЯ КАРТОЧКА ПО ТЕМЕ «СИНТАКСИС» 1. Кот украл со стола кусок колбасы и полез с ним на берёзу. 2. Ветки берёз слегка шумели от лёгкого ветерка. 3. Мы быстро перебрались через лесной овраг. 4. Дверь тихонько отворилась, и царевна очутилась в светлой горнице. |
С-3 ЗАЧЁТНАЯ КАРТОЧКА ПО ТЕМЕ «СИНТАКСИС»
|
С-4 ЗАЧЁТНАЯ КАРТОЧКА ПО ТЕМЕ «СИНТАКСИС»
|
С-5 ЗАЧЁТНАЯ КАРТОЧКА ПО ТЕМЕ «СИНТАКСИС»
|
С-6 ЗАЧЁТНАЯ КАРТОЧКА ПО ТЕМЕ «СИНТАКСИС»
|
С-8 ЗАЧЁТНАЯ КАРТОЧКА ПО ТЕМЕ «СИНТАКСИС»
5. Ветер гудел и с шумом гнал волны. |
С-7 ЗАЧЁТНАЯ КАРТОЧКА ПО ТЕМЕ «СИНТАКСИС»
|
Синтаксический разбор предложения
Тесты
1. В каком предложении допущена ошибка в разборе по членам предложения?
- В класс пришёл новый ученик.
- Среди редких берёз прячутся в траве крепкие боровики.
- В зимнюю стужу в ельнике стоит тишина.
- Около домов жильцы сажают берёзки и липы.
- Набежала синяя тучка и закрыла солнце.
2. В каком предложении допущена ошибка в разборе по членам предложения?
- В берёзовой роще радостно звенят птичьи голоса.
- Перелётные птицы потянулись в тёплые края.
- Песня жаворонка весёлая и звонкая
- Вожак медленно расправил крылья и резко поднялся в воздух.
- Ребята следят за чистотой озёр и рек.
3. В каком предложении нет определения?
- Воздух утром прохладный.
- Жуки объедают нежные листочки берёз.
- Жуки неподвижно сидят ветках.
- Прибегают на опушку разные зверьки.
- Прилетают сюда шумные стайки птиц.
4. В каком предложении нет обстоятельства?
- Скоро созреют сладкие ягоды.
- Воздух наполняет запах полевых цветов.
- Дождевые капли тяжело ударяли по траве и листьям.
- В каждой дождинке играл солнечный луч.
- Ранним утром ребята отправились на рыбалку.
5. Под каким номером нет дополнения?
- С неба солнце посылает прощальные лучи.
- Птицы улетели в далёкие страны.
- Скоро деревья покроет снег.
- Зима заваоила городок пушистым снегом.
- Солнечные лучи мягко освещали лесок
опрос и новое предложение
Нулевые переходы (% отправлений) 56,6
Среднее количество переходов на отправку. 1,10
Отзыв брекетов (%) 83,1
Точность брекетов (%) 83,1
Отзыв GR (%) 88,1
Точность GR (%) 88,2
Таблица 1: Результаты оценки на основе компонентов и GR
6. Выражение признательности
Эта работа была поддержана проектом CEC Telematics Appli-
программы катионов LE1-2111 «SPARKLE: Shal-
low PARsing и извлечение знаний для языковой инженерии
» и стипендией EPSRC Advanced Fellowship для
первый автор.Мы хотели бы поблагодарить других исследователей из консорциума
SPARKLE, в частности Николетту Кальцолари,
Гленна Кэрролла, Стефано Федеричи, Грега Грефенстетта, Саймона-
этта Монтеманьи, Вито Пиррелли и Матса Рота за полезные отзывы во время
. формулировка новой схемы оценки грамматических отношений.
7. Ссылки
Alshawi, H. (Ed.) (1992). Core Language Engine. Cam-
bridge, MA: MIT Press.
Этвелл, Э.(1996). Сравнительная оценка грамматических аннотаций
моделей. В: R. Sutcliffe, H. Koch & A. McElligott (Eds.),
Industrial Parsing of Software Manuals (стр. 25–46). Амстер —
Плотина, Нидерланды: Родопи.
Блэк Э., Гарсайд Р. и Лич Г. (ред.) (1993). Статистически —
компьютерных грамматик английского языка: подход IBM / Lancaster
. Амстердам, Нидерланды: Родопи.
Бриско, Э. и Кэрролл, Дж.(1993). Обобщенный вероятностный анализ LR
для грамматик, основанных на унификации. Вычислительная Lin-
гистистика, 19 (1), 25–60.
Бриско, Э. и Кэрролл, Дж. (1995). Разработка и оценка вероятностного LR-парсера
части речи и пунктуации la-
бел. В материалах 4-го семинара ACL / SIGPARSE International
по технологиям синтаксического анализа (стр. 48–58). Прага, Чехия
Республика.
Бриско, Э., Гровер, К., Богураев Б. и Кэрролл Дж. (1987). Фор-
мализм и среда для развития большой грам-
мар английского языка. В Трудах IJCAI-87 (стр. 703–708).
Милан, Италия.
Карпентер Б. и Мэннинг К. (1997). Вероятностный парсинг us-
в левом углу языковых моделей. В материалах 5-го международного семинара
ACL / SIGPARSE по технологиям синтаксического анализа —
гис. Массачусетский технологический институт, Кембридж, Массачусетс.
Кэрролл, Дж.И Бриско, Э. (1996). Распределение разработки ef-
fort в системе вероятностного анализа LR посредством оценки.
В материалах конференции ACL SIGDAT по эмпирическим методам
обработки естественного языка (стр. 92–100). Uni-
Версильвания, Филадельфия, Пенсильвания.
Кэрролл, Дж., Бриско, Э., Кальцолари, Н., Федеричи, С., Монтеманьи,
С., Пиррелли, В., Грефенстетт, Г., Санфилиппо, А., Кэрролл, Г.,
Рут, М.(1997a). SPARKLE WP1 — спецификация фразового синтаксического анализа
. Http://www.ilc.pi.cnr.it/sparkle.html.
Кэрролл, Дж., Бриско, Э., Кэрролл, Г., Лайт, М., Прешер, Д., Рут,
М., Федеричи, С., Монтемагни, С., Пиррелли, В., Проданоф , I. &
Vanocchi, M. (1997b). SPARKLE WP3.2 программа для синтаксического анализа фраз —
. http://www.ilc.pi.cnr.it/sparkle.html.
Чарняк, Э. (1996). Грамматики банка деревьев. В материалах 13-й Национальной конференции по искусственному интеллекту
, AAAI-96
(стр.1031–1036). .
Церковь, К. (1988). Программа стохастических деталей и синтаксический анализатор именных фраз
для неограниченного текста. В материалах 2-й конференции ACL
по прикладной обработке естественного языка (стр.136–
143). Остин, Техас.
Коллинз М. (1996). Новый статистический анализатор на основе зависимостей bigram lexi-
cal. В материалах 34-го заседания ассоциации компьютерной лингвистики As-
(стр. 184–191). Санта
Крус, Калифорния.
Gaizauskas, R., Hepple M. & Huyck, C. (1998). Модификация ex-
аннотированных корпусов для общей сравнительной оценки синтаксического анализа
. В материалах семинара LRE по оценке систем парсинга
. Гранада, испания.
Грефенстетт Г. (1994). Исследования в автоматическом тезаурусе
covery. Дордрехт, Нидерланды: Kluwer.
Гришман Р., Маклеод К. и Стерлинг Дж. (1992). Оценка pars-
стратегий с использованием стандартизованных файлов синтаксического анализа.В материалах
3-й конференции ACL по прикладной обработке естественного языка
(стр. 156–161). Тренто, Италия.
Джекендофф Р. (1977). Синтаксис X-bar. Кембридж, Массачусетс: MIT Press.
Каплан Р. и Бреснан Дж. (1982). Лексико-функциональная грамматика:
формальная система грамматического представления. В Дж. Бреснан
(ред.), Ментальное представление грамматических отношений
(стр. 173–281). Кембридж, Массачусетс: MIT Press.
Карлссон, Ф., Voutilainen, A., Heikkil¨a, J. & Anttila, A. (1995).
Ограниченная грамматика: независимая от языка система для разбора неограниченного текста. Берлин, Германия: де Грюйтер.
Lehmann, S., Oepen, S., Regnier-Prost, S., Netter, K., Lux, V.,
, Klein, J., Falkedal, K., Fouvry, F., Estival, D. , Дофин, Э.,
Компаньон, Х., Баур, Дж., Балкан, Л. и Арнольд, Д. (1996).
ЦНЛП — тестовые наборы для обработки естественного языка. В Pro-
заседаниях Международной конференции по вычислительной Lin-
гистике, COLING-96 (стр.711–716). Копенгаген, Дания.
Лин, Д. (1995). Основанный на зависимостях метод оценки синтаксических анализаторов покрытия широких
. В Трудах IJCAI-95 (стр. 1420–
1425). Монреаль, Канада.
Лин, Д. (1996). Оценка синтаксического анализатора на основе зависимостей: исследование с
корпусом руководств по программному обеспечению. В R. Sutcliffe, H-D. Koch & A.
McElligott (Eds.), Промышленный анализ руководств по программному обеспечению (стр.
13–24). Амстердам, Нидерланды: Родопи.
Магерман, Д. (1995). Статистические модели дерева решений для pars-
ing. В материалах 33-го ежегодного собрания Ассоциации компьютерной лингвистики
. Бостон, Массачусетс.
Маркус, М., Санторини, Б. и Марцинкевич (1993). Создание большого аннотированного корпуса английского языка
: Penn Treebank. Com-
условная лингвистика, 19 (2), 313–330.
Поллард, К. и Саг, И. (1994). Головная фраза грамма —
мар.Чикаго: Издательство Чикагского университета.
Сэмпсон Г. (1995). Английский язык для компьютера. Оксфорд, Великобритания: Ox-
ford University Press.
Сэмпсон Г., Хей Р. и Этвелл Э. (1989). Естественный язык
анализ методом стохастической оптимизации: отчет о проделанной работе по проекту
АПРЕЛЬ. Журнал экспериментальной и теоретической искусственной разведки
, 1, 271–287.
Сан-Филиппо, А., Барнетт, Р., Кальцолари, Н., Флорес, С., Хеллвиг, П.,
Пиявка, П., Мелеро, М., Монтемагни, С., Одийк, Дж., Пиррелли, В.,
Тойфель, С., Виллегас М. и Зайссер, Л. (1996). Подкатегория-
стандартов. Отчет группы EAGLES Lexicon / Syntax Interest
. Доступно через eagles@ilc.pi.cnr.it.
Шарман Р. (1990). Оценка грамматики как языковой модели
для речи. В Л. Торрес, Э. Масграу и М. Лагунас (редакторы), Sig-
nal Processing V: Theories and Applications (стр. 1271–1274).
Нидерланды: Эльзевир.
Шринивас Б., Доран К., Хоккей Б. и Джоши А. (1996). Подход ap-
к надежным метрикам частичного синтаксического анализа и оценки. В Pro-
семинара ESSLLI’96 по робастному синтаксическому анализу. Прага,
Чехия.
Шринивас Б., Доран К. и Кулик С. (1995). Эвристика и синтаксический анализ
ранжирования. В материалах 4-го Международного семинара ACL / SIGPARSE
по технологиям синтаксического анализа. Прага, Чешский Re-
общедоступный.
Последние достижения в области машинного обучения
Рекомендации для читателей
Что это за страница? На этой странице слева показаны таблицы, извлеченные из документов arXiv. Он показывает извлеченные результаты с правой стороны, которые соответствуют таксономии в Papers With Code.
Какие цветные прямоугольники справа? Здесь показаны результаты, извлеченные из статьи и связанные с таблицами слева.Результат состоит из значения метрики, имени модели, имени набора данных и имени задачи.
Что означают цвета? Зеленый означает, что результат одобрен и показан на сайте. Желтый — результат того, что вы добавили, но еще не сохранили. Синий — это результат ссылки, полученный из другой бумаги.
Откуда берутся предлагаемые результаты? У нас есть модель машинного обучения, работающая в фоновом режиме, которая дает рекомендации по статьям.
Откуда берутся ссылочные результаты? Если мы находим в таблице результаты со ссылками на другие статьи, мы показываем проанализированный справочный блок, который редакторы могут использовать для аннотирования, чтобы получить эти дополнительные результаты из других статей.
Руководство для редактора
Я впервые редактирую и боюсь ошибиться. Помощь! Не волнуйтесь! Если вы сделаете ошибки, мы можем исправить их: все версионировано! Так что просто сообщите нам на канале Slack, если вы что-то случайно удалили (и так далее) — это вообще не проблема, так что дерзайте!
Как добавить новый результат из таблицы? Щелкните ячейку в таблице слева, откуда берется результат.Затем выберите одно из 5 лучших предложений. Вы можете вручную отредактировать неправильные или отсутствующие поля. Затем выберите задачу, набор данных и название метрики из таксономии «Документы с кодом». Вы должны проверить, существует ли уже эталонный тест, чтобы предотвратить дублирование; если его не существует, вы можете создать новый набор данных. Например. ImageNet по классификации изображений уже существует с показателями Top 1 Accuracy и Top 5 Accuracy.
Каковы соглашения об именах моделей? Название модели должно быть простым, как указано в документе.Обратите внимание, что вы можете использовать круглые скобки для выделения деталей, например: BERT Large (12 слоев), FoveaBox (ResNeXt-101), EfficientNet-B7 (NoisyStudent).
Другие советы и рекомендации
- Если эталонный тест уже существует для введенной пары набор данных / задача, вы увидите ссылку.
- Если эталонный тест не существует, появится значок «новый», обозначающий новый рейтинг.
- Если вам повезет, Cmd + щелкните ячейку в таблице, чтобы получить первый результат автоматически.
- При редактировании нескольких результатов из одной и той же таблицы вы можете нажать кнопку «Заменить все», чтобы скопировать текущее значение во все другие записи из этой таблицы.
Как добавить результаты, на которые имеются ссылки? Если в таблице есть ссылки, вы можете использовать функцию синтаксического анализа ссылок, чтобы получить больше результатов из других документов. Во-первых, вам понадобится хотя бы одна запись в ячейке с результатами (пример см. На изображении ниже). Затем нажмите кнопку «Анализировать ссылки», чтобы связать ссылки с статьями в PapersWithCode и аннотировать результаты.Ниже вы можете увидеть пример.
Таблица сравнения извлечена из статьи Универсальная языковая модель «Тонкая настройка для классификации текста» (Howard and Ruder, 2018) с проанализированными ссылками.Как сохранить изменения? Когда вы будете довольны своим изменением, нажмите «Сохранить», и предложенные вами изменения станут зелеными!
Как проанализировать правительственный запрос предложений на соответствие и почему это важно
Соблюдение — вот что отличает победителей от проигравших.Шутки в сторону. При написании ответа на запрос предложения (RFP) команды предложения проходят тонкую грань между подачей выигравшего предложения и тем, которое было отклонено за несоблюдение. Правительственные коммерческие предложения должны соответствовать нескольким требованиям, предусмотренным в RFP, а также быть отзывчивыми и убедительными. Излишне говорить, что давление остается и становится еще более сильным, когда ставки высоки — 20 миллионов долларов.
К счастью, существуют стандартные отраслевые методы, которые ваша организация и группа предложений могут использовать, чтобы опережать безумие и оставаться на вершине правительственного запроса предложений.Будьте готовы к соблюдению требований и назначению задач с учетом передовых методов анализа.
Что такое анализ запроса предложения?Мы рады, что вы спросили. Правительственные запросы предложений могут превышать 100 страниц, и для их проверки требуется зубчатая гребенка. Анализ тендерного документа помогает разбить контент на управляемые разделы (что-то вроде структуры декомпозиции работ для проекта) вместо того, чтобы возлагать на вас всех сразу огромную ответственность.
Анализ правительственного запроса предложения обычно происходит в начале процесса разработки предложения (и в конце хорошо продуманного развития бизнеса, если ваша организация правильно управляет процессом ответа RFP ).Мы не будем вдаваться в подробности о развитии бизнеса здесь, но стоит отметить, что написать бизнес-предложение , отвечающее требованиям соответствия, намного проще в конце полного процесса развития бизнеса.
Но вернемся к разбору. При синтаксическом анализе запроса предложения запросный документ преобразуется в соответствующий журнал, также известный как матрица соответствия. Менеджер предложений и другие члены группы развития бизнеса, такие как менеджер по захвату, просматривают RFP и создают матрицу соответствия, используя разделы RFP Технического предложения и Инструкции по подаче или Раздел L и Раздел M для RFP федерального правительства.
Матрицы соответствиячасто представляют собой бизнес-предложения, в котором излагается вопросов или разделов RFP, требующих внимания со стороны авторов предложения, и порядок ответов, которые должны быть четко отображены в бизнес-предложении. Конечно, на этом этапе вы, вероятно, можете догадаться, что анализ RFP сосредоточен на проверке требований соответствия.
Вопреки обычной практике, которую сегодня делают несколько групп предложений, этап анализа RFP на самом деле не предназначен для того, чтобы помочь вашей команде предложения узнать о потенциальном клиенте или объеме контракта.Да, об этом уже позаботился бы процесс развития вашего бизнеса.
Проанализируйте RFP , чтобы составителям предложений было легко ответить на RFP с наиболее интересным и совместимым бизнес-предложением.
Вот что должно получиться в результате анализа запроса предложения:- Заголовки разделов и номера разделов.
- Вопросы с ответами на RFP.
- Авторы, ответственные за ответы по каждому разделу
- Требования к количеству страниц
- Дополнительные инструкции, как в RFP
- Окончательные критерии оценки предложения
Матрицы соответствия в разных организациях различаются.Некоторые менеджеры предложений добавляют календарь ответов на RFP, в котором указаны сроки ответа для группы предложения и ожидания группы предложения. Наш список дает вам основы — попробуйте использовать его, чтобы соответствовать требованиям.
Ручной или автоматический синтаксический анализ: что лучше?Теперь, когда вы понимаете, что включает в себя синтаксический анализ, лучше научиться выполнять задачу самостоятельно. Мы рекомендуем обучить вашу команду и позже, чтобы помочь улучшить соответствующие стандарты для вашей организации.
Ищите те же вещи, которые мы описали выше, независимо от того, анализируете ли вы запрос предложений вручную или используете правительственное программное обеспечение RFP для автоматизации анализа запроса предложений. Проверка на соответствие, в конечном итоге, позволяет вашей команде предложения раз и навсегда определить анализ «годен / не годен», поэтому вы должны сделать его правильно с первого раза.
Разбор вручную в ExcelХороший старый лист Excel сделает всю работу за вас. Это надежный инструмент для всех вас, любителей электронных таблиц — пока вы сохраняете свою работу! Откройте лист Excel и создайте свой шаблон (поскольку шаблоны имеют значение для всех процессов управления предложениями) на основе необходимых элементов, которые мы предоставили наверху.Убедитесь, что вы настроили электронную таблицу в соответствии со стандартами компании и требованиями RFP.
Плюсы
- Надежный инструмент, доступный в Microsoft Office Suite
- Нет ограничений на добавление текстового контента
- Требуется небольшая специализация для создания
Минусы
- Ручное отслеживание
- Необходимо воссоздать для каждого предложения
- Ограниченные возможности совместного использования документов
- Ограничение размера файла
- Длительный процесс
Ручной синтаксический анализ доступен любой команде предложения, имеющей доступ к широко используемому набору приложений Microsoft Office.Обычно для создания всеобъемлющей электронной таблицы Excel с нуля не требуется высокого уровня специализации, хотя многие не предпочитают использовать Excel. Если вы не используете приложение, легко ошибиться или расстроиться. Тем не менее, он доступен для всех групп предложений, независимо от отрасли или размера компании, с минимальными возможностями для обмена документами, интеллектуального анализа или проверки соответствия.
Автоматический синтаксический анализ с помощью ZbizlinkСоответствие — это ответ, а искусственный интеллект — преимущество.Автоматический анализ запросов предложений возможен с помощью лучшего программного обеспечения для управления предложениями.
Благодаря автоматическому синтаксическому анализу ваша группа предложения может использовать удобное программное обеспечение для масштабирования процесса рассмотрения запроса предложения в вашей организации и внешних группах проверки. Вы были заинтересованы в расширении бизнеса с государством? Растет ли в вашей организации управление предложениями? Если ответ на любой из этих вопросов колеблется в сторону утвердительного ответа, то ваша группа разработки предложений должна будет рассматривать технологии как неотъемлемую часть улучшения стандартов компании и управления дополнительными процессами подачи предложений.
RFP Parser Zbizlink выполняет автоматический синтаксический анализ с помощью искусственного интеллекта. Он разбивает требования на управляемые разделы и дает менеджеру предложения возможность упорядочить информацию в соответствии с процессами компании.
Плюсы
- Одновременно обрабатывает до 50 запросов предложений
- Позволяет пользователю редактировать или добавлять информацию
- Сохраняет действия по синтаксическому анализу для последующего просмотра перед публикацией
- Анализирует содержимое примерно за 30 секунд
- Доступно на сайте
Минусы
- Для начала работы нужен Zbizlink
- Заголовки разделов предназначены для государственных и коммерческих запросов предложений
- Не обрабатывает документы Excel RFP
Автоматический синтаксический анализ документов упрощает рассмотрение нескольких предложений, помогая оптимизировать принятие решения «Не годен / не годен», назначение задач, проверку соответствия и процесс управления предложениями.Команде вашей заявки потребуется дополнительное преимущество для управления несколькими правительственными запросами предложений и обеспечения того, чтобы соблюдение требований всегда оставалось наивысшим приоритетом. Более того, Zbizlink соответствует процессам вашей компании и начинает изучать поведение пользователей — рассмотрение запросов предложений в разных командах со временем становится лучше.
совместных переходных моделей для морфо-синтаксического анализа: стратегии синтаксического анализа для MRL и практический пример современного иврита | Труды ассоциации компьютерной лингвистики
Исследования НЛП в последние годы показали возрастающий интерес к синтаксическому анализу типологически различных языков, о чем свидетельствует, например, инициатива универсальных зависимостей 1 Nivre et al.(2016). В частности, большое внимание уделяется синтаксическому анализу морфологически богатых языков (MRL), которые существенно отличаются от английского по своей структуре и характеристикам (Tsarfaty et al., 2010).
В MRL грамматическая информация, обычно выражаемая с использованием порядка слов в английском языке, часто проявляется во внутренней сложной структуре слов. Слова в MRL могут нести, помимо лексического содержания, функциональные аффиксы и клитики, которые соответствуют дополнительной информации.В современном иврите, например, глагол со склонением « ahbtih » 2 (любимый + 1pers.singular.past + 3pers.feminine.singular) соответствует трем различным грамматическим функциям: подлежащему «I», сказуемому «Любил» и прямой объект «ее». Точно так же испанский dámelo соответствует предикату, косвенному объекту и прямому объекту, например, «дай мне». Таким образом, в MRL морфологический анализ (MA), который переводит необработанные токены, разделенные пробелами, в синтаксически релевантные «словесные» единицы, является необходимым условием для любой синтаксической или семантической последующей задачи.
Однако необработанные токены с разделителями-пробелами в MRL часто очень неоднозначны. В иврите, арабском и других семитских языках ситуация осложняется еще и тем, что в письменных текстах отсутствуют диакритические знаки. Еврейский знак «fmn», , например, может быть прочитан как существительное «масло», прилагательное «жир», глагол «смазанный», последовательность «тот» + «из» или фраза «их». + «Имя», только одно из которых имеет отношение к в контексте .Это имеет явные последствия для синтаксического анализа зависимостей. На рисунке 1 показана решетка, которая отражает все возможные анализы еврейской фразы «bclm hneim», буквально: «в их тени приятное», переведенное «в их приятной тени». Каждая дуга решетки соответствует потенциальному узлу в дереве зависимостей. Темными кружками отмечены границы морфем, двойные кружки — границы токенов. Верхнее дерево отображает правильный синтаксический анализ. В нижнем дереве неправильно разрешенные токены приводят к неправильному синтаксическому анализу.
Рисунок 1:
Морфологические и синтаксические взаимодействия при анализе фразы на иврите « bclm hneim » согласно аннотации SPMRL на иврите.
Рисунок 1:
Морфологические и синтаксические взаимодействия при анализе фразы на иврите « bclm hneim » согласно аннотации SPMRL на иврите.
Предыдущие кампании по оценке анализа зависимостей (Buchholz and Marsi, 2006; Nivre et al., 2007) предположили, что правильный морфологический анализ и устранение неоднозначности (MA&D) входного потока известны заранее. Однако в реалистичных сценариях сквозного анализа это, конечно, не так. Чтобы преодолеть это, были созданы конвейерные архитектуры, в которых MA&D предшествует синтаксическому анализу. Эти конвейеры неоптимальны, поскольку они страдают от распространения ошибок, и поскольку локальный линейный контекст, доступный для автоматической MA&D, может быть недостаточным для точного морфологического разрешения неоднозначности.Для этого может потребоваться реальный синтаксический контекст (Царфаты, 2006). Чтобы разрешить эту очевидную петлю, где требуется морфологический анализ для синтаксического синтаксического анализа, требуется синтаксический анализ и для морфологического разрешения неоднозначности , Царфати (2006) предположил, что объединяет морфосинтаксический анализ , где морфологическая информация может помочь в устранении синтаксической неоднозначности и наоборот. может быть лучше подходит.
Эта совместная морфосинтаксическая гипотеза была принята и успешно подтверждена в контексте синтаксического анализа фразовой структуры семитских языков (Goldberg and Tsarfaty, 2008; Cohen and Smith, 2007; Green and Manning, 2010).Для анализа зависимостей Bohnet and Nivre (2012) и Bohnet et al. (2013) представляют не зависящие от языка фреймворки на основе переходов для совместного синтаксического анализа и маркировки входных слов, но без решения сложной проблемы ретокенизации неоднозначных входных токенов. Совсем недавно Seeker и Centinoglu (2015) представили основанную на графах структуру для решетчатого синтаксического анализа турецкого языка, также охватывающую морфологическую сегментацию. В их системе используется подход «продукта экспертов», в котором морфологические пути и деревья зависимостей обрабатываются с помощью двух различных моделей (линейная модель над биграммами для MD и модель дугового фактора для зависимостей), достигая согласия через установку двойной декомпозиции.
В этой работе мы представляем новую, не зависящую от языка, основанную на переходах структуру для сквозного морфосинтаксического анализа зависимостей. Платформа объединяет морфологический и синтаксический компоненты в общий синтаксический анализатор, охватывающий единую систему переходов, единую целевую функцию, совместное обучение и совместное декодирование. Мы применяем эту систему для анализа современного иврита и эмпирически подтверждаем, что прогнозирование MA&D в совместных настройках улучшается по сравнению с автономным MA&D и недавно опубликованными результатами MA&D на иврите.Наша система дополнительно улучшает результаты сквозного синтаксического анализа зависимостей по сравнению с существующими современными синтаксическими анализаторами в сценариях конвейера, она значительно превосходит совместный синтаксический анализатор Seeker и Centinoglu (2015) и существенно превосходит синтаксический анализатор зависимостей Голдберг и Эльхадад (2010) до сих пор считались стандартом де-факто для анализа зависимостей на иврите.
Таким образом, вклад этой статьи тройной.Во-первых, мы определяем не зависящий от языка морфосинтаксический синтаксический анализатор суставов в структуре, основанной на переходах. Во-вторых, мы эмпирически подтверждаем, что MA&D выигрывает от синтаксического анализа, а в реалистичных сценариях сквозного синтаксического анализа также и наоборот. Наконец, мы представляем новый набор сильных результатов сквозного синтаксического анализа иврита и предлагаем реализацию совместного синтаксического анализатора с открытым исходным кодом, не зависящую от языка, для дальнейшего исследования совместных стратегий морфосинтаксического синтаксического анализа. Эта статья организована следующим образом.В разделе 2 мы представляем нашу формальную структуру (2.1), морфологическую модель (2.2), синтаксическую модель (2.3) и совместную структуру (2.4). В разделах 3 и 4 представлены наши эксперименты и анализ соответственно. В Разделе 5 обсуждаются связанные и будущие работы, а в Разделе 6 подводятся итоги.
Мы приводим сквозной морфосинтаксический синтаксический анализ как функцию предсказания структуры F: X → Y, где x∈X — это последовательность необработанных входных токенов, а y∈Y — представление зависимости, где узлы в дереве соответствуют однозначным морфосинтаксические единицы мы обозначаем как морфем . 3
Мы предполагаем, что F реализован в структуре на основе переходов, дополненной методом прогнозирования структуры Zhang and Clark (2011). Начнем с совершенно общего определения переходной системы как четверной S = ( C , T , c s , C t ), с C набор конфигураций, T набор переходов, c s функция инициализации и C t ⊂ C набор конфигураций клемм.Затем мы определяем различные экземпляры S для различных ( морфологических, синтаксических, морфосинтаксических ) задач синтаксического анализа. В каждом экземпляре последовательность переходов y для x представляет собой последовательность конфигураций, которые получаются путем последовательного применения переходов t 1 … t n ∈ T . То есть, начиная с начальной конфигурации c 0 = c s ( x ), мы находим y = c 0 ,…, c n такой, что c i +1 = t i +1 ( c i ) и c n 9 т .Таким образом, каждое значение x изображает последовательность решений, которая составляет достоверный анализ для x на соответствующем лингвистическом уровне.
Для каждой задачи мы используем целевую функцию F ( x ) следующим образом, где GEN ( x ) содержит все последовательности переходов, которые генерируют соответствующих кандидатов:F (x) = argmaxy∈GEN (x) Оценка (y) = argmaxy∈GEN (x) Φ (y) ⋅ω → = argmaxy∈GEN (x) ∑cj∈y∑iωiφi (cj).
Для вычисления Score ( y ), y отображается в глобальный вектор признаков Φ ( y ) размером d , умноженный на вектор весов ω → того же размера. Глобальный вектор признаков Φ ( y ) состоит из локальных векторов признаков, каждый из которых определяется с помощью набора функций {φi: C → N} i = 1d, которые подсчитывают вхождения заранее заданного шаблона в заданной конфигурации в y .Следуя Чжану и Кларку (2011), мы изучаем вектор весов ω → ∈Rd с помощью обобщенного персептрона , используя усредненный вариант раннего обновления Коллинза и Рорка (2004).
Декодирование основано на алгоритме поиска луча , в котором в луче поддерживается ряд последовательностей-кандидатов с высокими показателями, чтобы уменьшить безвозвратные ошибки прогнозирования, которые характеризуют процедуры жадного поиска.На каждом этапе система переходов применяет все переходы ко всем кандидатам и сохраняет B кандидатов с наивысшим баллом. Во время обучения алгоритм перцептрона проходит через корпус с золотыми аннотациями. Каждое предложение анализируется (декодируется) с использованием последних известных весов, и если результат анализа отличается от золотого, веса обновляются. Обучение прекращается, когда начинается переобучение.
Наша отправная точка для определения морфологической неоднозначности (MD) — это переходная система Мора и Царфати (2016), которая в настоящее время признана современной для ивритского MA&D. 4 Вход в систему представляет собой решетку L , которая фиксирует диапазон допустимых морфологических анализов для входных токенов x = x 1 ,…, x k , как показано в середине рисунка 1. Цель системы MD состоит в том, чтобы выбрать последовательность смежных дуг в L , которая представляет морфологическое устранение неоднозначности x в контексте.
Формально мы определяем для каждого токена x i его сетку-токен L i = MA ( x i arc4), где в L i соответствует потенциальному узлу в дереве зависимостей.Каждая дуга решетки имеет морфосинтаксическое представление (MSR), которое мы определяем как кортеж m = ( b , e , f , t , g ) с b и . e начальный и конечный индексы в L , f форма, t тег части речи и g набор грамматических свойств attribute: value. L = MA ( x ) — решетка предложений, полученная объединением решеток токенов сверху вниз L = MA ( x 1 ) ∘… ∘ MA ( x к ).Теперь L представляет собой полный спектр действительных морфологических анализов, применимых к x . 5
Конфигурация для любого входа x в системе MD состоит из его решетки предложений L = MA ( x ), индекса n , представляющего внутренний узел (темный кружок) в L , мы находимся на и индекс i , представляющий отсчитываемый от 0 индекс токена (двойной кружок) в L , в то время как M представляет собой набор устраненных неоднозначности MSR (выбранные дуги): Функция начальной конфигурации c s устанавливает L = MA ( x ), n = нижний ( L ), i = 0 и M = ∅ .Для прохождения решетки L снизу вверх мы определяем открытый набор переходов, используя шаблон перехода MD s , с s = (_, _, _, t , g ) с указанием делексикализованной проекции (любой) дуги решетки ( b , e , f , t , g ).MD: (L, p, i, M) → (L, q, j, M∪ {m}).
(1) Этот переход выбирает одну дугу решетки в заданной позиции.Теперь, если p — наша текущая позиция в решетке, а m = ( p , q , f , t , g ) — выбранная дуга, тогда j = i + 1, если q находится на границе маркера (двойной круг), и j = i , если это не так.Набор конфигураций клемм определяется как C t = {( L , верх ( L ), | x |, M )}, где M = { м 1 , м 2 ,…., m l } содержит полностью устраненный путь от MSR (выбранных дуг) до L .
Чтобы найти этот путь на основе данных, мы определяем параметрическую модель, которая оценивает все переходы, которые могут быть применены на каждом шаге. Мы определяем свойства f (форма), t (тег pos), g (морфологический атрибут: пары значений), путь (путь в ранее устраненных неоднозначных решетках токенов) и морфов ( набор исходящих морфем текущего узла), и мы используем комбинации этих свойств униграммы, биграммы и триграммы в качестве функций для модели обучения. 6 Наш декодер поиска луча затем применяет в каждой точке решетки все возможные переходы и в этой точке выбирает кандидатов с наивысшей оценкой B . Те, которые не достигают отметки B , падают с балки.
Важно, | M |, количество дуг решетки в пути на каждом этапе заранее неизвестно, поскольку различные решения по устранению неоднозначности между границами маркеров могут иметь разную длину пути.Это можно увидеть на решетке на рис. 1, где длина пути варьируется от 4 до 7 дуг. Это сложный вопрос, поскольку он нарушает основное предположение декодирования поиска луча — что количество переходов является детерминированной функцией входа и известно заранее. Такие несоответствия длины могут привести к предпочтению коротких последовательностей в луче из-за раннего достижения конечной цели или к предпочтению длинных последовательностей из-за искусственного завышения оценок на основе множества функций.
Чтобы решить эту проблему, мы принимаем решение, предложенное Мором и Царфати (2016), используя специальный переход ENDTOKEN (ET) , приведенный в (2), который явно увеличивает i при достижении границы токена в L . 7ET: (L, n, i, M) → (L, n, i + 1, M).
(2) В отличие от других переходов, ET имеет свой собственный набор функций (размером d ‘). Помимо увеличения i , ET вызывает изменение порядка кандидатов в луче на каждой границе маркера. Мор и Царфати (2016) показывают, что при использовании этого якоря особенности перехода ET обеспечивают противовес эффектам последовательностей различной длины и повышают точность MD на иврите. Последовательность перехода MD, таким образом, становится объединением непересекающихся наборов конфигураций y = y md ∪ y et , и Оценка ( y ) выглядит следующим образом, где ωjmdφm конфигурации очков, полученные в результате переходов MD, а также ωjetφet для переходов ET:Score (y) = ∑i = 1dωimdφimd (ymd) + ∑j = 1d′ωjetφjet (пока)
= ∑ck∈ymd∑i = 1dωimdφimd (ck) + ∑cl∈yet∑j = 1d′ωjetφjet (cl).
(3)Учитывая последовательность выбранных дуг решетки для входной последовательности x , мы можем определить представление синтаксической зависимости для x как дерево зависимостей, где каждая дуга решетки соответствует узлу в дереве зависимостей. Пусть R будет набором типов зависимости и пусть M = m 1 … m l будет последовательностью l дуг, выбранных компонентом MD. 8 Обозначим график зависимости для последовательности M = m 1 … m l as G M = ( V , A M ), где V M — набор узлов, соответствующих дугам M и A M ⊆ V 70 90 × R × V M представляет собой набор маркированных дуг между элементами V M .
Конфигурация системы дуги для морфологической последовательности M = m 1 … m n — триплет, где σ — стопка морфем m i ∈ V S , β — буфер морфем m i ∈ V S , а A — это набор зависимостей m i , r , m j ) ∈ V S × R × V S .Конфигурация представляет собой частичный анализ входного предложения, где морфемы в стеке σ являются частично обработанными морфемами, морфемы в буфере β — это те, которые ожидают обработки, а набор дуг A представляет собой частично построенное дерево зависимостей (Kübler et al., 2009, глава 3). Если не указано иное, набор конфигураций клемм: C t = {( σ , β , A )}, где β = [] и | σ | = 1. 9
В литературе по синтаксическому анализу зависимостей для английского языка есть различные варианты определения переходов по таким конфигурациям. В частности, три системы перехода были успешно применены к английскому, а также к другим языкам (см. Ballesteros and Nivre [2016]):
Arc Standard: Простой метод пошагового увеличения слева направо снизу вверх. синтаксический анализ, предложенный в Nivre (2004).Мы принимаем определение Кюблера и др. (2009).
Arc Eager: Следуя Abney и Johnson (1991), Arc Eager определяет вариант Arc Standard, который позволяет легко прикреплять правого иждивенца к его голове, позволяя присоединяться к нему большему количеству иждивенцев. Мы принимаем определение Кюблера и др. (2009).
Arc (Z) Eager: При воспроизведении современных результатов, представленных Zhang и Nivre (2011) для английского языка, мы обнаружили в коде вариант Arc Eager, который мы называем Arc (Z) Eager, который имеет интересные тонкие вариации от Arc Eager, включая второй стек, содержащий головные узлы, и определенные жесткие ограничения на применение нескольких переходов. 10
Эмпирическое исследование, проведенное Nivre (2008), сравнивает производительность Arc Standard и Arc Eager для 13 языков, среди которых арабский и турецкий, оба считаются MRL с некоторой степенью свободы порядка слов. Для этих языков Arc Standard немного превзошел Arc Eager. С другой стороны, наши предварительные эксперименты с английским и ивритом показывают, что вариант Arc ZEager всегда превосходит Arc Eager.Однако вопрос, какой из двух, Arc-Standard или Arc-ZEager, больше подходит для анализа иврита, остается открытым для нашего эмпирического исследования в разделе 3.
Существенным вкладом Zhang и Nivre (2011) является их предложение набора из богатых нелокальных функций (RNF) для Arc ZEager, добавление информации более высокого порядка, ранее обнаруживаемой только в анализаторах на основе графов. Чтобы облегчить справедливое сравнение Arc Standard и Arc (Z) Eager, мы должны адаптировать набор функций Zhang and Nivre (2011) к другой системе дуги (насколько это возможно) и к другому типу языка. .В частности, набор RNF зависит от порядка слов за счет явного кодирования направления дуги. Мы обращаемся к зависимости RNF от порядка путем определения параллельного набора функций, который подходит для более гибкого порядка слов в MRL и применим к Arc-Standard. Мы называем этот набор функций богатых лингвистических функций (RLF). Суть этих двух наборов функций одинакова, но мы заменяем функции, основанные на позициях узлов, на функции, основанные на помеченных грамматических функциях этих узлов. 11
Чтобы сконструировать наши особенности, мы определяем свойства, которые фиксируют лингвистическую информацию выборочных предпочтений и фреймов подкатегории (Tesnière, 1959; Chomsky, 1965). Чтобы захватить распределительную характеристику кадров субкадра, мы определяем sf p как мультимножество тегов части речи зависимых от данной головы.Чтобы захватить функциональную характеристику кадров субкадра, мы определяем sf f , ссылаясь на мультимножество функциональных меток всех зависимых от данной головки. Для валентности мы определяем свойства v sf , относящиеся к количеству иждивенцев данной главы. Для захвата предпочтений выбора в средах с гибким порядком слов мы определяем не зависящие от порядка двухкомпонентные признаки меченой зависимости, генерируемые отдельно для каждого зависимого.
Наконец, мы дополняем синтаксические особенности морфологическими свойствами. Наш оператор дополнения позволяет создавать несколько экземпляров одного и того же объекта с морфологическими свойствами и без них.
Учитывая наши морфологические и синтаксические компоненты, мы стремимся к такой интеграции, чтобы морфологическая информация способствовала устранению синтаксической неоднозначности и наоборот.
Мы предлагаем буквально встроить две автономные конфигурации в единую конфигурацию и применять переходы с помощью согласованной логики, которую мы называем стратегией , которая выбирает, какой процессор применять в данном состоянии.
Формально пусть c md и c dep будут конфигурациями анализатора MD и зависимостей, как определено в разделах 2.2 и 2.3 соответственно. Определим совместную конфигурацию следующим образом:cj = (cmd, cdep) = ((L, n, i, M), (σ, β, A)).
(4)Мы инициализируем встроенную конфигурацию MD c md с функцией инициализации системы перехода MD, как определено в разделе 2.2, но оставляем c dep пустым, с σ = β = [] пустой стек и буфер.Также, как и раньше, в c dep , A = ∅ . Конфигурация c j является терминальной тогда и только тогда, когда c md и c dep являются конфигурациями терминалов своих соответствующих систем.
Пусть T = (Tmd, Tdep) — пара наборов переходов системы переходов MD и анализа зависимостей, соответственно, пусть C = {Cmd, Cdep} содержит наборы возможных нетерминальных конфигураций, и пусть Ct = {Ctmd , Ctdep} содержат соответствующие наборы конфигураций терминала.Совместная стратегия — это функция, которая, учитывая нетерминальную конфигурацию сустава, выбирает ровно одну систему перехода для воздействия:В MRL токены вне словарного запаса (OOV) представляют собой серьезную проблему для синтаксического анализа. Необработанный токен мог не наблюдаться во время обучения, хотя все его морфемы наблюдались в других контекстах. Чтобы оценить влияние таких элементов OOV на качество синтаксического анализа иврита, мы оцениваем систему в двух разных сценариях.В первом сценарии с добавлением мы проверяем, что каждая решетка содержит морфологический анализ золота. То есть, если золотой путь отсутствует в L = MA ( x ) (следовательно, OOV), мы автоматически вливаем золотой путь в L . Мы сравниваем это с несвязанными сценариями , где мы используем реалистичный морфологический анализатор с его (неполным) лексическим охватом как есть, в соответствии с Adler and Elhadad (2006).
Во всех экспериментах мы использовали луч размером 64, который в наших предварительных экспериментах на dev дал лучшие результаты для совместных моделей, чем луч 32, и в любом случае не хуже, чем луч 128.Чтобы избежать переобучения и недообучения, мы определяем условие остановки для процедуры обучения, которое мы тестируем на каждой итерации обучения. Во время обучения мы используем скользящее окно из трех итераций и выбираем первую модель, которая предшествует двум последовательным падениям оценок при разработке.
Для моделей конвейера мы тестируем различные условия остановки для морфологической и синтаксической моделей, каждая из которых основана на своих собственных автономных оценках.Для совместных моделей мы проверяем условие остановки относительно одной общей зависимости F 1 баллов, которые мы вскоре определим.
Оценка совместных морфо-синтаксических зависимостей синтаксического анализа производительности является нетривиальной задачей, потому что золотые деревья и деревья синтаксического анализа могут иметь разное количество узлов, что препятствует применению стандартных оценок привязанности; достаточно, чтобы некорректная сегментация произошла в начале последовательности, тогда отдельные индексы в оставшейся части предложения считают остальные дуги неправильными (Царфати и др., 2012).
Проиллюстрируем этот эффект. Рассмотрим фразу на иврите « bbit » (в переводе «в доме»), которая появляется как один символ, разделенный пробелами. Теперь рассмотрим две следующие альтернативы MD, с скрытым определенным артиклем на иврите и без него. Мы также включаем сюда индексы неоднозначных морфем в их линейном порядке:
Далее предположим, что оба дерева зависимостей Gold и Predicted содержат правильных дуг зависимости между b («in») и битов («house») с меткой pobj .Проще говоря, дуги, которые будут сравниваться с целью оценки:
Gold Dep: pobj (1,3), det (3,2)
Predicted Dep: pobj ( 1,2).
Таким образом, предсказанная дуга pobj будет считаться ошибкой, даже если соотношение между формами правильное, и, соответственно, UAS и LAS будут равны 0.
Чтобы решить эту проблему, мы определяем меру точности F 1 относительно форм ребер дуги, а не их узловых индексов .Формально пусть M p будет прогнозируемым морфологическим разрешением x , а A p будет прогнозируемым деревом зависимостей для M p . Аналогично, пусть M g , A g будет золотым стандартом морфологического разрешения неоднозначности и дерева зависимостей x . Теперь заменяем индекс каждого узла в дугах A p , A g с формой соответствующей морфемы в M p и M г .Пусть J p , J g будет основанными на форме (а не на основе индексов) дугами предсказанного и золотого представлений x . Мы сообщаем как о маркированном, так и о немаркированном F 1 как: 15Pr = | Jp∩Jg || Jp |; Re = | Jp∩Jg || Jg |; F1 = 2 × Pr × RePr + Re.
В нашем примере измененные дуги теперь будут:Gold Dep: pobj (b, bit), det (bit, h)
Predicted Dep: pobj (b, bit).
Теперь синтаксическому анализатору будет засчитано, что он правильно определил дугу pobj , по желанию, и оценки зависимости будут: Pr = 1, Re = 0,5 и F 1 = 0,67.
Таблица 4:Совместный морфо-синтаксический анализ набора тестов для современного иврита с незаплавленными (реалистичными) решетками.
/88331/| Стратегия . | Система . | MD F 1 Полный / POS . | Dep F 1 Без маркировки . | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Автономный | M&T 2016 | 84,89 / 87,53 | н / п / н / д | ||||||||||||
| Трубопровод | 3 84 | 6/871533 | Стандартный70 / 67,83 | ||||||||||||
| Трубопровод | ZEager | 84,89 / 87,53 | 74,43 / 68,33 | ||||||||||||
| MDFirst | MDFirst | ZEager | 85,92 / 89,02 | 75,37 / 69,28 | |||||||||||
| ArcGreedy 3 | Стандартный | 85.98 / 89,08 | 75,73 / 69,23 | ||||||||||||
| ArcGreedy 3 | ZEager | 85,85 / 88,92 | 75,30 / 69,13 |
| Система . | MD F 1 Полный / POS . | Dep F 1 Без маркировки . | |||
|---|---|---|---|---|---|
| Автономный | M&T 2016 | 84.89 / 87,53 | н / д / н / д | ||
| Трубопровод | Стандартный | 84,89 / 87,53 | 73,70 / 67,83 | ||
| Трубопровод | /68.33 | ||||
| MDFirst | Standard | 85,79 / 88,81 | 75,49 / 69,41 | ||
| MDFirst | ZEager | 75,37 / 69,28 | |||
| ArcGreedy 3 | Стандартный | 85.98 / 89.08 | 75.73 / 69,23 | 85,85 / 88,92 | 75,30 / 69,13 |
В таблице 1 представлены результаты анализа для инфузированных морфологических решеток; то есть неоднозначные MA-решетки, которые гарантированно включают в себя правильный MD-путь.В этих экспериментах мы видим, что результаты MD в совместных стратегиях синтаксического анализа (MDFirst, ArcGreedy) всегда улучшают результаты автономного / конвейерного анализа MD. В частности, все результаты MD по совместным стратегиям очень близки. Мы наблюдаем лишь незначительное преимущество Arc-Zeager перед Arc-Standard для обеих совместных стратегий. К сожалению, это увеличение точности MD происходит за счет синтаксиса, где мы наблюдаем небольшое снижение (до 0,5 балла в [un] с меткой F 1 ) при переключении с конвейерной стратегии на совместную.
Мы подтверждаем эту тенденцию на тестовом наборе в таблице 2, где мы используем те же модели в настройках , встроенных в , для синтаксического анализа стандартного тестового набора . Для MD все совместные результаты лучше, чем соответствующие конвейеры (хотя теперь Arc-Standard немного улучшает Arc-Zeager в стратегии ArcGreedy), в то время как результаты анализа зависимостей падают в совместных сценариях (немного больше, чем в dev).
Таблицы 3 и 4 представляют результаты синтаксического анализа для более интересного сценария, реалистичного сценария синтаксического анализа, в котором мы используем неслитых решеток — неоднозначных решеток, полученных с помощью существующего морфологического анализатора с широким охватом, которые не всегда (и не могут быть) гарантированы всегда. укажите правильный путь. Как и ожидалось, как в наборе для разработчиков (таблица 3), так и в тестовом наборе (таблица 4) результаты падают по сравнению с соответствующими сценариями с добавлением (таблицы 1 и 2 соответственно), поскольку некоторые элементы из правильных путь и дерево больше не доступны в области поиска.В то же время интересно отметить, что как для dev , так и для test , все оценки MD (Full / POS) , а также оценок зависимостей (без / помеченных) лучше при совместном разборе. Конкретные различия между совместными стратегиями и системами перехода не имеют большого значения — устойчивая эмпирическая тенденция состоит в том, что переключение с конвейера на соединение улучшает производительность как MD, так и анализа зависимостей.
Интересно спросить, почему в сценарии с добавлением , на dev и test результаты синтаксического анализа зависимостей в совместных стратегиях падают относительно соответствующих конвейеров.Оказывается, в случае, если правильный анализ редкого (OOV) токена был искусственно введен в решетку, обучение на этих решетках может оказаться неверным. Внедрение правильного, но редкого MSR может привести к искусственной «уверенности» в его подходящем синтаксическом контексте. Затем, если синтаксический анализатор не применяет надежную статистику к общему поведению редких элементов / элементов OOV в различных синтаксических контекстах (как это было бы в случае совместных несвязанных сценариев ), выбор введенного MD может привести к неверному синтаксическому решению.
Главный вывод наших экспериментов заключается в том, что совместное морфологическое устранение неоднозначности и синтаксический анализ в этой основанной на переходах структуре предпочтительнее, чем настройки конвейера, в соответствии с гипотезой о том, что синтаксическая информация помогает устранению морфологической неоднозначности. Кроме того, обнадеживает тот факт, что при синтаксическом анализе незаполненных решеток , как и в более реалистичном сценарии, результаты синтаксического анализа зависимостей улучшаются для сценариев конвейера, подтверждая выводы Seeker и Centinoglu (2015) в основанных на графах структурах и Коэна и Смита. (2007) и Goldberg and Tsarfaty (2008) в синтаксическом анализе фразеологической структуры.
Чтобы пролить больше света на конкретные способы, которыми объединенная система улучшает производительность по конвейеру, мы провели качественный анализ ошибок в 100 предложениях из стандартного набора разработчика Modern Hebrew при анализе в более реалистичном сценарии unfused . Более конкретно, мы выбрали 100 предложений из проанализированного корпуса, и лингвист вручную отнес каждую ошибку к одной из 10 лингвистических категорий.Затем мы сгруппировали категории по четырем различным типам.
- •
Ошибки ТИПА 1 включают истинную семантическую неоднозначность, когда для устранения неоднозначности требуются дополнительные семантические и мировые знания.
- •
Ошибки ТИПА 2 включают категории, которые выходят за пределы различных уровней лингвистической структуры, например, когда ошибки морфологической сегментации влияют на синтаксическое устранение неоднозначности.
- •
Ошибки ТИПА 3 включают ошибки синтаксического анализа, которые проистекают из идиосинкразии данных и особенностей схемы аннотаций SPMRL,
- •
Ошибки ТИПА 4 (другие) включают ошибки синтаксического анализа, относящиеся к лингвистическим структурам, характеризующим семитские явления.
Таблица 8 показывает для каждой категории ошибок количество (и процент) появления этой ошибки в конвейере по сравнению с параметрами соединения. Наиболее результат заключается в том, что тип, который показывает наибольшее уменьшение совместных сценариев по сравнению с конвейерными сценариями, принадлежит ТИПУ 2, отражая явления, непосредственно связанные с морфо-синтаксическим интерфейсом. Более того, мы также видим уменьшение количества ошибок, связанных с лексико-синтаксическим интерфейсом (например,g., устранение неоднозначности прикрепления PP), которые, как оказалось, также выигрывают от совместных настроек. С другими типами ошибок нет явного преимущества для совместного анализа, и мы не ожидаем его. Ошибки ТИПА 3 связаны с несоответствиями в наборе поездов, неполными спецификациями или ошибками в золотых деревьях. Ошибки ТИПА 4 проистекают из лингвистических явлений, которые труднее устранить неоднозначность, и они одинаково трудны для разных сценариев.
Monolingual MA&D для современного иврита ранее рассматривался в автономных настройках с использованием скрытых марковских моделей (Bar-haim et al., 2008; Адлер, 2007). Хотя эти результаты подходят для некоторых последующих приложений, использование MA&D Адлера для анализа зависимостей, например, значительно снижает производительность анализа (Goldberg and Elhadad, 2010). Совсем недавно Мор и Царфати (2016) представили автономную MA&D на основе переходов, которая совместно решает морфологическую сегментацию, тегирование и присвоение признаков, представив новую современную MA&D на иврите, что послужило отправной точкой для нашего исследования.
Что касается сквозного синтаксического анализа зависимостей для иврита, Голдберг и Эльхадад (2010) были первыми, кто оценил влияние предсказанной морфологии по сравнению с морфологией золота в различных (основанных на переходах, графических, простых) фреймворках. .Они продемонстрировали значительную потерю точности для всех моделей в условиях прогнозируемой морфологии и в заключение предложили попробовать совместную обработку. Недавно Straka et al. (2016) представили UDPipe, набор инструментов с автономными компонентами для морфологического анализа, сегментации, тегирования, назначения функций и анализа зависимостей — опять же с использованием конвейерной архитектуры, без возможности чередования различных решений, как мы стремимся сделать здесь. Эта работа направлена на охват всех этапов UDPipe, но в рамках объединенной архитектуры , позволяющей использовать информацию с любого уровня при устранении неоднозначности другого.
Совместная морфологическая и синтаксическая обработка была рассмотрена в контексте синтаксического анализа фразовой структуры для семитских языков, демонстрируя эмпирические преимущества перед конвейерными архитектурами (Goldberg and Tsarfaty, 2008; Cohen and Smith, 2007; Green and Manning, 2010). В контексте анализа зависимостей Bohnet and Nivre (2012) и Bohnet et al. (2013) интегрировали теги и синтаксический анализ зависимостей, улучшив современную точность для набора типологически разных языков.Andor et al. (2016) используют систему совместных переходов, предложенную Bohnet и Nivre (2012), и улучшают ее с помощью глобально нормализованной нейронной сети. Эти системы обращаются к совместному морфо-синтаксическому анализу слов с устранением неоднозначности, но без решения проблемы сегментации и устранения неоднозначности необработанных входных токенов.
Seeker и Centinoglu (2015) исследуют идею совместного морфологического и синтаксического анализа, включая морфологическую сегментацию, в графической структуре.Их система объединяет два автономных компонента, которые достигают согласия через установку двойной декомпозиции. Однако они сообщают о неоптимальной производительности в стандартном тесте для иврита. Было показано, что для различных задач синтаксического анализа китайского языка совместные системы сегментации слов и синтаксического анализа превосходят параметры конвейера (Li et al., 2011; Zhang et al., 2014), но эти системы предполагают переходы по последовательностям на основе символов одинаковой длины. , и поэтому они не применимы к настройке решетчатых путей переменной длины, как показано на рисунке 1.
С ростом интереса к глубокому обучению для НЛП (Goldberg, 2016) исследования по синтаксическому анализу зависимостей стремятся заменить спроектированные модели функций нейронными сетями, которые автоматически создают модель (Chen and Manning, 2014; Zhou et al., 2015; Andor и др., 2016). Кроме того, концепция вложения слов, введенная Миколовым и соавт. (2013) позволяет словам иметь векторные представления, так что синтаксические и семантические сходства воплощаются в векторном пространстве.Однако такие архитектуры не сразу применимы к синтаксическому анализу иврита и других MRL. Предварительное обучение встраиванию слов для неоднозначных входных токенов нетривиально, если только не прибегать к конвейерным сценариям «сначала сегментация». Точно так же архитектуры синтаксического анализа, основанные на RNN, требуют морфологически неоднозначных форм в качестве входных данных, что не позволяет синтаксису улучшать морфологическое разрешение неоднозначности, как мы здесь утверждаем.
В будущем мы намерены дополнить архитектуру, которую мы представляем здесь, моделями нейронных сетей как для морфологических, так и для синтаксических моделей таким образом, чтобы они могли эффективно взаимодействовать и влиять друг на друга, в надежде привести к дальнейшим улучшениям в обе задачи.
Проблема 22234: urllib.parse.urlparse принимает любое ложное значение в качестве URL-адреса
Я вижу некоторые результаты при запуске urlparse с примененным патчем urlparse_empty_bad_arg_deprecation2.patch:
>>> urllib.parse.urlparse ({})
__main __: 1: DeprecationWarning: использование {} устарело
__main __: 1: DeprecationWarning: использование "" устарело
ParseResultBytes (схема = b '', netloc = b '', path = b '', params = b '', query = b '', fragment = b '')
>>> urllib.parse.urlparse ('', b '')
__main __: 1: Устарело Предупреждение: использование b '' устарело
/home/poleto/SCMws/python/latest/cpython/Lib/urllib/parse.py:378: DeprecationWarning: использование b '' устарело
splitresult = urlsplit (URL, схема, allow_fragments)
ParseResult (scheme = b '', netloc = '', path = '', params = '', query = '', fragment = '')
Будут ли байты устаревшими при использовании в качестве default_schema?
>>> urllib.parse.urlparse (b '', '')
ParseResultBytes (схема = b '', netloc = b '', path = b '', params = b '', query = b '', fragment = b '')
Разве не должно жаловаться, что типы разные? На самом деле это так, если вы не укажете пустые строки:
>>> urllib.parse.urlparse (b'www.python.org ',' http ')
Отслеживание (последний вызов последний):
Файл " |
Vyrill, победитель конкурса TC Early Stage Pitch-Off, помогает брендам находить и использовать видеообзоры, созданные пользователями.
Vyrill помогает брендам находить и использовать видеообзоры, созданные настоящими клиентами и пользователями.Компания представила свой продукт на TechCrunch Early Stage: Marketing & Fundraising, где обошла девять других компаний и выиграла конкурс. Судьи были впечатлены новаторским подходом Vyrill и инновационными технологиями поиска и фильтрации релевантных видео.
Это борьба компаний любого размера. Пользовательский контент пользуется большим спросом, поскольку его подлинность часто очевидна и, следовательно, важна. Но задача состоит в том, чтобы быстро и эффективно найти идеальное видео.Прямо сейчас это обычно включает поиск видео по его названию, а затем просмотр всего видео — случайный и трудоемкий процесс.
Как подчеркнул в ходе своей презентации генеральный директор Vyrill Аджай Бам, бренды все чаще обращаются к обычным людям для видеорекламы. Вместо привлекательных маркетинговых видеороликов бренды чаще создают лицензионный и маркетинговый контент, создаваемый реальными пользователями продукта. Но обнаружение — сложная задача, и инструменты поиска, встроенные в видеоплатформы, анализируют только текст в заголовке и описании.Вирилл утверждает, что нашел решение. Например, с помощью технологии Vyrill L’Oréal может сопоставить миллионы видеороликов YouTube со всем своим каталогом продуктов, упорядочивая каждое видео по соответствующей категории продуктов. Это позволяет L’Oréal находить и использовать лучшие видеоролики, созданные пользователями, в маркетинговых целях компании. Кроме того, с помощью системы Vyrill L’Oréal может копать и идентифицировать созданный пользователями контент, относящийся к конкретному продукту.
Система Vyrill анализирует видео и анализирует его текст, аудио и изображения по нескольким фильтрам, включая разнообразие, тематику, вовлеченность и многое другое.По словам Вирилла, эта система является секретом, позволяющим брендам быстро находить лучшие видео. Система также помогает брендам общаться с создателями контента, отображая профили и адреса электронной почты. Генеральный директор
Аджай Бам сказал во время своей презентации, что в настоящее время на платформе компании работает 40 компаний, и ежемесячно их число увеличивается вдвое. Бам, соучредитель и технический директор д-р Барбара Росарио основали компанию в 2015 году и в 2018 году собрали 2,1 миллиона долларов на предварительный посевной раунд. В настоящее время компания собирает средства на посевной раунд в размере 1 доллара.2 миллиона уже собраны.
Посмотреть презентацию Vyrill можно здесь.
Д-р Таддеус Эз | Честерский университет
Публикации журнала
Т. Эз и Р. Энтони, «Надежная автономная архитектура: реализация и эмпирические исследования», Международный журнал достижений в области интеллектуальных систем, Vol. 7 № 1 и 2, 2014, стр. 279 — 301.
Т. Эз, Р. Энтони, К. Уолшоу и А. Сопер, «Общий подход к измерению уровня автономности в адаптивных системах», Международный журнал достижений в интеллектуальных системах, Vol.5 № 3/4, 2012, стр. 553 — 566.
Публикации конференции:
Эшли Вуд и Таддеус Эз, «Эволюция вариантов программ-вымогателей», 20-я Европейская конференция по кибервойне и безопасности (ECCWS), 2020, Англия
Тоёси Ойинлой, Таддеус Эз и Ли Спикман, «На пути к осведомленности киберпользователей: разработка и оценка», 20-я Европейская конференция по кибервойне и безопасности (ECCWS), 2020, Англия
Ли Спикман, Таддеус Эз, Дэвид Бейкер и Самуэль Вайриму, «Снижение риска программ, ориентированных на возврат», 19-я Европейская конференция по кибервойне и безопасности (ECCWS), 2019, Португалия
Мэтью Халл; Фаддей Эз; Ли Спикман, «Контроль за киберугрозой: изучение угрозы, исходящей от киберпреступности, и способность местных правоохранительных органов реагировать», Европейская конференция по разведке и информатике безопасности (EISIC), 2018, Швеция
Вт.Ада и Т. Эз, «Использование социальных сетей на выборах: тематическое исследование # NigeriaDecides2011 и # NigeriaDecides2015», 27-я Национальная конференция NCS, 2018 г., Ибадан, Нигерия,
Т. Эз и Р. Энтони, «Стигмергическая совместимость для автономных систем: управление сложными взаимодействиями в сценариях с несколькими менеджерами», Конференция SAI Computing (SAI), 2016 г., Лондон, Соединенное Королевство.
Т. Эз и Р. Энтони, «Логика мертвой зоны в автономных системах», Конференция IEEE 2014 года по развивающимся и адаптивным интеллектуальным системам: EAIS, 2014, Линц, Австрия.
Т. Эз, Р. Энтони, К. Уолшоу и А. Сопер, «Методология оценки сложных взаимодействий между несколькими автономными менеджерами», Ночная международная конференция по автономным и автономным системам: ICAS 2013, Лиссабон, Португалия.
Т. Эз, Р. Энтони, К. Уолшоу и А. Сопер, «Новая архитектура для надежных автономных систем», Четвертая международная конференция по развивающейся сетевой разведке: EMERGING 2012, Барселона, Испания.
Т. Эз, Р. Энтони, К.Уолшоу и А. Сопер, «Методика измерения уровня автономности самоуправляемых систем», Восьмая международная конференция по автономным и автономным системам: ICAS 2012, Сен-Мартен, Нидерландские Антильские острова.
Т. Эз, Р. Энтони, К. Уолшоу и А. Сопер, «Автономные вычисления в первом десятилетии: тенденции и направление», Восьмая международная конференция по автономным и автономным системам: ICAS 2012, Сен-Мартен, Нидерланды Антильские острова.
Т. Эз, Р. Энтони, К.Уолшоу и А. Сопер, «Проблема валидации автономных и самоуправляемых систем», Седьмая международная конференция по автономным и автономным системам: ICAS 2011, Венеция / Местре, Италия.
Т. Эз и М. Гассемиан, «Сценарий гетерогенных моделей мобильности: анализ производительности зоны бедствия для мобильной специальной сети», Лондонский симпозиум по коммуникациям: LCS, 2010, Университетский колледж Лондона.
Э. Игбесоко, Т. Эз и М. Гассемиан, «Анализ производительности протоколов маршрутизации MANET по различным моделям мобильности», Лондонский симпозиум по коммуникациям: LCS, 2010, Университетский колледж Лондона.